はじめに
こんにちは。クラウド事業部の上野です。
最近CKA(Certified Kubernetes Administrator)の勉強を進めておりその際にkubeadmというツールを利用して自作kubernetes環境を構築できると知ったので、勉強がてら自宅のProxmoxサーバー環境で構築してみることにしました。
この記事を見てkubeadmで自宅にkubernetes環境を構築してみるきっかけにしていただければと思います。
今回の構成
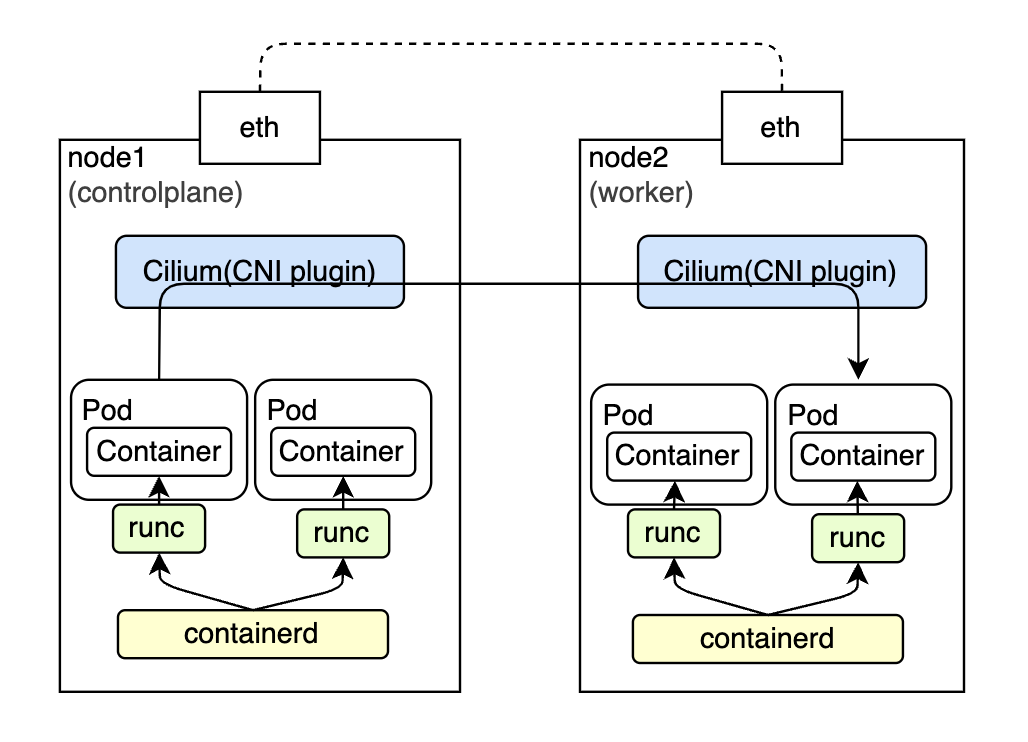
今回は1台のProxmoxサーバー上にVMを2つ構築し、それぞれをcontrolplane nodeとworker nodeとして構築します。
高レベルコンテナランタイムにはcontainerd、低レベルランタイムにrunc, CNI pluginにはCiliumを使用します。
参考にするサイト
今回参考にするのは、kubernetes公式の以下2つのサイトです。下記に従って構築を進めるので、大きく分けてインストールと構築の2フェーズで説明して行きます。
また、containerdのインストールとCiliumのインストールは以下リンクを参考にしています。
- containerd/docs/getting-started.md at main · containerd/containerd · GitHub
- Installation using kubeadm — Cilium 1.17.4 documentation
1. kubeadmのインストール
まずはkubeadmと関連リソースのインストール・セットアップのためにインストール要件の確認を行います。
1-1. インストール要件確認
- 次のいずれかが動作しているマシンが必要
- Ubuntu 16.04+, Debian 9+, CentOS 7, Red Hat Enterprise Linux (RHEL) 7, Fedora 25+, HypriotOS v1.0.1+, Container Linux (tested with 1800.6.0)
- 1台あたり2GB以上のメモリ
- 2コア以上のCPU
- マシン間で通信が可能なネットワーク構成
- ユニークなhostname, MACアドレスとproduct_uuidが各ノードに当てられている
- マシン内の特定のポートが開いていること。
- Swapがオフであること。
上4つの要件はVM構築時に気をつければ良いだけです。1つ目については、今回Ubuntu 24.04.2 LTSを利用しているので問題なしです。下3つについては以下でコマンドから確認します。
MACアドレスとproduct_uuidが全てのノードでユニークであることの検証
今回はVMでノードを立てているので上記リンク先の説明にもある通り一意でない可能性もあるのでしっかり確認しておきます。
$ ip link # controlplane-01 bc:24:11:de:92:8a # worker-01 bc:24:11:de:1a:c0 $ sudo cat /sys/class/dmi/id/product_uuid # controlplane-01 74615163-c1c3-8a48-bfccbadd775d # worker-01 0e4fe655-7c71-44ab-8532-a06de5fc0545
必須ポートの確認
kubeadmで構築するkube-apiserverはデフォルトで6443なのでそれだけ確認
ke-ueno@controlplane-01:~$ nc 127.0.0.1 6443 -zv -w 2 Connection to 127.0.0.1 6443 port [tcp/*] succeeded! ke-ueno@controlplane-01:~$ sudo ufw status Status: inactive
PodネットワークプラグインによってListen可能にしておくべきポートは変わります。
Ciliumで許可する必要のあるポートについては以下に記載があります。Hubbleを利用するか、wireguardを利用するかなどによって許可するPortは変わります。
ただ今回はfirewallは無効化しているため特に設定不要です。
Swap offの確認
swapon --showで何も表示されない。もしくはfree -hで0になっていればOK。
$ swapon --show
$ free -h
total used free shared buff/cache available
Mem: 3.8Gi 1.2Gi 280Mi 4.5Mi 2.6Gi 2.6Gi
Swap: 0B 0B 0B
1-2. コンテナランタイムのインストール
次はコンテナランタイムのインストールを行います。 コンテナランタイムとは、Pod内のコンテナ作成、実行、停止などを管理するためのものです。今回はcontainerdを利用します。
共通設定(IPv4フォワーディングを有効化し、iptablesからブリッジされたトラフィックを見えるようにする)
全コンテナランタイムに共通の設定を行う。
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter # この構成に必要なカーネルパラメーター、再起動しても値は永続します cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF # 再起動せずにカーネルパラメーターを適用 sudo sysctl --system # 反映されていることを確認すれば完了 $ lsmod | grep br_netfilter br_netfilter 32768 0 bridge 421888 1 br_netfilter $ lsmod | grep overlay overlay 212992 0 $ sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1Installing containerd
上記で共通設定を行ったらあとはcontainerdのinstall手順を進めます。(参照: コンテナランタイム)
以下getting-startedのstep1~2を行えば良いです。step3は今回CNI pluginはCiliumを使うため実行不要です。
https://github.com/containerd/containerd/blob/main/docs/getting-started.md
Step 1: Installing containerd
$ wget https://github.com/containerd/containerd/releases/download/v2.1.1/containerd-2.1.1-linux-amd64.tar.gz $ wget https://github.com/containerd/containerd/releases/download/v2.1.1/containerd-2.1.1-linux-amd64.tar.gz.sha256sum $ sha256sum -c containerd-2.1.1-linux-amd64.tar.gz.sha256sum containerd-2.1.1-linux-amd64.tar.gz: OK $ sudo tar Cxzvf /usr/local containerd-2.1.1-linux-amd64.tar.gz [sudo] password for ke-ueno: bin/ bin/containerd-shim-runc-v2 bin/containerd bin/containerd-stress bin/ctrsystemd経由でcontainerdを起動する場合は以下対応も行う。今回はその場合に該当するため実施。
$ wget https://raw.githubusercontent.com/containerd/containerd/main/containerd.service $ mv ./containerd.service /etc/systemd/system $ systemctl daemon-reload $ systemctl enable --now containerd Created symlink /etc/systemd/system/multi-user.target.wants/containerd.service -> /etc/systemd/system/containerd.service.なぜsystemd経由で起動するのか?
後ほどの手順でcontainerdのcgroup driverにsystemdを設定するため起動もsystemdに合わせる。Step 2: Installing runc
$ wget https://github.com/opencontainers/runc/releases/download/v1.3.0/runc.amd64 $ sudo install -m 755 runc.amd64 /usr/local/sbin/runc $ sudo ls /usr/local/sbin runcruncとは?
containerdは実際にコンテナの起動を行わずruncというOCI ランタイム仕様の実装を利用してコンテナを起動する。 OCI ランタイムとはコンテナを起動するための標準仕様で、runcは最も標準的な OCI ランタイムである。Advanced topics:
config.tomlをcontainerdのデフォルト値で設定。
$ sudo mkdir /etc/containerd $ sudo sh -c "containerd config default > /etc/containerd/config.toml"
ここまで行ったら、コンテナランタイムのcontainerdの手順に戻ってきて上記で作成したconfig.tomlの修正を行います。
- systemd cgroupドライバーを構成する(参照)
/etc/containerd/config.tomlを以下の通り修正これによってruncがsystemd cgroupドライバーを使用するようになります。
cgroupドライバーとは?
cgroupの管理を誰にさせるかを決めるコンポーネント。cgroupfsとsystemdが主な選択肢であり、systemdが動いているノードであればsystemdにまとめるべき。cgroupとは?
プロセスのリソース管理をグループ単位で行うための仕組み。コンテナではメモリ要求やメモリ上限の管理に使用される。なぜsystemdのcgroupドライバーにするのか
initシステムにsystemdが採用されているのに、cgroup driverにcgroupfsを採用するとcgroupを管理するマネージャーが2つ存在することになり、高負荷環境で不安定になる。これを回避するためにkubeletとコンテナランタイムのcgroupドライバーをsystemdに統一するのが推奨。(詳細は右記参照: コンテナランタイム)..... [plugins.'io.containerd.grpc.v1.cri'] disable_tcp_service = true stream_server_address = '127.0.0.1' stream_server_port = '0' stream_idle_timeout = '4h0m0s' enable_tls_streaming = false #以下追記部分 [plugins."io.containerd.grpc.v1.cri".containerd] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true ...../etc/containerd/config.toml内のdisabled_pluginsリストにcriが含まれていないことを確認。
containerdを再起動
sudo systemctl restart containerd
1-3. kubeadm、kubelet、kubectlのインストール
今回はまっさらな環境に、v1.33でinstallを行います。kubeadmでinstallされるkubeapi-serverとkubeletのversionは、同じかkubeletが一つ古いかで合わせる必要があります。
$ sudo apt-get update $ sudo apt-get install -y apt-transport-https ca-certificates curl gpg $ curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.33/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg $ echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list $ sudo apt-get update $ sudo apt-get install -y kubelet kubeadm kubectl $ sudo apt-mark hold kubelet kubeadm kubectl
1-4. kubeletによって使用されるcgroupドライバーの設定(Option)
今回使用するコンテナランタイム(containerd)は、上記でcgroup-driverにsystemdを使うように設定を行なっています。そのためkubeletでもsystemdをdriverに使うよう値を修正します。(ここを合わせないとうまく動かない)
v1.22以降はデフォルトでsystemdを利用するようになっているとのことなのでわざわざ設定する必要はおそらくなかったのですがここでは勉強のため明示的に設定してみました。
/etc/default/kubeletの内容を以下に修正
KUBELET_EXTRA_ARGS=--cgroup-driver=systemdkubeletをリスタート
# restart $ systemctl daemon-reload $ systemctl restart kubelet # 動作確認 $ sudo systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset: enabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: activating (auto-restart) (Result: exit-code) since Sun 2025-06-08 12:24:16 UTC; 4s ago Docs: https://kubernetes.io/docs/ Process: 537460 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE) Main PID: 537460 (code=exited, status=1/FAILURE) CPU: 31mskubeadm initを実行するまで、kubeletの設定ファイルである/var/lib/kubelet/config.yamlは生成されないため起動はされません。
1-5. ワーカーノードにインストール
ワーカーノードでもkubeadm,kubelet,kubectl,コンテナランタイムのインストールと設定が必要なので上記で行った以下手順を全く同じようにワーカーノードに対しても実行します。
- インストール要件確認
- コンテナランタイムのインストール
- kubeadm、kubelet、kubectlのインストール
- kubeletによって使用されるcgroupドライバーの設定
ここまでで、kubeadm, kubelet, kubectl, コンテナラインタイム などのインストールと設定は完了です。続いて実際にクラスターの構築作業に移ります。
2. kubeadmを使用したクラスターの作成
続いて以下記事を参考にクラスターの構築を進めます。
2-1. kubeadm init実行前の確認事項
まずは、コントロールプレーンノードの初期化という部分を読み込んで、以下5つの考慮事項について確認します。 ここで確認した結果を元にkubeadm initに渡すオプションを決めます。
コントロールプレーンをHAクラスタに後々したい場合、--control-plane-endpointオプションを設定する。
--control-plane-endpointオプションを使用せずに構築したシングルノードクラスタを高可用性クラスターに切り替えることはサポートされていない。(kubeadmを使用したクラスターの作成 | Kubernetes)
今回は、シングルノードのcontrolplaneですが後々HA構成にして遊ぶといったことも考えられるため--control-plane-endpointオプションを付けて実行したいと思います。
--control-plane-endpoint=endpoint としてDNSで解決できるようにしておくことでHA構成時にcontrolplane間で負荷分散が可能となります。ただ今回は別途DNSサーバを用意する予定はないのでひとまずcontrolplaneのIPアドレスを渡しておきます。
Podネットワークアドオンによっては、--pod-network-cidrをプロバイダー固有の値に設定する必要がある。
CiliumのデフォルトPodCIDRは10.0.0.0/8のようなので、今回はノードのネットワークセグメントと被らないので特に気にすることはなかったです。(Cluster Scope (Default) — Cilium 1.17.4 documentation)
また、Ciliumはkube-proxyの機能を代替できるため、--skip-phases=addon/kube-proxy を指定してkube-proxyのデプロイフェーズを飛ばすようにします。(Installation using kubeadm — Cilium 1.17.4 documentation)
複数ランタイムが混在する場合、--cri-socketで使用するコンテナランタイムを指定する必要がある。
- 今回はcontainerdしか入れてないので設定不要です。
- advertise addressについて
- advertise addressとは、kube-apiserverがどこにあるかを他のコンポーネントに知らせるアドレス。kube-apiserverと通信したいコンポーネントはこのアドレスを使用します。
- 今回はcontrolplaneのIPアドレスを指定します。
gcr.ioコンテナイメージレジストリに接続できるか確認する。
$ sudo kubeadm config images pull [sudo] password for xxxx: [config/images] Pulled registry.k8s.io/kube-apiserver:v1.33.1 [config/images] Pulled registry.k8s.io/kube-controller-manager:v1.33.1 [config/images] Pulled registry.k8s.io/kube-scheduler:v1.33.1 [config/images] Pulled registry.k8s.io/kube-proxy:v1.33.1 [config/images] Pulled registry.k8s.io/coredns/coredns:v1.12.0 [config/images] Pulled registry.k8s.io/pause:3.10 [config/images] Pulled registry.k8s.io/etcd:3.5.21-0
2-2. kubeadm init実行
上記考慮事項を参考に kubeadm init を以下の通り実行します。
ke-ueno@controlplane-01:~$ sudo kubeadm init \
--skip-phases=addon/kube-proxy \
--apiserver-advertise-address=192.168.10.105 \
--control-plane-endpoint=192.168.10.105
[init] Using Kubernetes version: v1.33.1
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [controlplane-01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.10.105]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [controlplane-01 localhost] and IPs [192.168.10.105 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [controlplane-01 localhost] and IPs [192.168.10.105 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.000965599s
[control-plane-check] Waiting for healthy control plane components. This can take up to 4m0s
[control-plane-check] Checking kube-apiserver at https://192.168.10.105:6443/livez
[control-plane-check] Checking kube-controller-manager at https://127.0.0.1:10257/healthz
[control-plane-check] Checking kube-scheduler at https://127.0.0.1:10259/livez
[control-plane-check] kube-controller-manager is healthy after 2.024031637s
[control-plane-check] kube-scheduler is healthy after 2.231191716s
[control-plane-check] kube-apiserver is healthy after 4.002064251s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node controlplane-01 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node controlplane-01 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: f27xgq.hn8p382jk7zv7b6r
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.10.105:6443 --token f27xgq.hn8p382jk7zv7b6r \
--discovery-token-ca-cert-hash sha256:c6f31a0a858a0c751d4cd52753c4bddde4c58b1852012ca23bc372982d7e57da \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.10.105:6443 --token f27xgq.hn8p382jk7zv7b6r \
--discovery-token-ca-cert-hash sha256:c6f31a0a858a0c751d4cd52753c4bddde4c58b1852012ca23bc372982d7e57da
kubeconfig設定
controlplaneにroot以外でログイン中なら、kubeadm init実行時の成功ログに表示される以下コマンドを実行して、kubeconfigを設定しクラスターを操作できるようにします。(今回はke-uenoでログイン中だったので以下の通り実行しました。)
# root以外のuserからクラスターへの操作をするためのconfig設定をadminからコピーして設定 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
2-3. ワーカーノードをクラスターに追加
同じくkubeadm init実行時の成功ログの一番したにワーカーノードとしてクラスターにjoinさせるためのコマンドが表示されているのでこちらをワーカーノードで実行します。
ke-ueno@worker01:~$ sudo kubeadm join 192.168.10.105:6443 --token f27xgq.hn8p382jk7zv7b6r \
--discovery-token-ca-cert-hash sha256:c6f31a0a858a0c751d4cd52753c4bddde4c58b1852012ca23bc372982d7e57da
[preflight] Running pre-flight checks
[preflight] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[preflight] Use 'kubeadm init phase upload-config --config your-config-file' to re-upload it.
W0614 03:30:30.330932 1412 configset.go:78] Warning: No kubeproxy.config.k8s.io/v1alpha1 config is loaded. Continuing without it: configmaps "kube-proxy" is forbidden: User "system:bootstrap:vkyywq" cannot get resource "configmaps" in API group "" in the namespace "kube-system"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 501.030339ms
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
join実行時のトラシュー
joinに途中で失敗して作り直しなどする際、以前作成した以下ファイルが残骸として残っていまっていることがありエラーが出たりするのでその時は削除する。
ke-ueno@worker01:~$ sudo rm /etc/kubernetes/bootstrap-kubelet.conf ke-ueno@worker01:~$ sudo rm /etc/kubernetes/pki/ca.crt
tokenのデフォルトの有効期限は24hなので、それを過ぎたら以下コマンドで取得しなおす必要がありました。
$ kubeadm token create amfqxk.cmnisxd07btp96le
ワーカーノードからクラスタ操作をできるようにする。
ワーカーノードからクラスタを操作したければ、controlplaneから $HOME/.kube/config のコピーを取得するなどconfigファイルを作成する必要があります。
ke-ueno@worker01:~$ mkdir -p $HOME/.kube ke-ueno@worker01:~$ scp ke-ueno@192.168.10.105:~/.kube/config $HOME/.kube ke-ueno@worker01:~$ sudo chown $(id -u):$(id -g) $HOME/.kube/config ke-ueno@worker01:~$ kubectl get nodes NAME STATUS ROLES AGE VERSION controlplane-01 Ready control-plane 15m v1.33.1 worker01 Ready <none> 10m v1.33.1
ここまででクラスターの構築は完了です。現状は以下のようになっているかと思います。corednsはCNI pluginを入れるまでは立ち上がらないため以下で問題ありません。
node一覧を確認するとjoinすることでworker nodeも表示されるようになったと思います。
ke-ueno@controlplane-01:~$ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-674b8bbfcf-hfrrf 0/1 ContainerCreating 0 59s coredns-674b8bbfcf-ngc6n 0/1 ContainerCreating 0 59s etcd-controlplane-01 1/1 Running 1 65s kube-apiserver-controlplane-01 1/1 Running 1 65s kube-controller-manager-controlplane-01 1/1 Running 2 65s kube-scheduler-controlplane-01 1/1 Running 2 65s ke-ueno@controlplane-01:~$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME controlplane-01 Ready control-plane 5m8s v1.33.1 192.168.10.105 <none> Ubuntu 24.04.2 LTS 6.8.0-60-generic containerd://2.1.1 worker01 Ready <none> 27s v1.33.1 192.168.10.104 <none> Ubuntu 24.04.2 LTS 6.8.0-60-generic containerd://2.1.1
次は、CNI pluginであるCiliumを入れてPod間ネットワークを構築したいと思います。
3. Podネットワーク構築
Ciliumにちょうどkubeadmを利用する際のインストールページがあったのでこちらを参考にinstallを進めます。特に難しい手順はなく、helmからinstallすれば良いだけです。
Installation using kubeadm — Cilium 1.17.4 documentation
ke-ueno@controlplane-01:~$ sudo snap install helm --classic
ke-ueno@controlplane-01:~$ helm repo add cilium https://helm.cilium.io/
# kube-apiserverのIPアドレスとPort番号を指定する。
ke-ueno@controlplane-01:~$ API_SERVER_IP=192.168.10.105
ke-ueno@controlplane-01:~$ API_SERVER_PORT=6443
ke-ueno@controlplane-01:~$ helm install cilium cilium/cilium --version 1.17.4 \
--namespace kube-system \
--set kubeProxyReplacement=true \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}
coredns Podが立ち上がっていればPodネットワークのインストールは成功です。(参照)
ke-ueno@controlplane-01:~$ kubectl -n kube-system get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cilium-envoy-2lhg9 1/1 Running 0 126m 192.168.10.104 worker01 <none> <none> cilium-envoy-9ld28 1/1 Running 0 126m 192.168.10.105 controlplane-01 <none> <none> cilium-ksz4m 1/1 Running 0 126m 192.168.10.105 controlplane-01 <none> <none> cilium-mn7n6 1/1 Running 0 126m 192.168.10.104 worker01 <none> <none> cilium-operator-544c765f55-h4876 1/1 Running 0 126m 192.168.10.105 controlplane-01 <none> <none> cilium-operator-544c765f55-tfx49 1/1 Running 0 126m 192.168.10.104 worker01 <none> <none> coredns-674b8bbfcf-8rwpv 1/1 Running 0 145m 10.0.0.57 controlplane-01 <none> <none> coredns-674b8bbfcf-bq7lm 1/1 Running 0 145m 10.0.0.151 controlplane-01 <none> <none> etcd-controlplane-01 1/1 Running 0 145m 192.168.10.105 controlplane-01 <none> <none> kube-apiserver-controlplane-01 1/1 Running 0 145m 192.168.10.105 controlplane-01 <none> <none> kube-controller-manager-controlplane-01 1/1 Running 1 145m 192.168.10.105 controlplane-01 <none> <none> kube-scheduler-controlplane-01 1/1 Running 1 145m 192.168.10.105 controlplane-01 <none> <none>
また、Ciliumには独自にポッド間の接続性をテストする「connectivity-check」というものが用意されているのでこちらをデプロイしてみます。
Installation using kubeadm — Cilium 1.17.4 documentation
ke-ueno@controlplane-01:~$ kubectl create ns cilium-test ke-ueno@controlplane-01:~$ kubectl apply -n cilium-test -f https://raw.githubusercontent.com/cilium/cilium/1.17.4/examples/kubernetes/connectivity-check/connectivity-check.yaml ke-ueno@controlplane-01:~$ kubectl get pods -n cilium-test NAME READY STATUS RESTARTS AGE echo-a-54dcdd77c-m9n88 1/1 Running 0 2m52s echo-b-549fdb8f8c-vnzhk 1/1 Running 0 2m52s echo-b-host-7cfdb688b7-jbxsl 1/1 Running 0 2m52s host-to-b-multi-node-clusterip-c54bf67bf-ck8cc 0/1 Pending 0 2m51s host-to-b-multi-node-headless-55f66fc4c7-82xl9 0/1 Pending 0 2m50s pod-to-a-5f56dc8c9b-wpj6v 1/1 Running 0 2m52s pod-to-a-allowed-cnp-5dc859fd98-c98xn 1/1 Running 0 2m51s pod-to-a-denied-cnp-68976d7584-mfk8p 1/1 Running 0 2m52s pod-to-b-intra-node-nodeport-5884978697-k2f25 1/1 Running 0 2m50s pod-to-b-multi-node-clusterip-7d65578cf5-8rh7j 0/1 Pending 0 2m51s pod-to-b-multi-node-headless-8557d86d6f-zg8kw 0/1 Pending 0 2m51s pod-to-b-multi-node-nodeport-7847b5df8f-whn9w 0/1 Pending 0 2m50s pod-to-external-1111-797c647566-dw5zm 1/1 Running 0 2m52s pod-to-external-fqdn-allow-google-cnp-5688c867dd-bm5p8 1/1 Running 0 2m51s $ kubectl delete ns cilium-test
Runningになっているものはチェックが完了したPodです。
立ち上がっていないPodでは以下メッセージが出ますが、これはcontrol-planeにpodが配置できないようになっているために複数ノードが必要なチェック項目は実施できなかったことを意味します。これは想定内の挙動なので特に問題ありません。
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 50s default-scheduler 0/2 nodes are available: 1 node(s) didn't match pod anti-affinity rules, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/2 nodes are available: 1 No preemption victims found for incoming pod, 1 Preemption is not helpful for scheduling.
接続性チェックを単一ノード・クラスターにデプロイすると、複数ノードの機能をチェックするポッドは保留状態のままになります。これらのポッドが正常にスケジュールされるには少なくとも2ノードが必要なので、これは予想されることです。(参照)
ここまで確認できればPodネットワーク導入完了となります!
kubeadm reset
何かと kubeadm init 以降に設定ミスなどで構築し直したくなる時がありました。
そんな時は kubeadm reset を使用することでkubeadm initで実行した内容をresetすることができます。
reset実行後は再度 kubeadm init から構築をし直すことができるので困ったら使うと良いです。
$ sudo kubeadm reset
まとめ
今回はkubeadmを使ってcontrolplane1台とworker1台の上に、ciliumを組み合わせたkubernetes環境の構築を行いました。
コンテナランタイムの設定でcgroup drverにsystemdの設定をしたり、Ciliumを利用する際はkube-proxyをoffにしたり、kubeadm init実行時にどういったオプションを設定するべきなのかを調べて整理するのに苦労しましたがこの構築手順を通してよりkubernetesの理解を深めることができました。今後もcontrolplaneを複数ノード構成にしたりして拡張してみたいなと思っています。
CKAの勉強中だったり、kubernetesの理解を深めたい人はこの記事を参考に自分でもやってみるといいのではないかと思います!
長々とありがとうございました。
おわりに
私達クラウド事業部はクラウド技術を活用したSI/SESのご支援をしております。
また、一緒に働いていただける仲間も募集中です! ご興味持っていただけましたらぜひお声がけください。