
Data + AI Summitで発表されたセッション「Route to Success: Scalable Routing Agents With Databricks and DSPy」では、Luis Moros氏が複雑化するAIシステムを統合するための実践的なアプローチを解説しました。本記事では、この講演内容を基に、分散したAIシステムを束ね、保守性と拡張性に優れた「ルーティングエージェント」を構築するための技術的な要点と具体的な実装パターンを深掘りします。
AIシステム統合の壁:なぜ今ルーティングエージェントが必要なのか
近年、多くの企業がテキスト生成、要約、Q&Aなど、異なる目的のAIソリューションを個別に開発してきました。しかし、それぞれが独立したエンドポイントやUIで提供されることで、ユーザーは「どのAIに何を聞けばいいのか」がわかりにくくなり、ガバナンスや監査も分散化してしまいます。
こうした課題を解決するのが、ユーザーのリクエストに応じて最適なAIツールやシステムへ自動的に振り分ける「ルーティングエージェント」です。単一の入口を設け、一元的なガバナンスを実現しつつ、ユーザー体験を向上させます。
プロンプト設計の「大きなテキストの壁」

従来のプロンプトエンジニアリングでは、役割設定(Role-play)や背景情報、Few-shot例を重ねるうちに、巨大で複雑なテキストの塊が生まれ、メンテナンス性が著しく低下します。また、特定の言語モデルに過度に最適化された結果、長期的な運用には向かなくなることもあります。
DSPyの構造化アプローチで壁を打破
オープンソースのPythonライブラリ「DSPy」は、プロンプトを構造化されたコンポーネントとしてプログラム的に定義できます。これにより、プロンプトの開発・保守・最適化が格段に容易になります。
さらに、DatabricksはビッグデータとAI向けの統合プラットフォームで、スケーラブルな実行環境やMLflowをはじめとした実験管理・モニタリング機能を提供します。DSPyの柔軟なプログラミングモデルと組み合わせれば、エンタープライズレベルのルーティングエージェントが実現可能です。
DSPyの3つの抽象化コンポーネント
- Signature(シグネチャ)

タスクの指示(Instruction)、入力フィールド、出力フィールドをPythonクラスで明示的に定義。出力フィールドに型を指定することで、LLMの応答をプログラム的に扱いやすい形式に制限できます。
- Prediction Strategy(推論戦略)
DSPy標準のdspy.Predict、dspy.ChainOfThought、dspy.ReActなど、Signatureを変更せずに戦略を切り替え可能。

- Language Model Adapter
DatabricksのFoundation Model APIや他のモデルをバックエンドに差し替えられ、モデル固有のプロンプト形式を自動レンダリング。
これらを分離することで、従来の「大きなテキストの壁」で課題となっていた意図と実装の癒着を防ぎ、保守性の高いAIアプリケーションを構築できます。
ReActパターンを応用したルーティングエージェント

講演では、ReActパターン(Reason + Act)をワンショットのルーティング処理に最適化した構成が紹介されました。
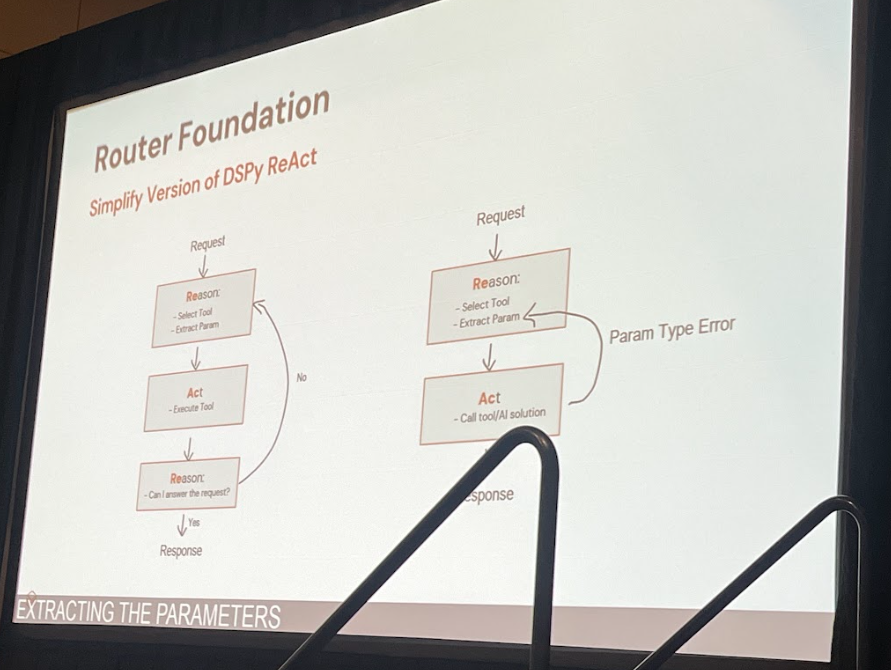
- Reason:ユーザーのリクエストとツールリストから最適なツールを選択し、必要な引数を抽出
- Act:選択されたツールを抽出されたパラメータで実行
- Response:実行結果をユーザーに返却。抽出失敗時には補足質問を行うなど柔軟に対応
この単一ステップ化により、不要な推論ステップを省略し、レイテンシーを削減できます。また、DSPyのモジュールはオープンソースなので、既存モジュールのカスタマイズも容易です。
高精度化への道:Simbaオプティマイザと評価指標

ツール選択精度を高めるため、講演では新しく発表されたオプティマイザ「Simbaオプティマイザ」の活用が紹介されました。Simbaは多数の評価データセット(質問と正解ツール・パラメータのペア)をミニバッチ単位で試行し、評価指標を最も改善する変更のみをプロンプトに反映する手法です。
評価指標には、予測されたツール名とパラメータが正解と完全一致する場合のみスコアを与えるシンプルな関数が例示されました。こうしたオフライン最適化の後、最良のプロンプトを本番環境にデプロイします。
スケール戦略:ベクトル検索で数百のツールをさばく

ツール数が増えると、すべてをプロンプトに含めた際のコンテキストサイズ膨張によるコスト増大やレイテンシー悪化が課題となります。そこで、ベクトル検索機能を活用し、関連性の高い少数のツール候補に絞り込むアプローチが有効です。
- 事前準備:ツール説明文や利用例を表形式でまとめ、テキストをベクトル化してインデックスを作成
- 実行時:リクエスト文をベクトル化し、ベクトル検索で上位n件のツール候補を抽出
- LLMへの入力:絞り込んだ候補リストのみをプロンプトに含める
この手法により、毎回少数の関連ツールから最適なものを選択でき、コストとレイテンシーを抑制しつつスケーラビリティを確保できます。

ステートフルな対話の管理:LakeBaseの活用イメージ
マルチターンの対話では状態管理が必要です。UI側に状態情報を保持させる方法もありますが、ルーターとUIが密結合になりやすいという課題があります。
そこで、講演では新技術「LakeBase」を取り上げ、対話状態をサーバーサイドのKey–Valueストアに永続化する案が示されました。LakeBaseはDatabricks上で提供予定のKey–Value格納サービスとして構想されており、セッションIDをキーに状態を管理できるため、UIとの密結合を避けつつステートフルな対話を実現できます。
実装から得られた3つの重要な教訓
- ツールの責任を明確に分離
- 早期の最適化を避け、まずはSignatureで構造を固める
- MLflow Tracesでプロンプト生成過程を可視化し、デバッグ・運用を強化
まとめ

本番環境での複数クライアント利用実績を持つルーティングエージェントパターンは、DSPyによる構造化プロンプト設計と、Databricksが提供する各種基盤機能を組み合わせることで、高精度・スケーラブル・保守性に優れた分散AI統合システムを実現します。これはエンタープライズ生成AIアプリケーション開発における一つの設計指針と言えるでしょう。