トヨタの[コネクテッドカー戦略:Databricksで実現するデータ価値最大化とプライバシー保護の両立
 自動車がインターネットと常時接続される「コネクテッドカー」。その膨大なデータは、私たちの移動をより安全で快適なものに変える可能性を秘めています。一方で、GDPR(EU一般データ保護規則)に代表されるように、世界中で個人データ保護の規制は年々強化されており、企業はデータ活用とプライバシー保護という二つの大きな課題に直面しています。
自動車がインターネットと常時接続される「コネクテッドカー」。その膨大なデータは、私たちの移動をより安全で快適なものに変える可能性を秘めています。一方で、GDPR(EU一般データ保護規則)に代表されるように、世界中で個人データ保護の規制は年々強化されており、企業はデータ活用とプライバシー保護という二つの大きな課題に直面しています。
この難題に、自動車業界の巨人はどう立ち向かっているのでしょうか。本記事では、Data + AI Summitで発表されたトヨタ自動車株式会社の大栄義博氏とDatabricksの倉光怜氏による講演 「Toyota: Maximizing Business Value and Ensuring Data Privacy with Databricks in Connected Vehicles」の内容を基に、トヨタのコネクテッドカーデータ基盤における挑戦と、その解決策を紐解いていきます。
20年間の歩みとペタバイト級データの課題
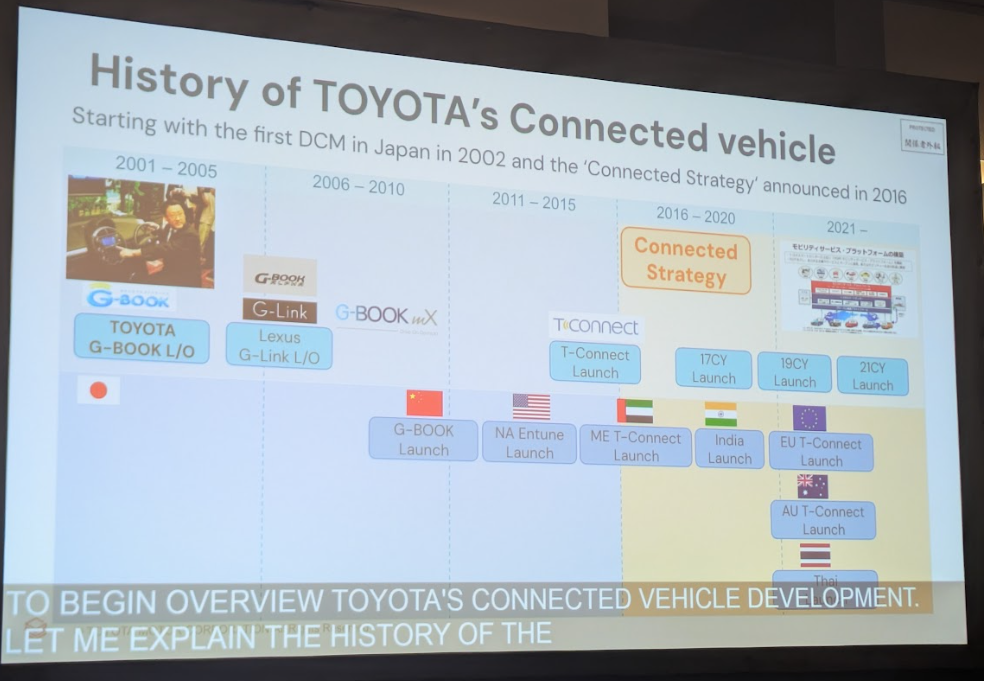
トヨタのコネクテッドカーへの取り組みは、2002年に開始されたテレマティクスサービス「G-BOOK」にまで遡ります。2016年には「コネクティッド戦略」を発表し、すべての車両に通信モジュール(DCM)を搭載する方針を打ち出しました。その結果、現在では日本で300万台以上、米国では1000万台以上ものコネクティッドカーが走行しています。

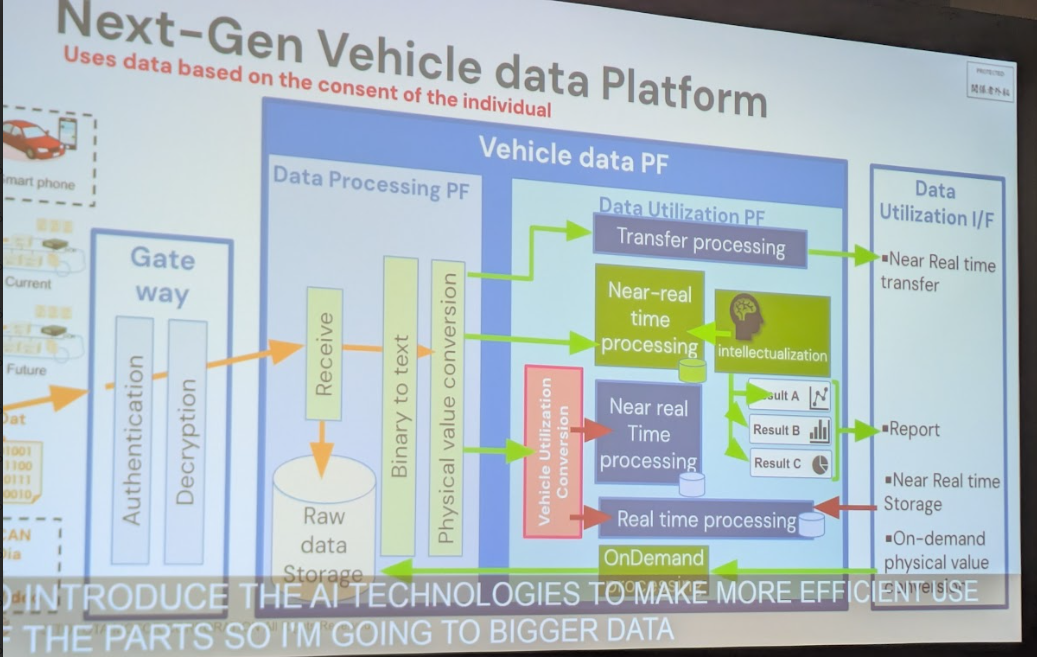
これらの車両からは、1台あたり1日に約3MB、年間でグローバル全体では10TBにも及ぶ膨大なデータが収集されています。このデータには、車速や位置情報、各種センサーの値などが含まれており、これらを活用することで新たな価値を生み出すことが期待されていました。しかし、この巨大なデータ基盤には、いくつかの深刻な課題があったと大江氏は語ります。
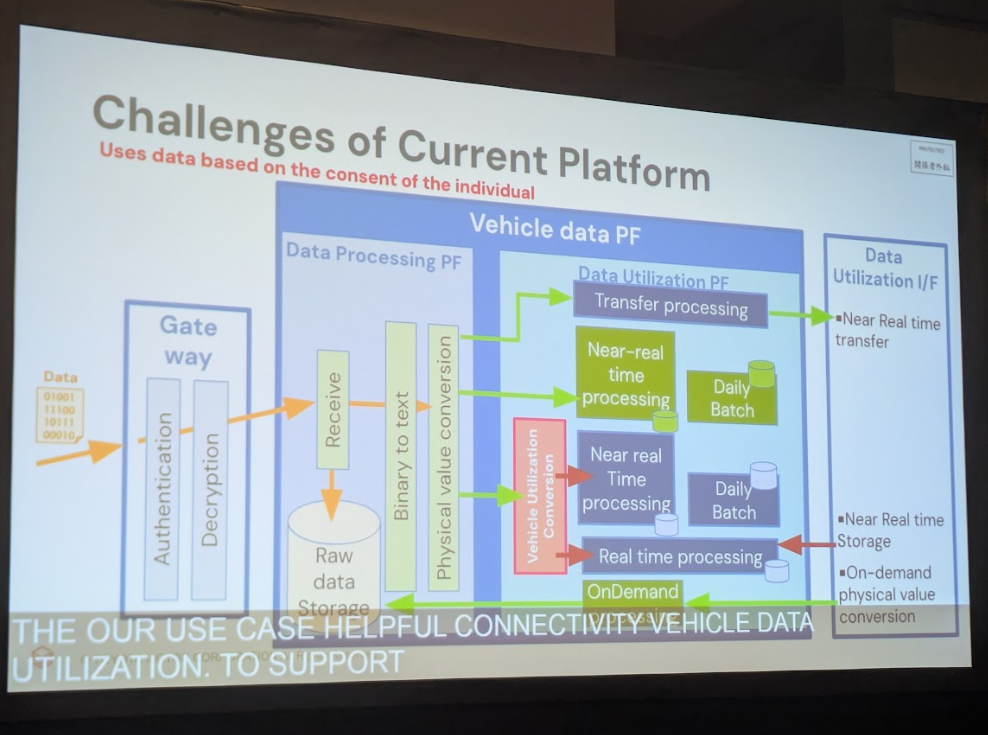
特に大きな課題となっていたのが、プライバシーガバナンスです。ユーザーからデータ削除の要求があった場合、ペタバイト級のデータの中から該当する個人のデータを正確かつ迅速に特定し、削除する必要がありました。講演によると、従来のAmazon EMRとParquetファイルで構成された基盤では、1レコードを削除するためだけにファイル全体を書き換える必要があり、処理に膨大な時間とコストがかかっていたのです。システムの複雑化や、用途ごとにデータが孤立する「サイロ化」も、データ活用の足かせとなっていました。
なぜDatabricksだったのか? 技術選定のポイント
これらの課題を解決するために、トヨタが新たなデータ基盤として採用したのがDatabricksです。Databricksへの移行を決定した背景には、既存基盤の課題を直接的に解決できる技術的な優位性がありました。
講演で示された主な要件は以下の通りです。
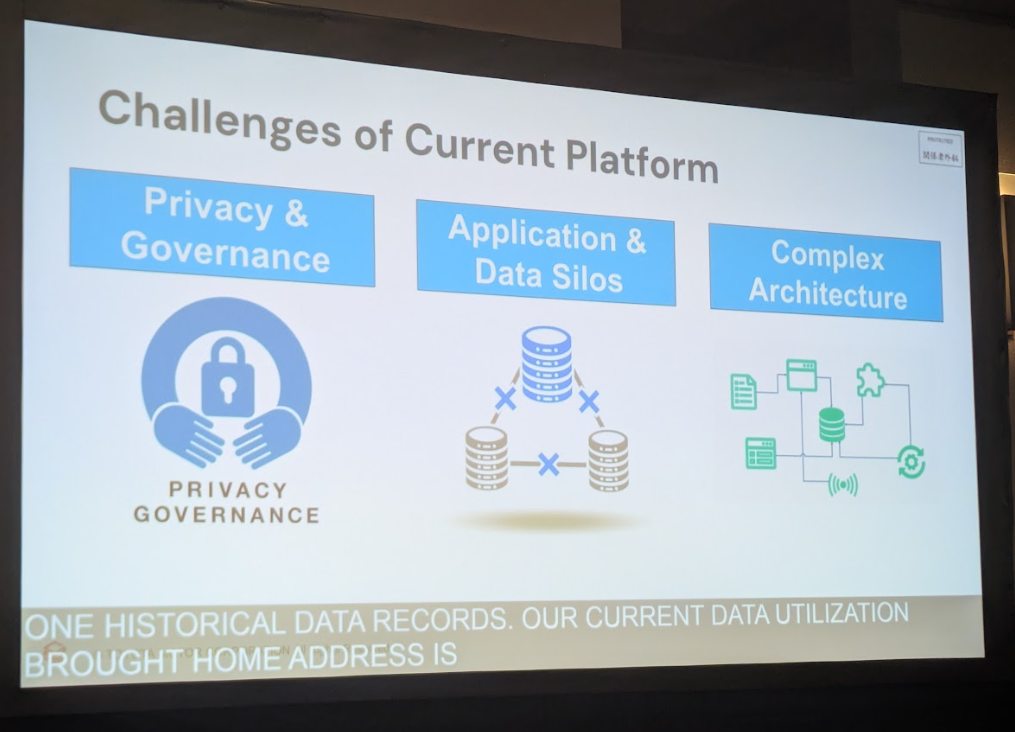
- プライバシーガバナンスの徹底: GDPRなどの法規制を遵守し、ユーザーのデータ削除要求に迅速かつ低コストで対応できること。
- データとアプリケーションの統合: サイロ化されたデータを一元管理し、組織全体でシームレスに活用できる環境を構築すること。
- システム複雑性の解消: スケーラビリティと運用効率の高い、シンプルなアーキテクチャを実現すること。
これらの要件を満たすため、トヨタはDatabricksが提供するデータレイクハウスのアーキテクチャに着目しました。特に、Delta Lake、Unity Catalog、そしてLiquid Clusteringといった機能が、課題解決の鍵となったようです。
Databricksがもたらした3つのソリューション
トヨタが構築した新しいデータ基盤は、主に3つの技術的アプローチによって支えられています。
1. Delta Lakeによるストレージ最適化とコスト削減
従来のデータレイクが抱えていた課題、特にデータ更新・削除の非効率性を解決したのが、オープンソースのストレージレイヤーであるDelta Lakeです。
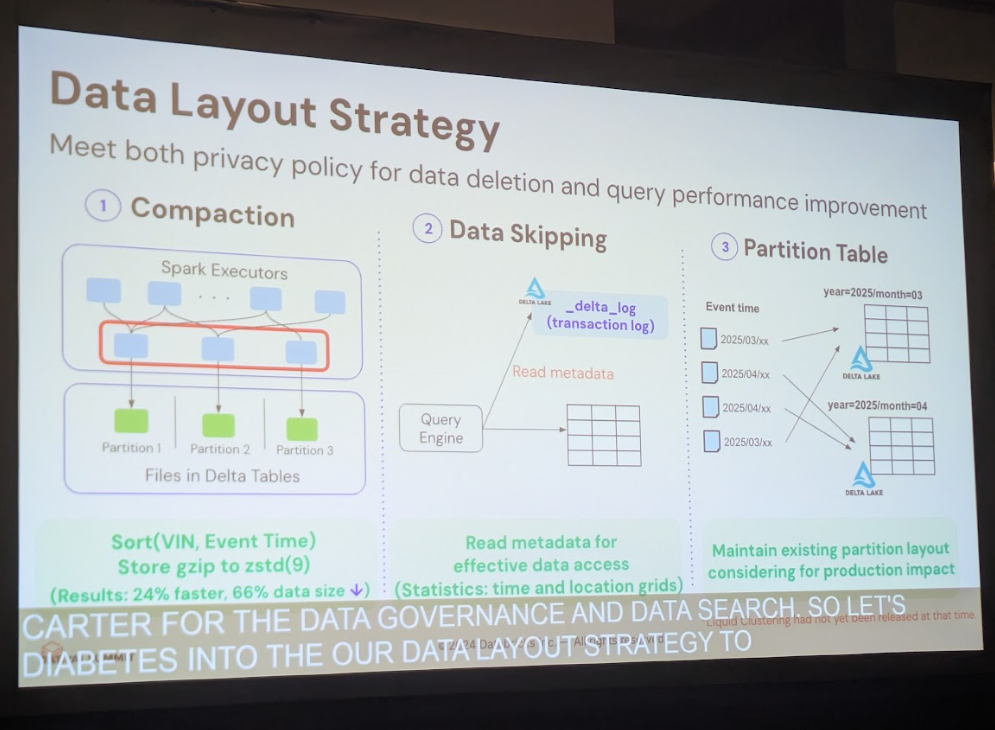
トヨタの事例では、まずデータの書き込み時にファイルを効率的にまとめる「コンパクション」や、クエリの対象とならないファイルを読み飛ばす「データスキッピング」といった機能を活用し、ストレージコストと処理性能を最適化しました。

そして最も重要なのが、データ削除のプロセスです。Delta LakeのDeletion Vector機能を使うことで、物理的にファイルを書き換えることなく、対象レコードに削除マークを付ける論理削除が可能になります。これにより、ユーザーからの削除要求に対して、従来とは比較にならないほど高速な処理が実現しました。講演では、この移行によってソフトウェアコストが99%低減し、ハードウェアコストも95%削減できたという成果が報告されています。
2. Unity Catalogによる鉄壁のデータプライバシーガバナンス
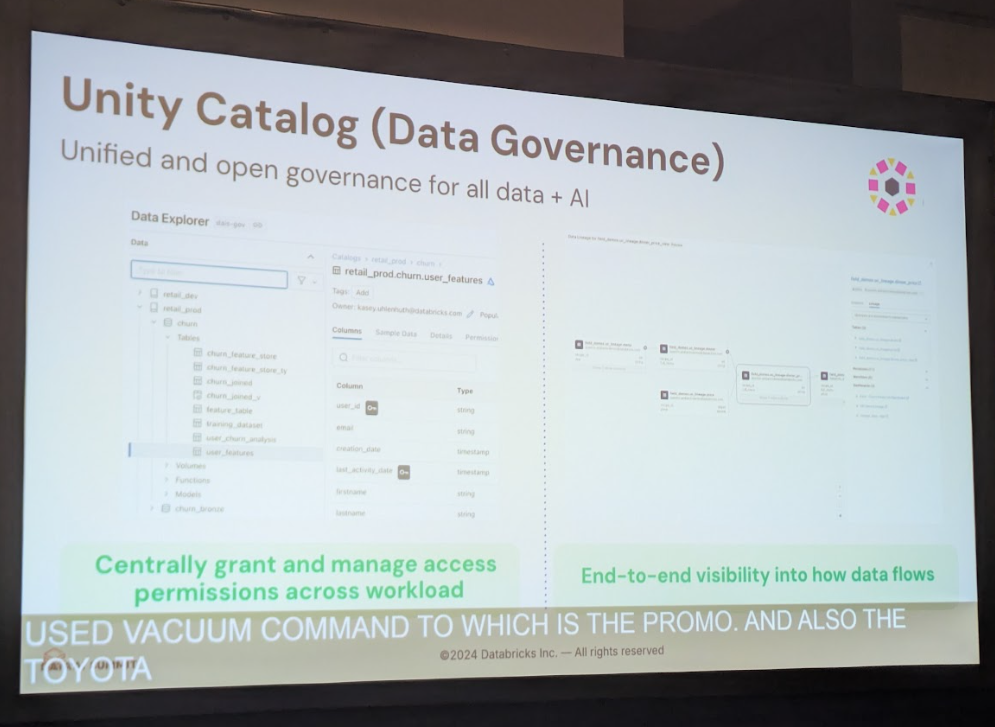
ペタバイト級のデータの中から特定のユーザーのデータを正確に探し出すには、データが「いつ、どこから来て、誰が、どのように使っているのか」を把握する仕組みが不可欠です。これを実現したのが、Databricksの統合データガバナンス機能であるUnity Catalogです。
Unity Catalogを導入することで、トヨタはすべてのデータ資産を一元的に管理し、誰がどのデータにアクセスできるかを細かく制御できるようになりました。また、データの来歴を追跡する「データリネージ」機能により、あるデータがどの処理を経て、どのテーブルに格納されたかを可視化できます。これにより、ユーザーからの削除要求があった際も、関連するデータを正確に特定し、Delta Lakeを通じて効率的に削除することが可能になったのです。
3. Liquid Clusteringによるリアルタイム・遅延データ処理

コネクテッドカーのデータ処理には特有の難しさがあります。それは「遅延データ」の存在です。車両がトンネル内を走行している場合など、通信が不安定な状況ではデータは車両内部に一時保存され、通信が回復した後にまとめて送信されます。その結果、データが生成された時刻とサーバーに到着する時刻にズレが生じ、データが時系列通りに格納されないという問題が発生します。

この課題に対して、トヨタはDelta Lakeの新しいクラスタリング機能であるLiquid Clusteringの活用を進めています。従来の静的なパーティショニングとは異なり、Liquid Clusteringはデータの書き込みに応じて動的かつ継続的にデータファイルのレイアウトを最適化します。これにより、遅れて到着したデータも適切な位置に自動で再配置され、クエリのパフォーマンスを損なうことなく、リアルタイムに近いデータ検索と大規模な履歴データ分析の両立を目指しています。
データが変えるモビリティの未来:具体的なユースケース
こうした先進的なデータ基盤の上で、トヨタはすでに数多くの価値を社会に提供しています。講演で紹介されたユースケースは、私たちの生活に密接に関わるものばかりです。
- 交通情報サービス: 膨大な車両の位置情報をリアルタイムに分析し、より精度の高い交通情報を提供。
- 災害時の通行実績マップ: 災害発生時に、実際に車両が通行できた道路の情報を集約し、緊急車両のルート確保や避難支援に活用。
- 路面・危険地点の特定: 急ブレーキの多発地点や、ABS(アンチロック・ブレーキ・システム)が頻繁に作動する場所のデータを分析。ある交差点では、このデータを基に道路標示を改善した結果、ABS作動回数が月平均10回から1回へと激減したという事例も紹介されました。
これらの事例は、コネクテッドカーデータが単なる車両の改善に留まらず、社会インフラの維持や交通安全に直接貢献できることを示しています。
今後の展望:カメラデータと生成AIの活用

トヨタの挑戦はまだ終わりません。今後は、車両から得られるCANデータに加えて、車載カメラの映像データを統合し、より高度な安全運転支援システムの実現を目指しています。映像データを組み合わせることで、道路状況の認識精度を飛躍的に向上させることが期待されます。
さらに、生成AI技術を導入し、膨大なデータから人間では気づけないようなインサイトを自動で抽出し、交通事故の予知やインフラ保全など、より大きな社会貢献へと繋げていくビジョンも示されました。
まとめ
トヨタの取り組みは、コネクティッドカーという巨大なデータソースを前に、現代企業が直面する「データ価値の最大化」と「プライバシー保護」という二律背反の課題に対する一つの明確な答えを示しています。
Databricksのレイクハウスアーキテクチャを中核に据え、Delta Lakeによる効率的なデータ管理、Unity Catalogによる堅牢なガバナンス、そしてLiquid Clusteringによるリアルタイム処理の最適化を組み合わせることで、トヨタは技術と規制の両面からこの課題を乗り越えようとしています。
自動車から生まれるデータが、私たちの移動体験だけでなく、社会全体をより良くしていく。そんな未来の実現に向けたトヨタの挑戦から、今後も目が離せません。