セッションの概要
LlamaIndexの共同創業者であるJerryが本セミナーを開催しました。この90分間のセミナーでは、参加者はJupyterノートブックを使用してRetrieval-Augmented Generation(RAG)システムの構築プロセスを学びました。RAG(検索拡張ジェネレーション)は、ユーザーが知識ベースにタスクやクエリを入力し、その答えを効率的に取り出すシステムです。RAGは具体的な質問から複雑な問題まで幅広く対応し、知識アシスタントの基礎を形成します。LlamaIndexは、非構造化データのパース、取り込み、処理を最適化することでデータ品質を向上させ、RAGの効果を最大化します。大規模言語モデル(LLM)と統合し、データのパースやインデックス作成を最適化することで、精度の高い情報取得と新たなコンテンツ生成が可能になります。また、継続的な改善が奨励され、最新技術を取り入れた能動型システムの開発を促進します。
セッションの詳細
RAGパイプラインの構築と強化
検索拡張ジェネレーション(RAG)は、多様なアプリケーションの構築を可能にする革新的な概念です。このセクションでは、その基本原則を紹介し、ユーザーがタスクや問い合わせを知識ベースに入力して答えを取り出すプロセスを示します。RAGの理解は、質問のタイプや特定性に基づいて拡大することができます。
ユーザーが提出するタスクやクエリは、「特定の時点でのXとは何ですか?」のような具体的な質問から、大量の計画やタスク分解を必要とし、通常は複数のサブ問題を含むより複雑な問題まで幅広くカバーします。RAGの重要な側面のひとつは、ユーザーからのさまざまな種類のタスクや質問を効率的に処理するためのインターフェースを提供することです。
これらの概念は、「知識アシスタント」を作成するための基礎を形成します。質問がどれほど具体的か一般的かにかかわらず、適切な手法を実装することで、ユーザーはより効率的かつ自信を持って知識を得ることができます。
次のセクションでは、具体的にRAGパイプラインを構築し強化する方法について深掘りします。この革新的な技術を利用して複雑な問題を解決し、使いやすさを向上させる方法について、詳細を学ぶのはしばらくお待ちください。
複雑な文書上でのRAGの構築における高度な技術とツール
大規模言語モデル(Large Language Models、LLM)は、ユーザーがコンテンツを検索し、それと対話する方法、さらには新しいコンテンツを生成する方法を革新しています。最近では、RAG周辺のスタックやツールキットが登場し、ユーザーがアプリケーションを構築することを可能にしています。
しかし、単純な検索や質問応答を超えて、より一般的なコンテクストに基づいた研究支援を構築するには、RAGだけでは不足する場合があります。それでは、単純な検索や質問応答を超えて、より一般的なコンテクストを考慮に入れた研究支援を構築するにはどうすれば良いでしょうか。
本セッションでは、その解決策として2つの焦点を当てています。一つ目はデータ品質の向上で、非構造化データのパース、取り込み、そして処理の各段階で実施される手法を詳述します。このような非構造化データには大量の情報が含まれており、その価値を最大化するためには品質の向上が必要不可欠です。
非構造化データの品質を向上させるためには、データのパース、取り込み、処理の各ステップが重要で、特に非構造化データの取り扱いには注意が必要です。これらの影響を理解し、最適なストレージシステムを選択しデータを管理することで、より洗練されたRAGシステムを構築することが可能です。
RAGの理解
本質的に、RAGはLLMsをユーザーインターフェースや自動生成インターフェースなどの複雑なバックエンドシステムと統合します。RAGは、文書の取得と生成を効率的に組み合わせることで、ユーザーが必要な情報を高精度で抽出することを可能にします。
高度な能動型システムの探索
RAGは高度な能動型システムの開発を促進します。YAMLベースの設定スキーマがこれらのシステムを構築する際に使用され、ユーザーがRAGを特定のニーズに合わせて微調整や適応させることが可能になります。
このシステムは、文書全体に散らばる情報を整理し簡略化し、理解しやすくします。これにより、情報取得と新たなコンテンツ生成の効果性が向上します。
データ処理とインデックス作成の深層探索
大量の言語モデル(LLM)を扱う際に多くのユーザーが直面する課題があります。データのパース (parse)と取り込みを適切に行う方法に関する課題です。このトピックは、標準的なデータ処理手法であるETL(Extraction、Transformation、Load)の新たな解釈が必要なRAGで作業するときに特に重要になります。
新形式のETL
RAGにLLMを使用する場合、大量のデータ(例えば、PDFを大量にダンプする)を取り込んで、データの複雑性に関係なく有用な出力を期待することは現実的ではありません。使用しているLLMがオープンソースであるか商用製品であるかに関係なく、データが適切に処理され、インデックス化されることが極めて重要です。
データのパースとインデックス作成の必要性
適切なデータパースとインデックス作成は、データから必要な情報を迅速に抽出することを促進し、LLMをより効果的に動作させます。このセクションでは、これらのプロセスを改善するための具体的な方法が議論され、データのパースとインデックス作成がLLMとRAGの組み合わせを使用して新たな課題に直面するときに不可欠になることを強調します。
データ品質の向上
不整然とした、或いは生のデータを扱うことは、フォーマットや品質が大きく異なるために難しいタスクとなり得ます。しかし、「データパーシング (parsing)」、「データ取り込み」、「データ処理」というステージを経て、それは構造化された形式に変換可能です。これらのステップを一緒に働かせることにより、データを洗練させ、解析に適した状態にすることができます。
データ分析と処理の活用
データ品質が向上したら、次のステップはそのデータを分析し処理することです。このセッションで議論されたようなRetrieval-Augmented Generation(RAG)システムをこの目的に利用できます。RAGは、適切な回答を提供し、標準的な検索と問い合わせシステムを強化する高速かつ効率的なメカニズムとして設計されています。
しかしながら、RAGは広範な問い合わせやタスクに直面すると制約を見せます。これは実際にはチャレンジングなタスクであり、更に詳細なレベルのデータの理解とパーシングが必要です。適切なツールと技術、データ分析と処理を用いれば、これは可能にできます。
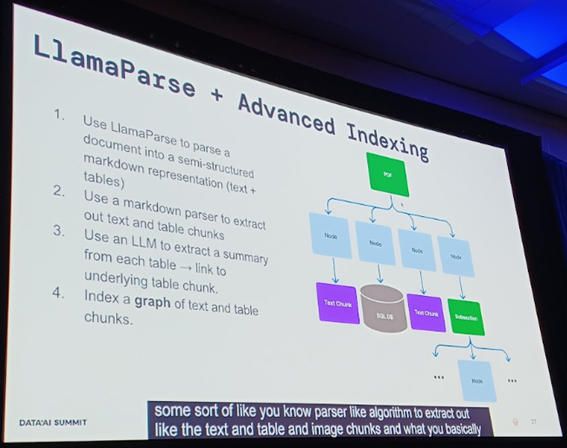
Llama Parseと高度なインデキシング
このセクションでは、Llama Parseと高度なインデキシングについて触れ、大規模言語モデル(LLM)がユーザーコンテンツの検索、相互作用、作成方法にどのように革新的な影響をもたらしているか、また、新しいアプリケーション開発がデータ取得を強化した生成(RAG)を使用してどのように可能になっているかについて詳述します。
データの表示方法
私たちが提供するツール、Llama Parseを使用することで、データのブロックは画像だけでなく、ドキュメントやテキストとしても表現できます。これにより、データはマルチモーダル形式とテキストベースの形式の両方で表現できます。しかし、現時点では、画像ベースのブロック分割は大変なコストとレイテンシーとのトレードオフをもたらします。しかし、この問題も時間とともに、モデルが改善されて高速化することで解決可能と予想されます。
インデキシングの一般的な原則
近年では、生のテキストを直接埋め込みモデルに供給し、何らかのベクトル表現を得るというのが一般的な方法となっています。この原則はLlama Parseと組み合わせると、特に効果を発揮することが示されています。
新しいアプリケーションの開発や、既存の、または将来改良されるモデルの使用において、これらの知識は必須であり、重要です。
データクエリにおける課題と可能性の特定
データに対して何を問いかけるかの多様なクエリと、その中に潜在する可能性ある問題を特定することから議論が始まります。予想通り、データに向けられる質問の範囲は広大で、基本的なRAGパイプラインの中にはシナリオの問題がいくつか特定されました。
例えば、契約書や財務報告書のような広範なドキュメントから要約を作成するタスクを考えてみてください。このような集約的な情報ソースから必要な要約を集めるのは容易なことではありません。
もう一つの課題は、ここではドキュメントAとBと呼ばれる二つの類似したドキュメントの比較です。この比較は、2つの履歴書や財務報告書を扱う際に特に重要となり、基本的なRAGパイプラインが取り扱うのは問題となる領域です。
クエリ複雑性とエージェント型ワークフローの増幅
これらの複雑な問題に取り組むことで、データにおけるクエリの複雑性が増大し、結果的にエージェント型のワークフローが強化されます。強化されたエージェント型のワークフローは、結果的に、より多くの情報を含むデータの賢い利用を促進します。
この改善は、データ分析の現実的な問題を解決するためだけでなく、新しい知識と革新的なアイデアの生成に道を開く。
したがって、クエリの複雑性を高め、エージェント型ワークフローの利用を最適化することは、大量のテキストデータを成功裏に操作するための重要なステップとして、強調されるべきものです。
継続的改善の強調
これらの先進的な能動型システムの特徴的な点は、継続的な改善が推奨されていることです。システム開発は決して静止しておらず、常に進化しているため、最新の技術を組み込み、システムを最新の状態に保ち、現在の機能を超えて押し進めることは当然となります。
基本的なデータ分析手法から先進的な手法までを用いて、システムはユーザーの要求を満たし、効率的かつ効果的に新しいコンテンツを生成するために進化し続けます。RAGの機能を理解し、活用することがこのプロセスの鍵となります。
まとめ
本章では、大規模言語モデルの応用について深掘りし、能動型システムの構築とこれらのシステムにおける継続的な改善の重要性について議論しました。RAGの可能性とそれを実用的に利用する方法に特に注意を払いました。
この知識は、新しいコンテンツの探索や作成、ユーザーとの対話のためのガイドラインとなります。新たな技術が継続的に現れる中、私たちの境界は常に拡張されています。最新の開発に常に追いつき、価値ある情報を発見する旅を続けていきます。

Databricks Data + AI Summit(DAIS)2024の会場からセッション内容や様子をお伝えする特設サイトをご用意しました!DAIS2024期間中は毎日更新予定ですので、ぜひご覧ください。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。