
はじめに
GLB事業部Lakehouse部の阿部です。
Databricks Advent Calendar 2023の15日目の記事です。
TerraformでDatabricksワークスペースのデプロイ、管理にフォーカスして記事を書きました。 前編・後編に分かれており、本記事は後編でリソース管理について書きました。
前編の記事はこちらです。
それでは早速、ワークスペースのリソース設定ファイルを作成していきます。
ワークスペースの管理
ワークスペースのリソースをTerraformで管理します。
以下ドキュメントを参考にしています。
Terraform を使用して Databricks ワークスペースを管理する - Azure Databricks | Microsoft Learn
まずは、一般的な変数、databricks_spark_version、databricks_node_type、databricks_current_user を初期化します。
terraform {
required_providers {
databricks = {
source = "databricks/databricks"
}
}
}
provider "databricks" {}
data "databricks_current_user" "me" {}
data "databricks_spark_version" "latest" {}
data "databricks_node_type" "smallest" {
local_disk = true
}
前回の記事でワークスペースのサンプル構成を構築しましたが、改めて定義ファイルを作成してterraform planコマンドを実行します。
# Creates a new secret scope
resource "databricks_secret_scope" "this" {
name = "demo-${data.databricks_current_user.me.alphanumeric}"
}
# Generates a Databricks PAT
resource "databricks_token" "pat" {
comment = "Created from ${abspath(path.module)}"
lifetime_seconds = 3600
}
# Stores the generated PAT from the databricks_token.# pat resource in the
# previously created secret scope.
resource "databricks_secret" "token" {
string_value = databricks_token.pat.token_value
scope = databricks_secret_scope.this.name
key = "token"
}
# Creates a Databricks notebook
resource "databricks_notebook" "abe_notebook" {
path = "${data.databricks_current_user.me.home}/Terraform/test_notebook"
language = "PYTHON"
content_base64 = base64encode(<<-EOT
token = dbutils.secrets.get('${databricks_secret_scope.this.name}', '${databricks_secret.token.key}')
print(f'This should be redacted: {token}')
EOT
)
}
# Defines a job in Databricks using the notebook created above.
resource "databricks_job" "abe_job" {
name = "Terraform Demo (${data.databricks_current_user.me.alphanumeric})"
new_cluster {
num_workers = 1
spark_version = data.databricks_spark_version.latest_lts.id
# the smallest node type
node_type_id = data.databricks_node_type.smallest.id
}
notebook_task {
notebook_path = databricks_notebook.this.path
}
email_notifications {}
}
# Configures a Databricks cluster with autoscaling between 1 and 10 workers.
resource "databricks_cluster" "abe_cluster" {
cluster_name = "Exploration (${data.databricks_current_user.me.alphanumeric})"
spark_version = data.databricks_spark_version.latest_lts.id
instance_pool_id = databricks_instance_pool.smallest_nodes.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 10
}
}
# Creates a cluster policy with limits on resources
# and sets a fixed auto-termination time of 20 minutes.
resource "databricks_cluster_policy" "this" {
name = "Minimal (${data.databricks_current_user.me.alphanumeric})"
definition = jsonencode({
"dbus_per_hour" : {
"type" : "range",
"maxValue" : 10
},
"autotermination_minutes" : {
"type" : "fixed",
"value" : 20,
"hidden" : true
}
})
}
# Establishes an instance pool
resource "databricks_instance_pool" "smallest_nodes" {
instance_pool_name = "Smallest Nodes (${data.databricks_current_user.me.alphanumeric})"
min_idle_instances = 0
# with a capacity of up to 30 instances
max_capacity = 30
node_type_id = data.databricks_node_type.smallest.id
preloaded_spark_versions = [
data.databricks_spark_version.latest_lts.id
]
# Idle instances in the pool auto-terminate after 20 minutes.
idle_instance_autotermination_minutes = 20
}
# Outputs the URL of the created Databricks notebook
output "abe_notebook_url" {
value = databricks_notebook.this.url
}
# Outputs the URL of the created Databricks job,
output "abe_job_url" {
value = databricks_job.this.url
}
サンプル構成での変数と被ってエラーが起きた場合は、変数(resourcce, outputのurl)を変えるか、作成済みの設定ファイルを削除します。
terraform planコマンドを実行し、計画結果をplan_output.tfplanファイルに保存します。
terraform plan -out=plan_output.tfplan
そしてplan_output.tfplanファイルに入力された計画を参照し、変更を適用します。
terraform applyコマンドを実行します。
terraform apply "plan_output.tfplan"
Apply complete! Resources: 3 added, 0 changed, 1 destroyed.
3つのリソースが作成され、1つのリソースが削除されました。 (私はサンプル構成で作成したリソースを1つ削除しました)
例として、作成したクラスターには自動停止時間(autotermination_minutes)やオートスケール(autoscale)といったファイルで定義した設定が反映されていることがわかります。
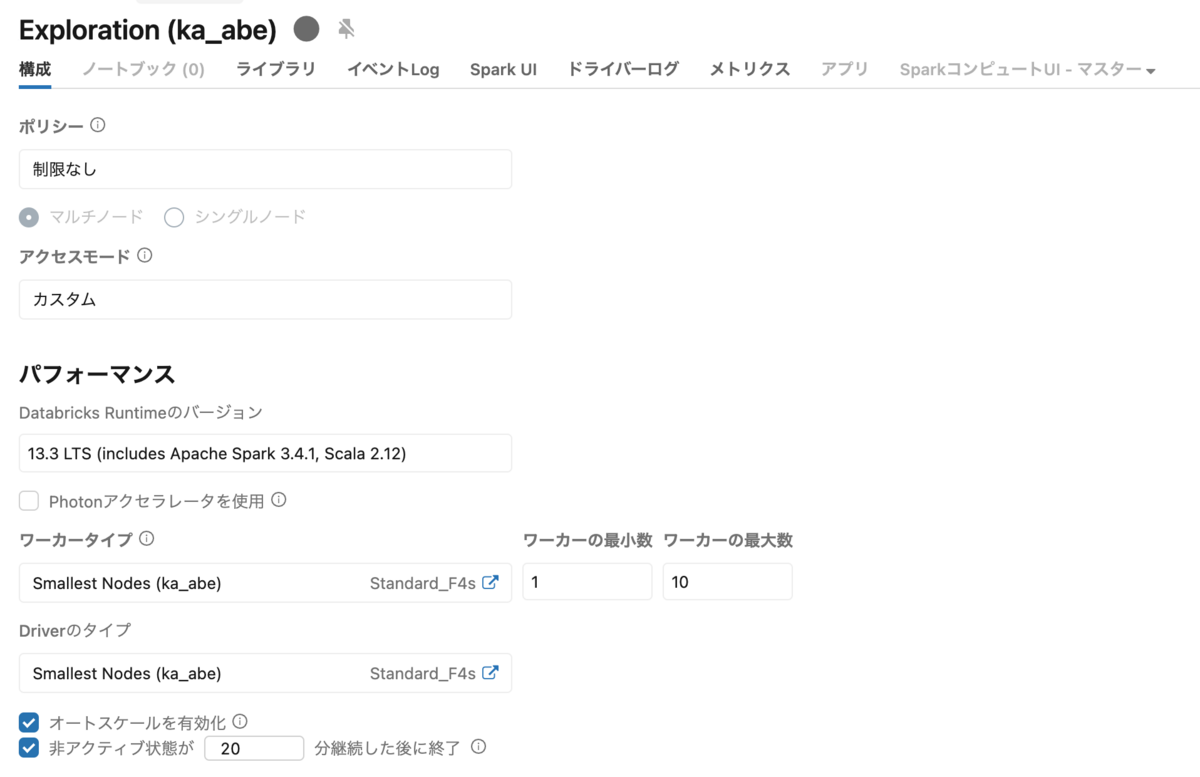
ワークスペースのセキュリティ
今度はnotebookやjobなどの権限周りの設定をします。
resource "databricks_secret_acl" "spectators" {
principal = databricks_group.spectators.display_name
scope = databricks_secret_scope.this.name
permission = "READ"
}
resource "databricks_group" "spectators" {
display_name = "Spectators (by ${data.databricks_current_user.me.alphanumeric})"
}
resource "databricks_user" "dummy" {
user_name = "dummy+${data.databricks_current_user.me.alphanumeric}@example.com"
display_name = "Dummy ${data.databricks_current_user.me.alphanumeric}"
}
resource "databricks_group_member" "a" {
group_id = databricks_group.spectators.id
member_id = databricks_user.dummy.id
}
resource "databricks_permissions" "notebook" {
notebook_path = databricks_notebook.this.id
access_control {
user_name = databricks_user.dummy.user_name
permission_level = "CAN_RUN"
}
access_control {
group_name = databricks_group.spectators.display_name
permission_level = "CAN_READ"
}
}
resource "databricks_permissions" "abe_job" {
job_id = databricks_job.this.id
access_control {
user_name = databricks_user.dummy.user_name
permission_level = "IS_OWNER"
}
access_control {
group_name = databricks_group.spectators.display_name
permission_level = "CAN_MANAGE_RUN"
}
}
resource "databricks_permissions" "abe_cluster" {
cluster_id = databricks_cluster.this.id
access_control {
user_name = databricks_user.dummy.user_name
permission_level = "CAN_RESTART"
}
access_control {
group_name = databricks_group.spectators.display_name
permission_level = "CAN_ATTACH_TO"
}
}
resource "databricks_permissions" "policy" {
cluster_policy_id = databricks_cluster_policy.this.id
access_control {
group_name = databricks_group.spectators.display_name
permission_level = "CAN_USE"
}
}
resource "databricks_permissions" "pool" {
instance_pool_id = databricks_instance_pool.smallest_nodes.id
access_control {
group_name = databricks_group.spectators.display_name
permission_level = "CAN_ATTACH_TO"
}
}
Plan: 11 to add, 0 to change, 1 to destroy.
terraform applyコマンドを実行します。
Apply complete! Resources: 11 added, 0 changed, 1 destroyed.
例えばnotebookの権限を参照すると、グループ名がspectators、 権限がREADのみであり、設定ファイルの内容が反映されていることがわかります。
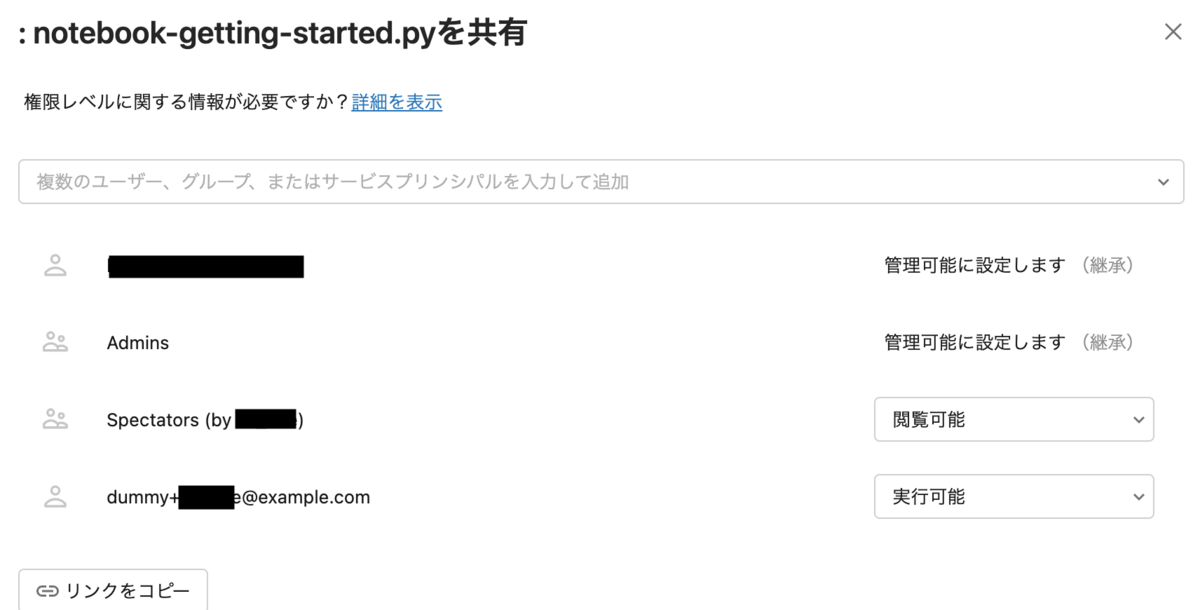
おわりに
前編・後編とTerraformで非常に基本的な設定のみ行いましたが、今回取り扱わなかった設定もあります。すべてのリソースを完全に管理するには、まだまだ理解が必要だと感じました。
気になる方はTerraformの公式ドキュメントを参照ください。
最後までご覧いただきありがとうございます。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
そして、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。