
生成AI(GenAI)の波が押し寄せ、多くの開発現場で「これまでの機械学習(ML)のやり方はもう古いのか?」という声が聞かれるようになりました。しかし、本当にそうでしょうか。DatabricksのSr GenAI Product SpecialistであるDan Pechi氏は、講演「RecSys, Topic Modeling and Agents: Bridging the GenAI-Traditional ML Divide」において、この問いに明確な答えを提示しました。本記事では、同氏の講演内容を基に、従来MLと生成AIが対立するものではなく、むしろ連続した技術であり、両者を統合することでビジネス価値を最大化できるという視点を、具体的なユースケースと共に解説します。
Pechi氏が強調するのは、「生成AIは、既存の課題に対する新しい解決策の一つ」という考え方です。多くの人が生成AIを全く新しい魔法の杖のように捉えがちですが、その実態は、私たちが長年培ってきた機械学習のパラダイムの延長線上にあります。問題は、どちらか一方を選ぶことではなく、両者の長所を理解し、いかにしてシームレスに連携させるかにあります。

統合の鍵を握るプラットフォーム「MLflow」
従来手法と生成AI手法を比較・統合する上で、中心的な役割を果たすのがオープンソースの機械学習プラットフォームであるMLflowです。MLflowは、機械学習のライフサイクル全体を管理するために設計されており、Databricksプラットフォームに深く統合されています。

MLflowの強力な機能は、主に4つのコンポーネントによって支えられています。
- MLflow Tracking: 実験のパラメータ、コードのバージョン、メトリクス、生成されたモデルやファイル(成果物)を記録し、後から比較・可視化することを可能にします。これにより、どの実験がどのような結果をもたらしたかを正確に追跡できます。
- MLflow Projects: コードの実行環境(ライブラリの依存関係など)を定義し、誰でも同じ条件で実験を再現できるようにします。これにより、「私の環境では動いたのに」という問題を解消します。
- MLflow Models: 多様なフレームワーク(scikit-learn, PyTorch, TensorFlowなど)で学習されたモデルを共通のフォーマットでパッケージングし、デプロイを簡素化します。生成AIモデルもこの枠組みで管理できるため、従来モデルと並行して扱うことが容易になります。
- MLflow Registry: 学習済みのモデルを一元的に管理するリポジトリです。モデルのバージョン管理、ステージング(開発、本番など)、承認ワークフローを提供し、モデルガバナンスを強化します。
講演のデモでも示されたように、Databricks上でMLflowを活用することで、従来手法と生成AI手法の実験を並行して行い、それぞれの性能を客観的な指標で比較・評価できます。これにより、私たちは憶測や流行に流されることなく、データに基づいた最適な手法選択へと進むことができるのです。
ユースケース比較:従来手法 vs 生成AI
では、具体的にどのような場面で従来手法と生成AIを比較検討できるのでしょうか。Pechi氏は、3つの代表的なユースケースを挙げて解説しました。

1. トピックモデリング:LDAからTopicGPTへ
文書群から潜在的なトピックを抽出するトピックモデリングは、顧客の声の分析や文書分類など、多くのビジネスで活用されています。

従来、このタスクにはLDA(Latent Dirichlet Allocation)という確率モデルが広く用いられてきました。LDAは、scikit-learnやPySpark MLlibといったライブラリで手軽に実装でき、単語の共起パターンからトピックを推定します。しかし、Pechi氏がデモで示したように、LDAの結果はしばしば「キーワードの羅列」になりがちで、人間が直感的に理解できる「トピック」として解釈するのが難しいという課題がありました。例えば、ある法案に関するテキストデータセットに対してLDAを適用したところ、生成されたトピックは「act, secretary, requires, second, amendment, state」といった単語の集まりとなり、これだけでは内容を把握するのは困難です。
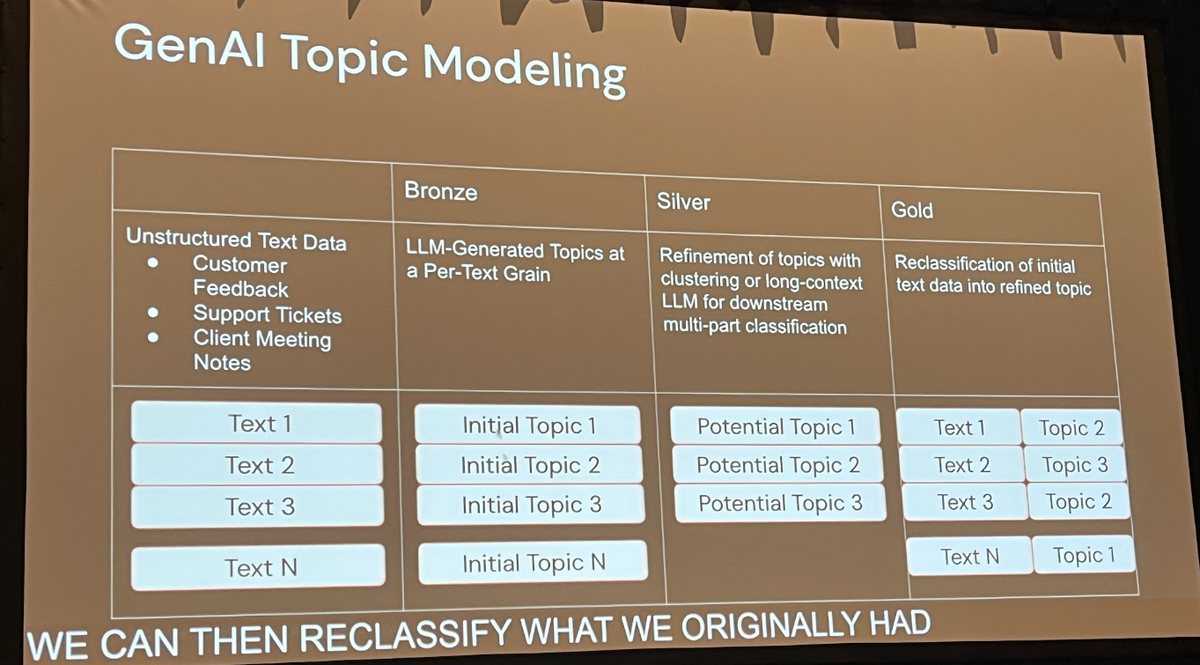
これに対し、生成AIを用いたアプローチ、例えばTopicGPTのような手法では、LLMの高度な言語理解能力を活用します。プロンプトエンジニアリングを通じて、より具体的で一貫性のあるトピック名を生成させることが可能です。講演のデモでは、同じデータセットに対して、生成AIは「Social Security」「Education」「Environment」といった、人間が読んでも分かりやすいトピックを生成しました。

重要なのは、この比較を客観的に行う点です。MLflowの evaluate 関数と「LLM-as-a-judge(評価者としてのLLM)」を用いることで、両アプローチの性能を定量的に比較できます。デモでは、LDAの正解率が約25%だったのに対し、TopicGPTはそれを上回る性能を示しました。これは、生成AIが特定のタスクにおいて従来手法よりも優れた解決策となりうることを示す好例です。
2. 推薦システム:協調フィルタリングとLLMの融合
ECサイトや動画配信サービスに不可欠な推薦システムも、進化の岐路に立っています。

従来の推薦システムでは協調フィルタリングが広く用いられてきました。
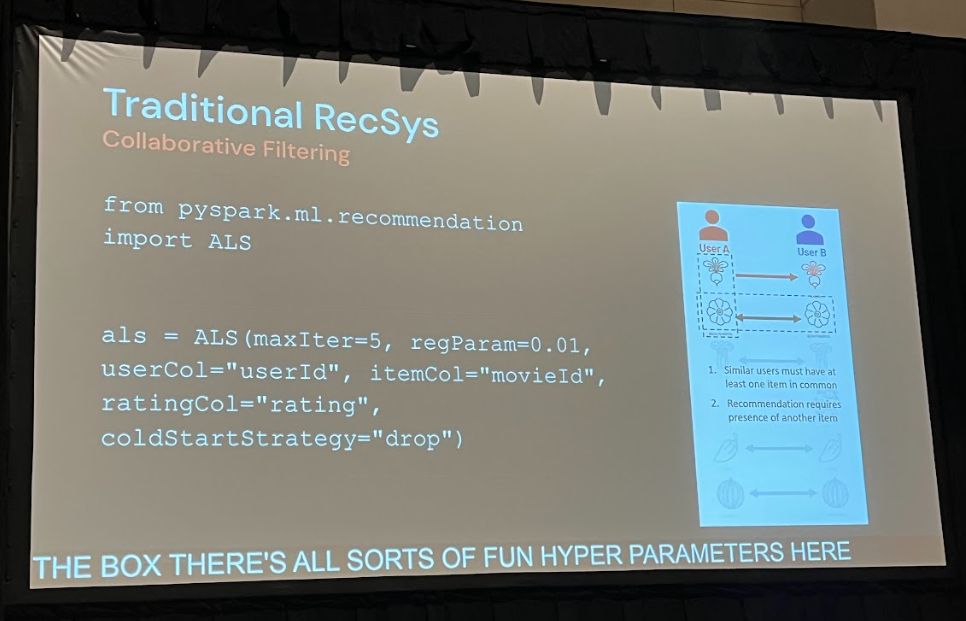
例えば、PySparkのALS(Alternating Least Squares)アルゴリズムなどは、その代表例です。
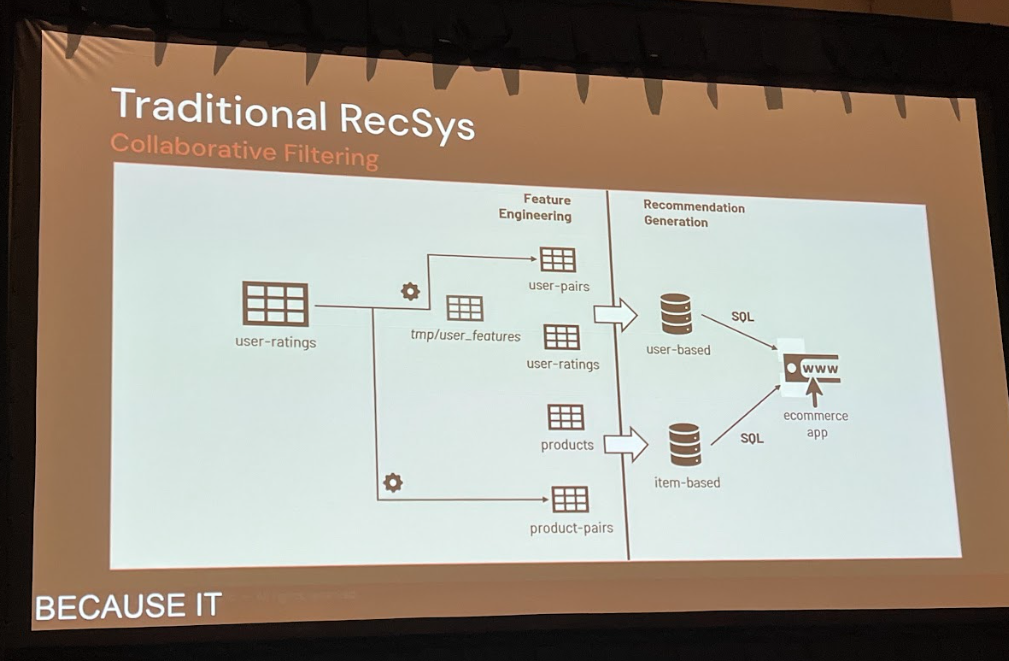
これは、ユーザーの行動履歴(どの商品を閲覧・購入したか)を基に、ユーザーとアイテムをベクトル空間に配置し、その類似度から推薦を行うものです。
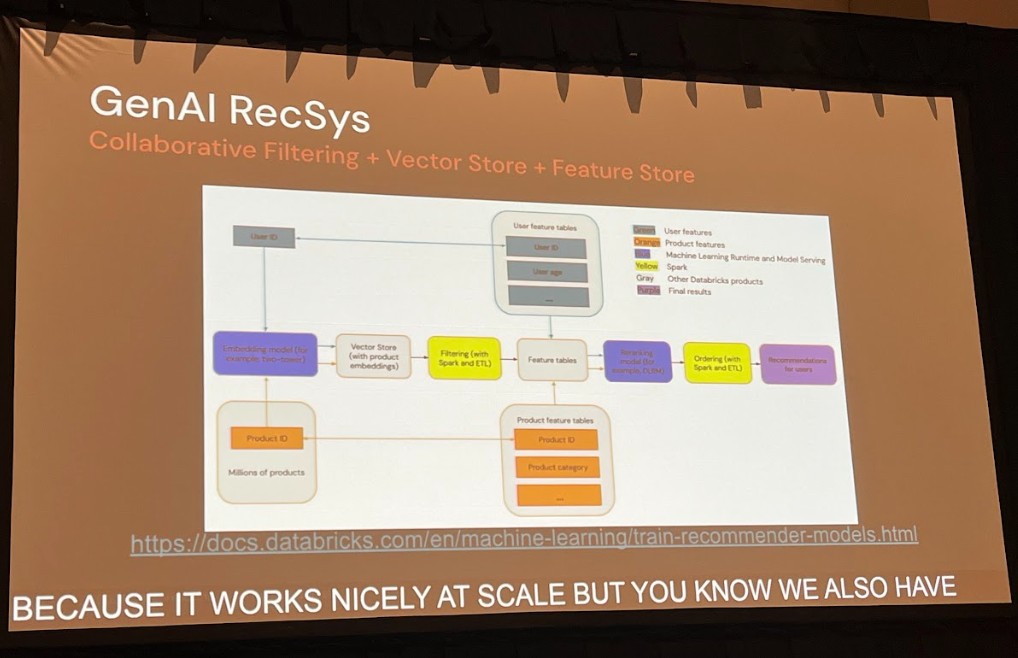
一方で、生成AI、特にLLMを用いた推薦システムは、このベクトル類似性の考え方を継承しつつ、新たな可能性を切り拓きます。例えば、商品の説明文やレビューといった非構造化テキストデータを深く理解し、推薦の文脈に組み込むことができます。「このユーザーは過去に『軽量で持ち運びやすい』という特徴を持つ商品を購入しているから、新商品の『コンパクトなデザイン』を気に入るかもしれない」といった、より高度な推論が可能になります。

Pechi氏が指摘するように、最もシンプルなLLMベースの推薦は、「このユーザーは商品A、B、Cを購入しました。次に何を買う可能性が高いですか?」というプロンプトをLLMに投げることです。さらに洗練されたアプローチとして、従来型の協調フィルタリングで得られた推薦候補を、LLMがユーザーの文脈や商品の自然言語記述を基に最終的に絞り込む、といったハイブリッドな構成も考えられます。ここでも、両者の根底には「ベクトルベースの類似性」という共通概念があり、技術的な連続性が見て取れます。
3. エージェント:強化学習と生成AIの再会

「エージェント」という概念は、生成AIの登場で一気に注目を浴びましたが、そのルーツは古く、1990年代、あるいは1970年代のAI研究にまで遡ります。特に、強化学習(Reinforcement Learning, RL)の分野では、エージェントが環境内で試行錯誤を繰り返し、報酬を最大化するように行動を学習する、というパラダイムが確立されていました。

従来のRLエージェントは、例えば「室温が下がったら暖房を入れる」というサーモスタットのように、明確に定義された状態・行動・報酬の枠組みで動作します。

一方、現代の生成AIエージェントは、LLMを「頭脳」とし、ツール呼び出し(Function Calling)やAPI連携を駆使して、より複雑で動的なタスクを実行します。ユーザーからの曖昧な指示を解釈し、必要な情報を外部ツールで検索し、その結果を基に次の行動を決定する、といった一連の推論と実行のループが特徴です。
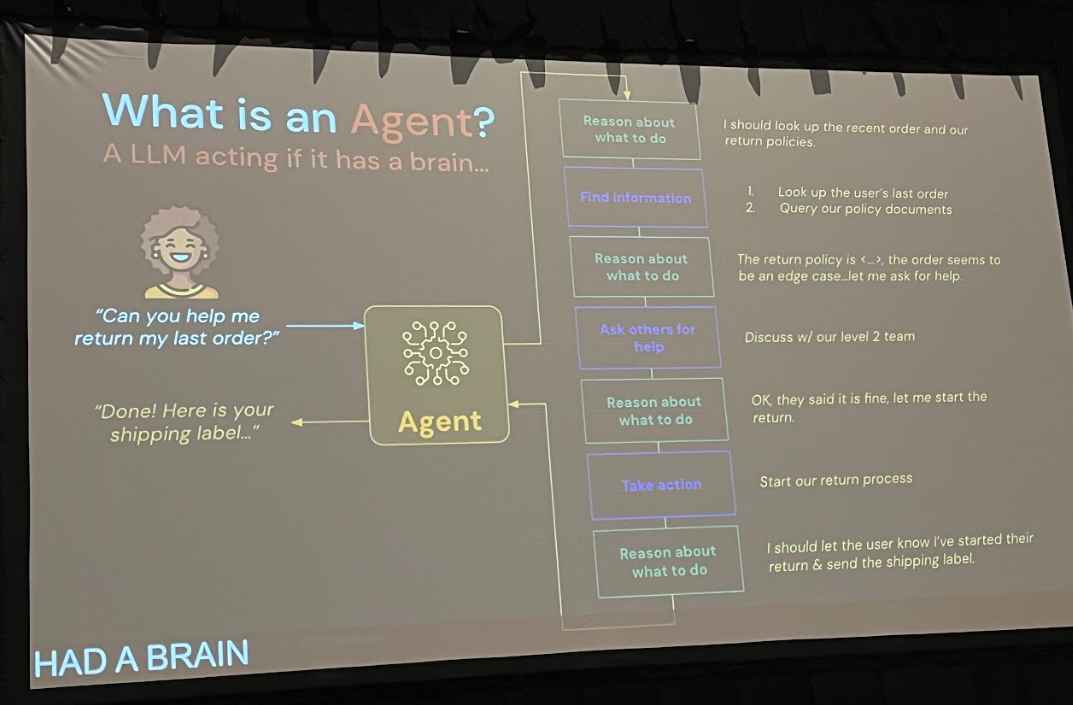
Pechi氏は、この二つのアプローチが再び一つに統合されつつあると指摘します。生成AIエージェントの「タスクが成功したか(例:生成したコードがエラーなく実行できたか)」というフィードバックは、まさしく強化学習における「報酬」に他なりません。このフィードバックループを活用することで、エージェントは自己改善していくことができます。つまり、生成AIは強化学習のフレームワークに見事に収まり、RLの理論が生成AIエージェントの最適化に応用できるのです。
手法選択と実践に向けたガイド
講演を通じて一貫して伝えられたメッセージは、「ビジネス要件とデータに基づいた実験こそが、正しい手法選択の鍵である」ということです。
「LLMで線形回帰を解く」といった極端な例が示すように、すべての問題に生成AIが最適解とは限りません。数値データが中心の時系列予測であれば、ARIMAやProphetのような従来モデルの方がコスト効率も性能も高い場合があります。一方で、非構造化テキストのニュアンスを深く理解する必要があるタスクでは、生成AIが圧倒的な力を発揮するかもしれません。
私たち開発者は、まず解決したいビジネス課題を明確にし、データの特性を理解した上で、複数のアプローチを候補として検討すべきです。そして、MLflowのようなプラットフォーム上でA/BテストやLLM-as-a-judgeといった定量的・定性的な評価を行い、最も効果的なソリューションを見極める必要があります。
拡張的なワークフロー構築へ:DSPyとMCPの可能性
さらに進んだワークフローを構築するために、Pechi氏はDSPyやMCP (Model Context Protocol)といった新しいフレームワークにも言及しました。
- DSPyは、プロンプトのチューニングやモジュール間の連携を自動で最適化するフレームワークです。これにより、手作業のプロンプトエンジニアリングから脱却し、より再現性が高く、自己改善するパイプラインを構築できます。
- MCPは、LLMエージェントと外部ツール間の通信を標準化するプロトコルです。これにより、特定のAPIに縛られることなく、様々なモデルやサービスを柔軟に組み合わせた、拡張性の高いエージェントシステムの構築が容易になります。
これらのツールは、従来MLと生成AIを組み合わせた複雑なワークフローを、より体系的かつ効率的に構築するための強力な武器となるでしょう。
まとめ:分断から統合へ、そして価値創造へ
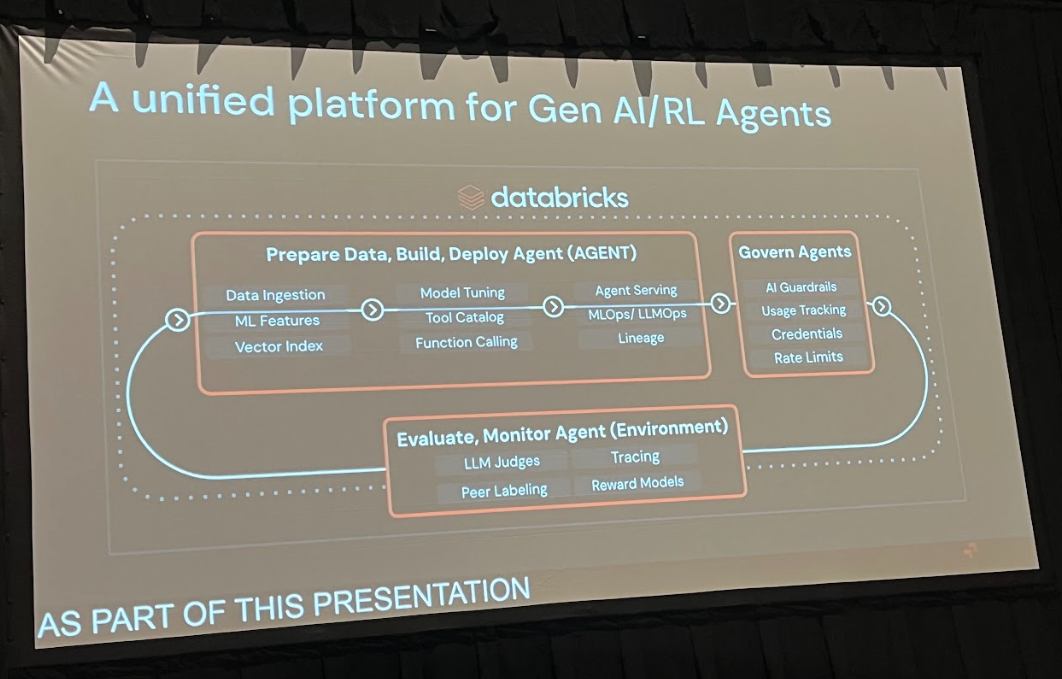
Dan Pechi氏の講演は、生成AIの熱狂の中で私たちが忘れかけていた、機械学習の普遍的な原則を再確認させてくれるものでした。生成AIは断絶ではなく、連続性の先にあります。トピックモデリング、推薦システム、エージェントといった様々な領域で、従来の手法と生成AIの手法は共通の基盤を持ち、互いに補完し合う関係にあります。
私たちの役割は、この二つの世界を分断するのではなく、MLflowのような統一的なプラットフォームの上で両者を統合し、実験を通じてビジネス課題に最適な解を見つけ出すことです。そして、強化学習の考え方を取り入れたフィードバックループを構築することで、AIシステムを継続的に改善し、そのビジネス価値を最大化していくことが、これからのAI開発者に求められる姿と言えるでしょう。
まずは、身の回りの課題を「従来手法」と「生成AI手法」の両面から見つめ直し、小さな実験から始めてみてはいかがでしょうか。その一歩が、分断を乗り越え、新たな価値を創造するきっかけになるはずです。