Data + AI Summitで発表されたByteDanceのソフトウェアエンジニア、Zilong Zhou氏によるセッション「A Unified Solution for Data Management and Model Training With Apache Iceberg and Mosaic Streaming」は、同社が直面する超大規模な機械学習ワークフローの課題と、それを解決するために開発された先進的なソリューションを解き明かすものでした。本記事では、このセッションの内容を基に、ByteDanceがApache Icebergとデータローディングライブラリにどのように着想を得て、統合データ管理・モデル訓練基盤を構築したのかを、客観的な視点から深掘りします。
従来の特徴量ストアが抱えていた根深い課題
ByteDanceのレコメンデーションや広告、検索といった多くのビジネスでは、オフラインの機械学習ワークフローが広く利用されています。しかし、かつての特徴量ストアのアーキテクチャには、いくつかの深刻な課題があったとZhou氏は指摘します。
初期のシステムは、データを完全な行としてHDFSに保存する「行指向ストア」に基づいていました。この設計には、主に3つの問題点がありました。
列プロジェクションが効かない: モデル訓練で数十の素性しか必要ない場合でも、数万にも及ぶ全特徴量を含む行全体を読み込む必要があり、非効率なI/Oが発生していました。
ストレージのオーバーヘッド: 行指向のデータは圧縮効率が悪く、膨大なストレージコストを要します。
特徴量のバックフィルの困難さ: 新しい特徴量を追加したり、既存の特徴量のロジックを修正したりする場合、データセット全体を書き換える必要があり、膨大な計算リソースと時間を消費していました。
これらの課題を解決するため、ByteDanceは次世代の特徴量ストアに求められる要件を整理しました。それは、特定の列だけを効率的に更新できること、データのバージョン管理が容易であること、そしてSparkやFlink(Blink)のようなバッチ・ストリーミング両方のエンジンからアクセスできることでした。
Apache Icebergを基盤に選んだ理由と、残された課題
これらの要件を満たす基盤技術として、ByteDanceが着目したのがオープンテーブルフォーマットであるApache Icebergです。Zhou氏は、Icebergが持つ階層的なメタデータ設計や、SparkとFlink両エンジンのサポート、スナップショットによるバージョン管理やスキーマ進化といった特長を採用の理由として挙げています。

しかし、標準のIcebergだけではByteDanceの要件、特に数万もの特徴量を抱える巨大なテーブルに対する効率的な更新という要求を完全には満たせませんでした。当時のIcebergの更新処理は、Copy-on-WriteやDelete-and-Insertが基本であり、いずれも行全体を書き換える操作でした。特定の列だけを更新したい場合でも、レコード全体を再書き込みする必要があったのです。
この「列レベルの効率的な更新」という最後のピースを埋めるため、ByteDanceはIcebergを独自に拡張したソリューション「Magnus Lake」を開発するに至りました。
Magnus Lake:Icebergを拡張した次世代特徴量ストア
Magnus Lakeは、Icebergを大規模機械学習ワークロード向けに特化させた、いわば強化版Icebergです。現在では5 エクサバイト以上のデータを管理し、社内の特徴量ストアの根幹を支えています。その核心的な設計思想をいくつか見ていきましょう。
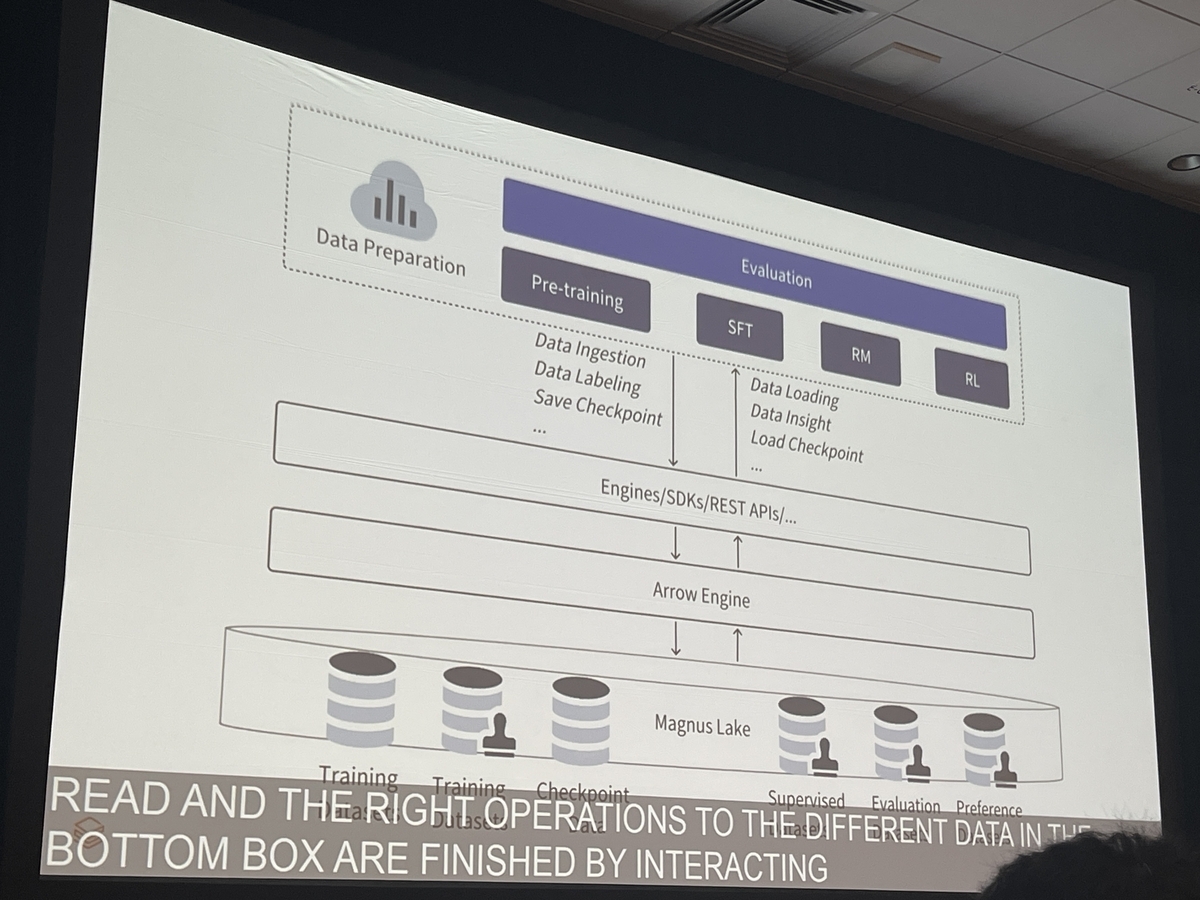
独自実装された列レベル更新とMerge-on-Read
Magnus Lakeの最大の特徴は、効率的な列レベル更新(Column-level Update)を実現している点です。これは、Icebergのデータファイルが一度コミットされると不変(Immutable)であるという特性を活かした、独自のMerge-on-Read戦略に基づいています。
更新したい列のデータだけを差分ファイルとして書き出し、データの読み込み時にベースファイルと差分ファイルをマージして最新の状態を返す仕組みです。これにより、行全体の書き換えを回避し、ストレージとコンピュートリソースを大幅に節約できます。
ユースケースに応じて2種類の更新方法をサポートしています。
- Positional Update: Read-Modify-Write操作向け。読み込み時にレコードの位置情報を活用し、高速更新を実現。
- Equality Update: 既存データに依存しないWrite-Only操作向けで、更新差分ファイルのみを直接書き出せます。

カスタマイズ可能なマージ戦略
ユーザーが独自のマージロジックを実装できる柔軟性も提供。たとえば、行動履歴リストに新しい行動を追加するような「リスト連結」のマージ戦略を定義し、複雑なビジネス要件にも対応可能です。
マルチエンジン・マルチフォーマット対応
SparkやFlinkに加え、自社開発の検索・分析エンジン「Quirkin」や訓練システム「Premise」など、多種多様なエンジンを利用。ファイルフォーマットもParquet、ORC、TFRecordなどをサポートします。
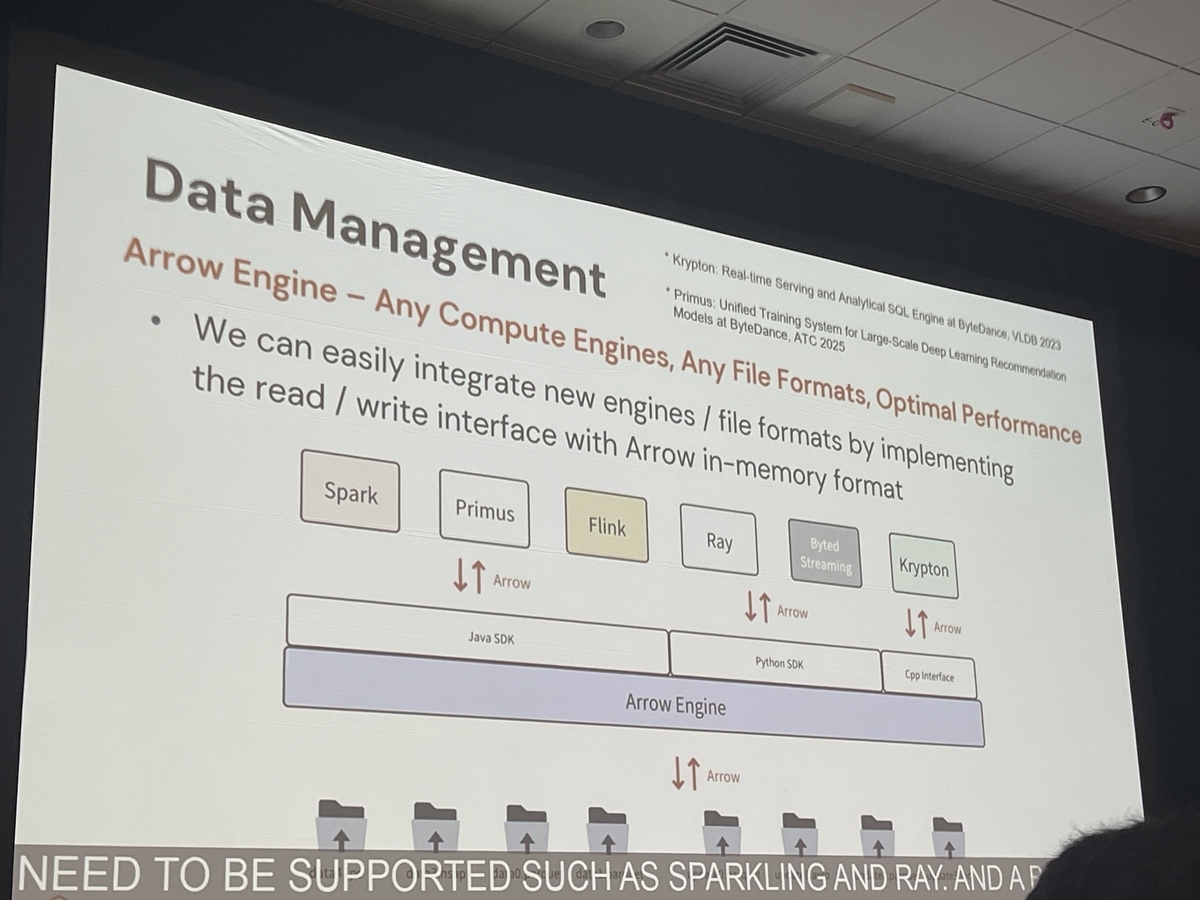
この多様性に対応するため、Magnus LakeはC++製の中間レイヤー「ErrorEngine」を備えています。Apache Arrowベースの抽象インターフェースで読み書きを統一し、新エンジンや新フォーマットの追加を容易にしています。
Magnus Lakeを支える運用設計と成果
読み込み性能を維持するため、バックグラウンドで定期的にCompactionを実行するメンテナンスサービスや、72,000以上のテーブルを管理する独自カタログサービスを運用。RESTful APIでテーブル操作や権限管理を行っています。
Zhou氏によると、Icebergのブランチ機能を活用して特徴量の分析やバックフィルを行うことで、ストレージオーバーヘッドなしに実験環境を分離可能に。結果として、従来の行指向ストアと比べて一部のプロダクトで90%以上のストレージ削減を達成しています。
ByteD Streaming:参考にしたローダーを独自進化
ByteDanceは、オープンソースのデータローディングライブラリにヒントを得て、独自のデータローダー「ByteD Streaming」を開発しました。ペタバイト級データセットを扱う環境では、いくつかの独自最適化が必要だったためです。
ローカルディスクに依存しないシャード読み込み
ByteD Streamingでは、ディスクへの一時保存を前提とせず、シャードをリモートストレージから直接メモリにストリーミング読み込みします。これにより、ディスク容量の制約やI/Oボトルネックを回避できます。

ホットスポット緩和のシーケンス調整
ワーカー間で同一シャードが重複読み込みされる「読み込みホットスポット」を抑制するため、各ワーカーのシャード読み込み開始ポイントをずらし、シーケンシャルに消費していく方式を実装しています。

データセットミキシングとその他の最適化
- 複数のデータソースを組み合わせ、ミニバッチごとに混合比率に応じてサンプリングする機能
- 初期化時のメモリ消費を抑えるLazy Sample ID Generator
- 物理ノード内でサンプルを共有メモリにキャッシュするBroadcast Prefetcher
これらにより、大規模言語モデルの訓練に耐えうる高スループット・低レイテンシを実現しています。
生成AI/LLM訓練に向けたさらなる機能拡張
Magnus Lakeは特徴量ストアにとどまらず、LLMなどの生成AIモデルの訓練基盤としても進化を続けています。
特に、Icebergテーブル上での全文検索・ベクトル検索機能の実装が注目されます。通常はElasticsearchなどにデータを複製しますが、Magnus LakeではIcebergのデータファイルに対応するインデックスを別途管理。検索時にインデックスを参照して必要データだけを取得し、一元管理と高速検索を両立させています。検索エンジンにはRust製ライブラリTantivyを採用しました。

また、テーブルの可視化UIやデータセンター間移行管理、ホットスポット回避のためのレプリカ数動的調整機能など、大規模運用に耐える多彩な機能が整備されています。
まとめと今後の展望
Zilong Zhou氏の講演は、ByteDanceがApache Icebergや既存データローダー(Mosaic Streaming)から得た知見をもとに、独自技術「Magnus Lake」と「ByteD Streaming」を構築し、超大規模MLワークフローを最適化した軌跡を示しています。列レベル更新によるストレージ効率の劇的改善と、高スループットなデータローディングは、同社の機械学習パイプラインを飛躍的に向上させました。
一部機能は今後オープンソースとして公開される可能性があり、データレイクハウスとMLOpsの未来に大きな示唆を与えることでしょう。今後の動向にも引き続き注目していきたいと思います。
