
本記事はAP Tech Blog Week Vol.3のものになります。
はじめに
こんにちは、クラウド事業部の山下です。
生成AIが熱いこともあり、AWSのBedrockに興味があったのですが、実はまだ試せていませんでした。
Bedrockも生成AIも初学者だけど何か試してみたい…!と思い探していたところ、AWS公式のGithubで初心者にも優しそうなワークショップを見つけました。
今回はこちらのワークショップを参考にしながら、Bedrock+Claude 3 でのRAG構築を試してみたいと思います。
catalog.us-east-1.prod.workshops.aws
どんなひとに読んで欲しい
- AWSのBedrockに興味があるひと、試してみたいひと
用語の整理
RAGとは
Retrieval-Augmented Generation(検索拡張生成) の略。
LLMに対して問合せを行い回答を生成する前に、ナレッジベースなどでの情報検索を行うことで回答精度を向上させる。Knowledge Bases for Amazon Bedrockとは
RAGに必要なナレッジベースを簡単に構築できる。Embeddingsとは
内容理解難しく自分ではうまく説明が考えられなかったのですが、AWSの方が書かれた記事でわかりやすく説明されていたのでそちらを引用させていただきます。

引用させていただいた記事はこちらです。Amazon Titan Text Embeddings V2 とは
Bedrockで利用可能なAmazonが提供しているテキスト埋め込みモデルのひとつです。
前提

※ワークショップのページ内より引用。
今回構築する構成は上記のようなイメージです。
Cloud9のプログラムからナレッジベースを呼び出し、ナレッジベースがデータの検索や回答の生成を行います。
- Bedrock Claude 3を呼び出すプログラム実行はCloud9環境で行う。
- 事前にCloud9環境を作成し、Pythonのライブラリであるboto3とstreamlitをインストールしておく。
- データソースを格納しておくS3バケットは同じリージョンに作成しておく。
手順
モデルの追加
今回の検証で使用するモデルを追加します。
Bedrockコンソールのメニューから「モデルアクセス」を選択し、「Modify model access」を押下します。
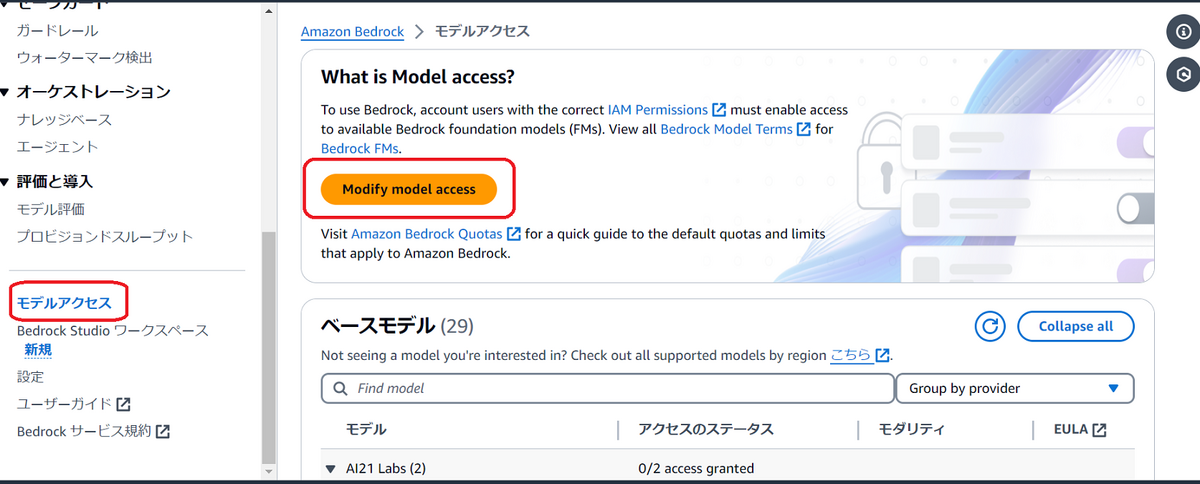 「Titan Text Embeddings V2 」「Claude 3 Sonnet」「Claude 3 Haiku」にチェックを入れて追加します。
「Titan Text Embeddings V2 」「Claude 3 Sonnet」「Claude 3 Haiku」にチェックを入れて追加します。
データソースの作成
今回はS3に格納するデータソースもChat GPTで作成してみました。
架空の会社を設立する体で規則の案を考えてもらいました。

株式会社てすと 就業規則
第1条 目的
この就業規則は、株式会社てすと(以下「会社」という。)における従業員の労働条件および行動規範を定め、円滑な企業運営を図ることを目的とする。
第2条 適用範囲
この就業規則は、会社の全従業員に適用される。
第3条 勤務時間
勤務時間は原則として午前9時から午後6時までとし、休憩時間を除いた労働時間は1日8時間とする。
休憩時間は午前11時から午後2時の間の1時間とする。ただし、業務の状況に応じて、管理職の指示に従い勤務時間および休憩時間の変更が行われる場合がある。
第4条 賃金・給与
賃金・給与は基本給およびその他の手当で構成され、支給日は毎月末日とする。
賃金・給与は業績や能力に応じて個別に決定される。
第5条 休日・休暇
週休2日制を原則とし、土曜日・日曜日を休日とする。ただし、業務の都合により変更される場合がある。
年次有給休暇は法令に基づき、入社初年度から10日付与される。
特別休暇やその他の休暇については、会社の定める規定に従う。
第6条 秘密保持義務
従業員は、会社の業務上の秘密や個人情報を漏洩または不正使用しない義務がある。
退職後も秘密保持義務は継続するものとする。
第7条 禁止事項
従業員は、会社の利益に反する行為や法律違反行為を行ってはならない。
その他、会社が定める禁止事項に違反する行為を行ってはならない。
第8条 制定および改定
この就業規則は、制定時および改定時に全従業員への周知を行い、役員会での決議を経て発効する。改定が必要な場合は、事情に応じて定期的に見直す。
雑なプロンプトでしたが、それっぽい規則を考えてくれました。
こちらの内容をpdfで保存し、事前に準備しておいたS3バケットに格納します。
ナレッジベースの作成
次にナレッジベースを作成していきます。
Bedrockコンソールのメニューから「オーケストレーション」⇒「ナレッジベース」を選択し、「ナレッジベースを作成」を押下します。
任意のナレッジベース名を入力し、IAMロールは新規作成を選んで「次へ」を押下します。
データソース設定では任意のデータソース名を入力し、「S3を参照」から先ほどデータソースを格納したS3バケットを選択して「次へ」進みます。
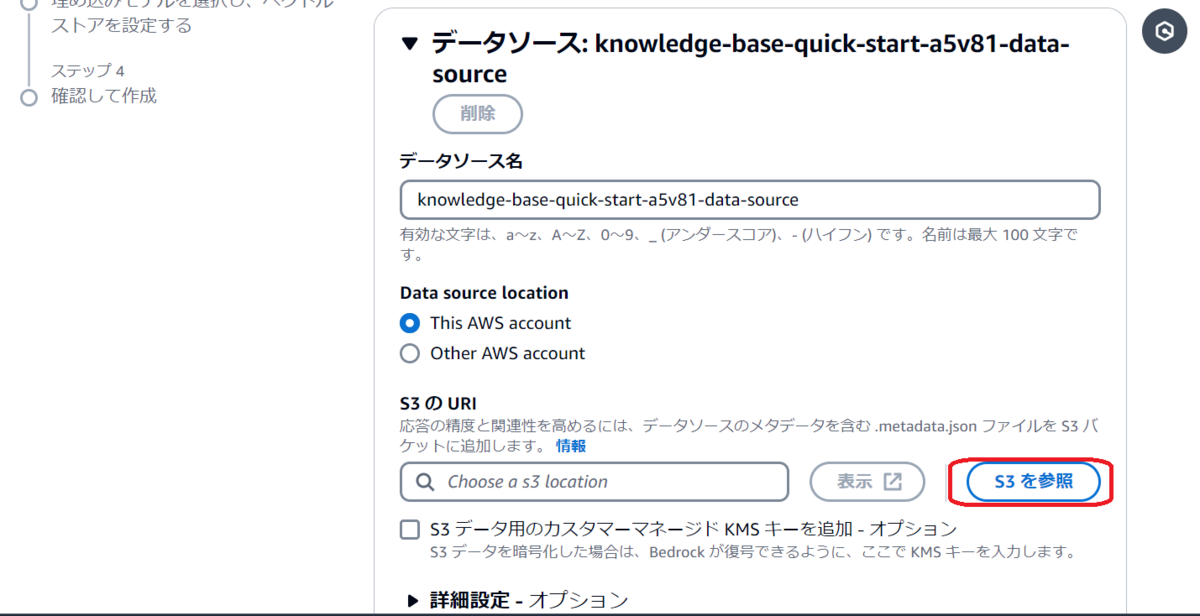
埋め込みモデルの選択では「Titan Text Embeddings V2」を選び、今回他項目は初期値のまま「ナレッジベースを作成」を押下します。
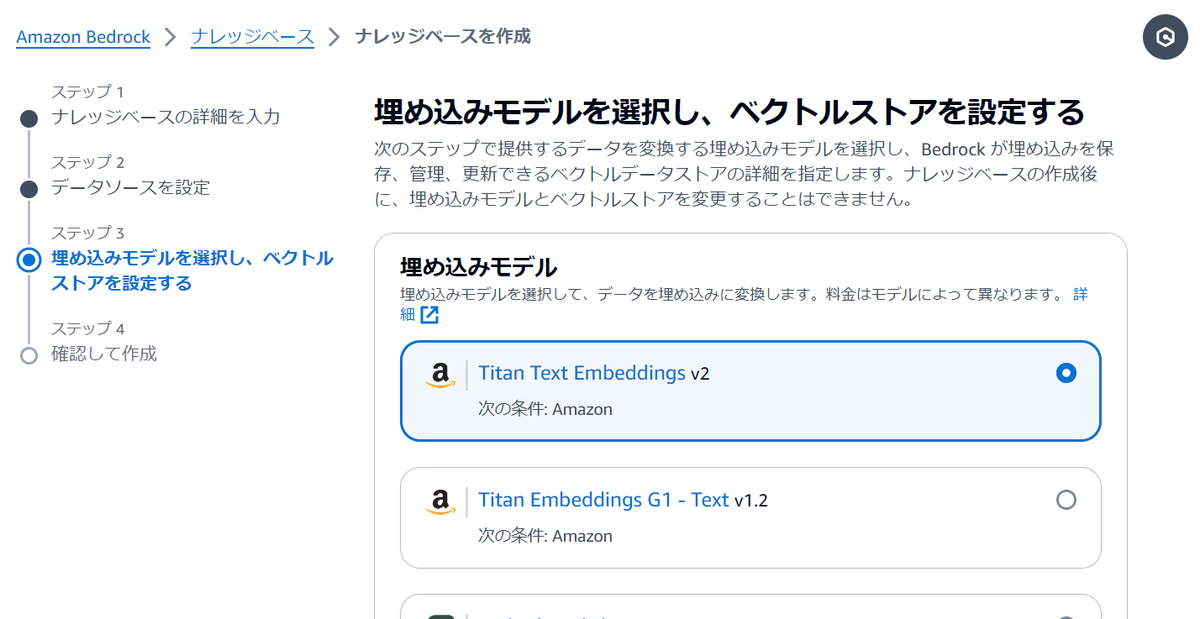
しばらく待つと作成が完了します。
次のRAG構築においてナレッジベースIDが必要になるためコピーしておきます。
画面上部の「Go to data sources」を押下します。
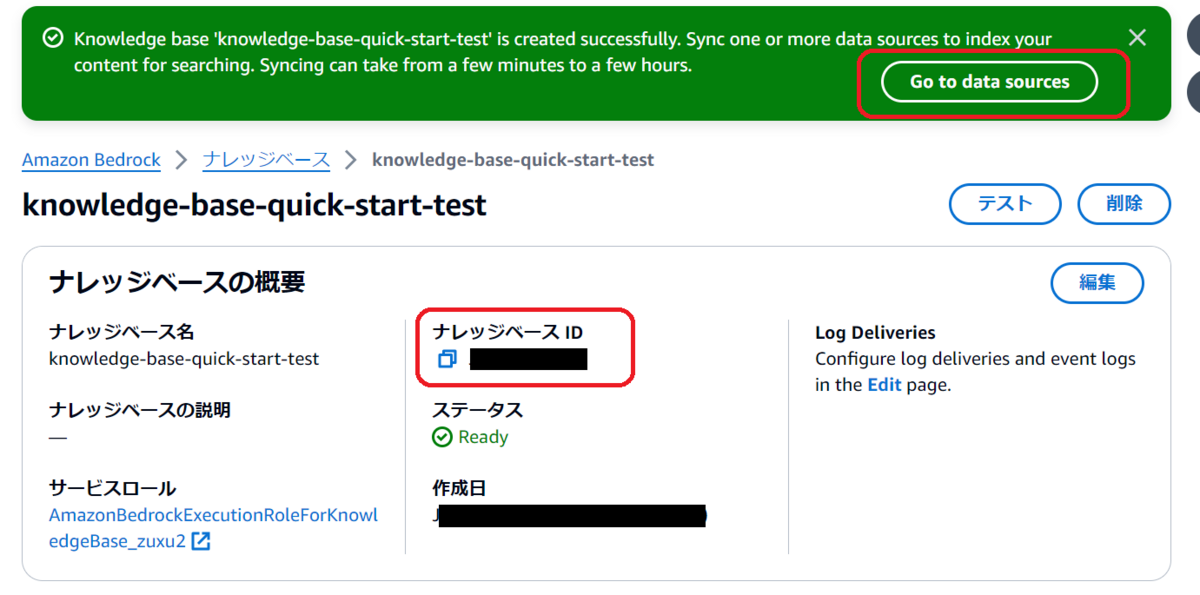
作成したデータソースを選択し、「同期」を押下します。
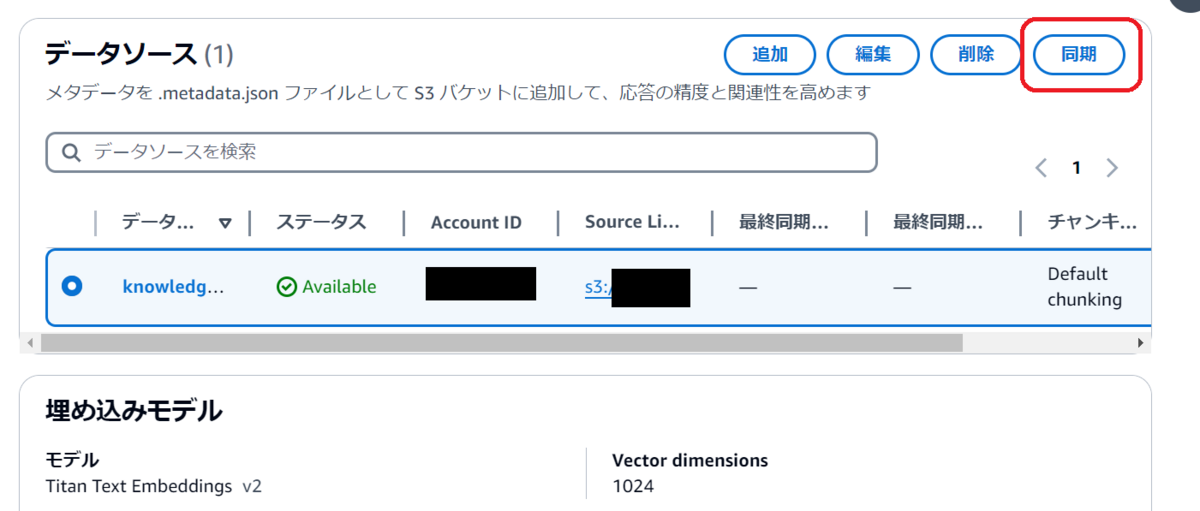
同期が完了したら次の工程に進みます。
RAG構築
ナレッジベースを呼び出すRAGのプログラムは、事前に準備してあるCloud9上で作成します。
ワークショップで準備されているプログラムを活用させていただきました。
詳細は割愛いたしますがプログラムは以下のような構成になっています。
・問合せ画面のパーツ配置
・送信を押下されたら、問合せ画面上で選択されたモデルのモデルidに切り替える
・ナレッジベースの検索と回答を生成するLLMの呼び出し
・生成された回答の出力
プログラム内の「knowledgeBaseId」に前工程で作成&コピー済みのナレッジベースIDを記載し、「test.py」など任意のファイル名で保存します。
Cloud9のターミナルで下記を入力してstreamlitを起動します。
python3 -m streamlit run test.py --server.port 8080
Cloud9上部の「Preview」から「Preview Running Application」を選んで問合せ画面を表示します。
動作確認
最後に問合せを行いどのような回答が返ってくるのか確認してみます。
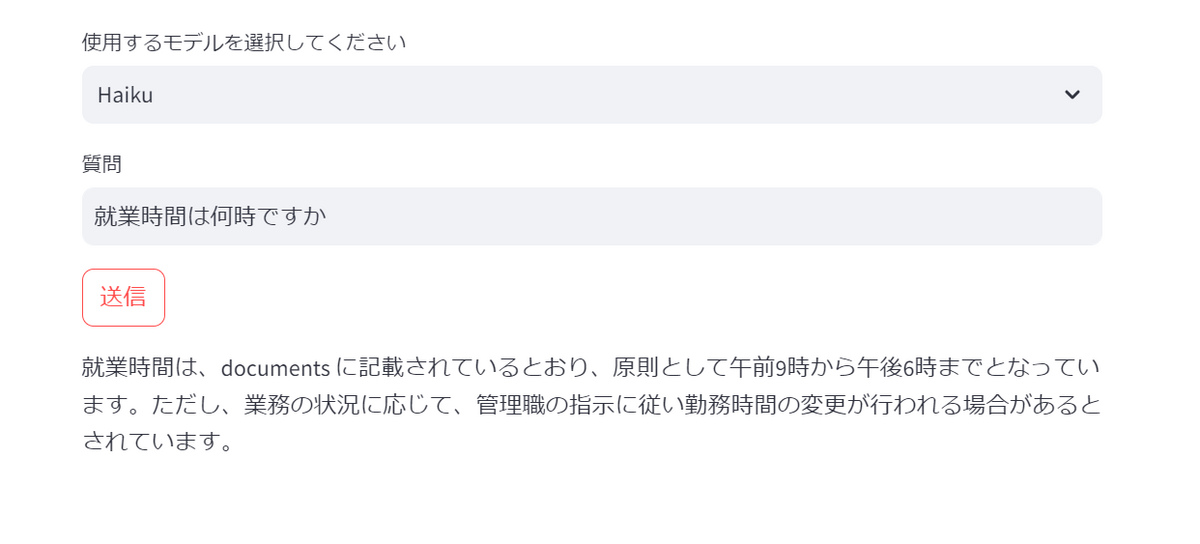
まずは「就業時間は何時ですか」と聞いてみます。
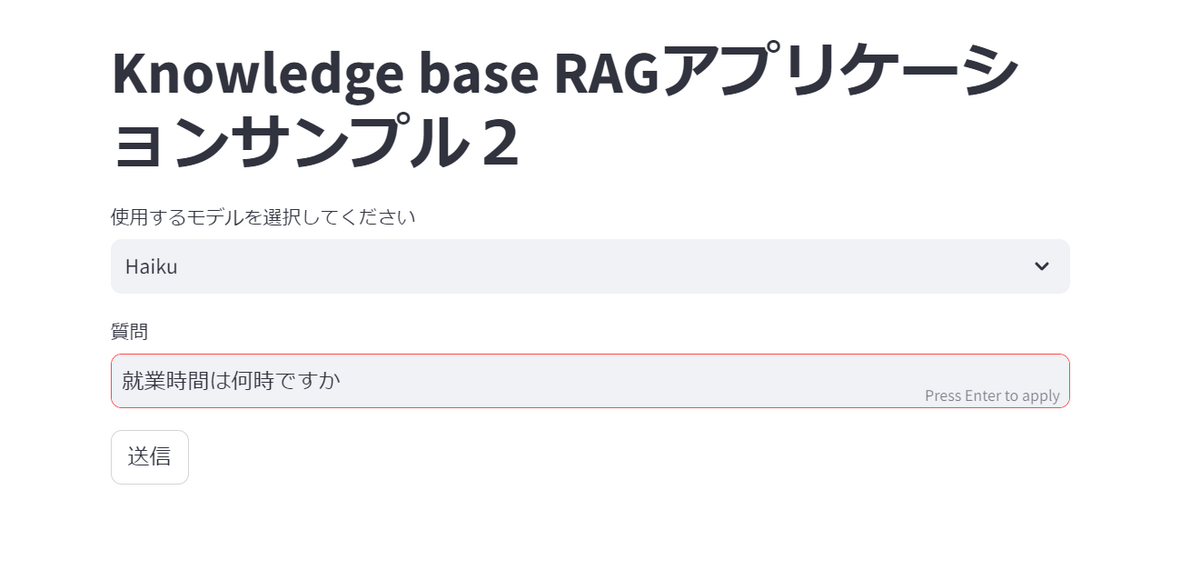
ナレッジベースに設定しているデータソースのドキュメントから検索を行い「就業時間は何時ですか」という質問に対する回答をばっちり返してくれました。
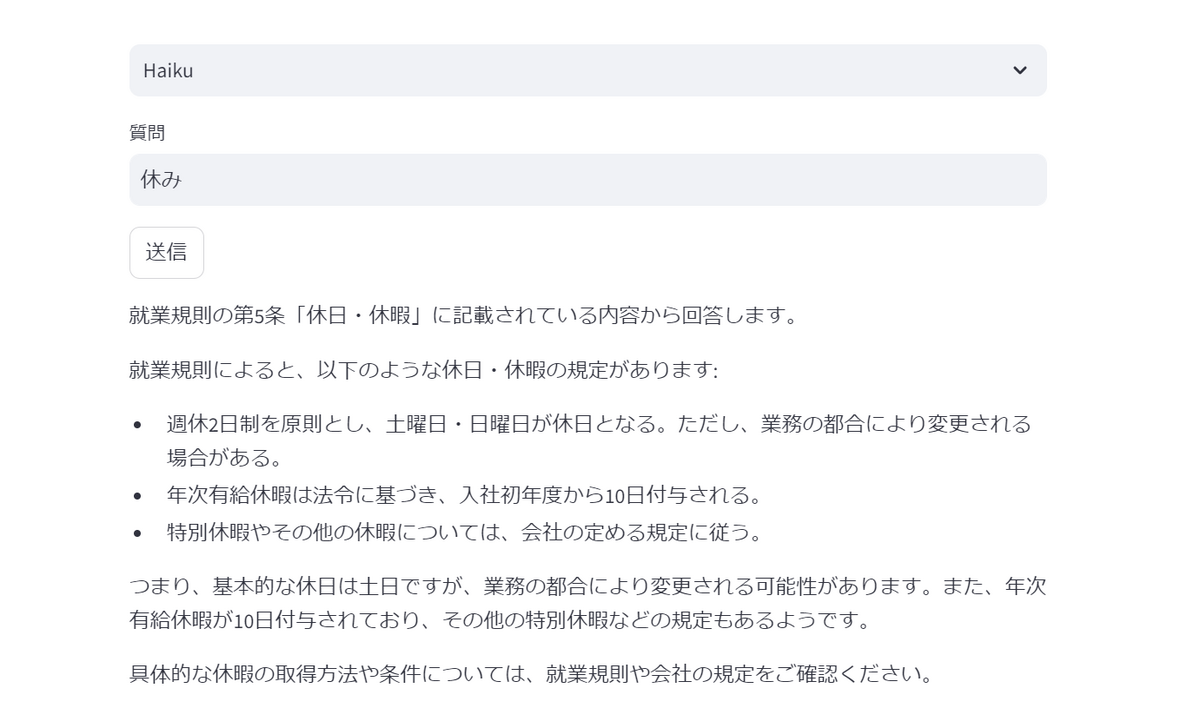
次は先ほどよりも質問の仕方を雑にしてみてどんな回答が返ってくるか確認してみます。
問合せ画面に「休み」と単語だけ入力して送信ボタンを押してみました。
単語のみの問合せでしたが、こちらもデータソースのドキュメントから検索を行い回答をばっちり返してくれました。
最後にデータソースのドキュメントの中に記載されていないことを質問してみてどんな回答が返ってくるか確認します。
就業規則案ドキュメントに記載されていない賞与について質問しました。
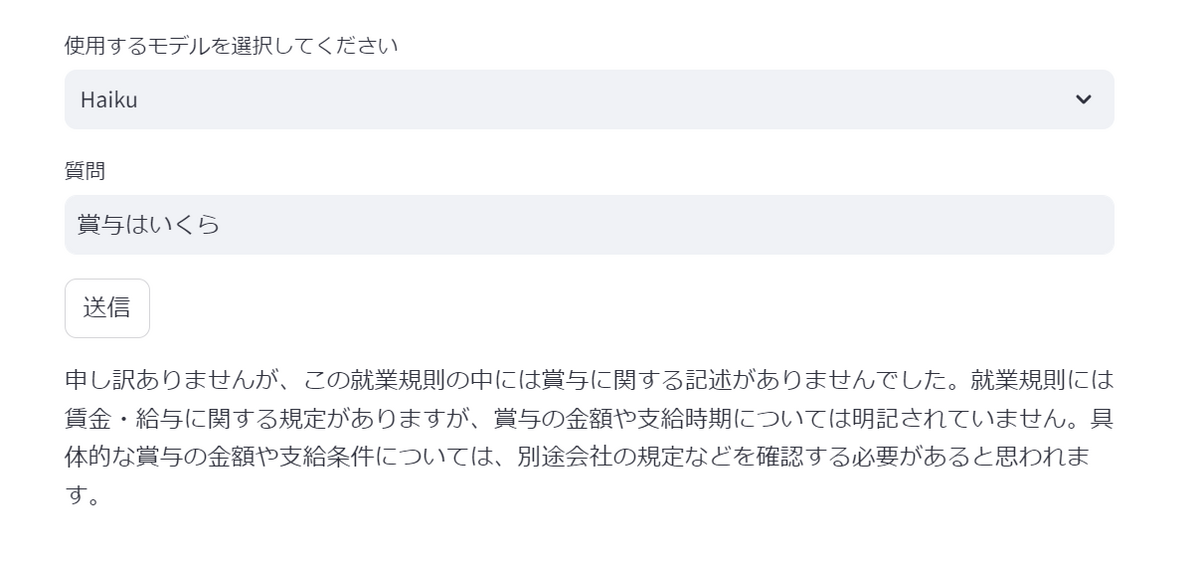
検索したところ質問に対応するナレッジがなかったという事実だけでなく、給与に関する記載はあるが賞与について明示されていないこと&別の規定を確認するようサジェストまでしてくれました。
おわりに
今回初めてBedrockに触れてみましたが、わかりやすいワークショップのおかげもありRAGの構築を試すことができました。
本当はもう少し内容を踏み込んでいきたかったのですが、時間も足りなくなってしまったため、今回はこのような内容となりました。
今回紹介した内容をうまく活用できれば、会社の規則や手続き関連の問合せbotのようなものを作ったり、業務ナレッジを見つけやすくしたりするシステム・仕組みづくりもできるのでは?と思いました。
今後色々なことに活用していけそうな内容の概要を少しでも学ぶことができてよかったです。
最後までお読みいただきありがとうございました。
お知らせ
APCはAWS Advanced Tier Services(アドバンストティアサービスパートナー)認定を受けております。
その中で私達クラウド事業部はAWSなどのクラウド技術を活用したSI/SESのご支援をしております。
www.ap-com.co.jp
https://www.ap-com.co.jp/service/utilize-aws/
また、一緒に働いていただける仲間も募集中です!
今年もまだまだ組織規模拡大中なので、ご興味持っていただけましたらぜひお声がけください。