
はじめに
こんにちは、クラウド事業部の志摩です。
DynamoDBにデータを投入する場合、複数の方法があると思いますが、今の現場で仮にDynamoDBを活用するとなった場合、csvファイルを使う可能性が高い気がするので、csvファイルからテーブル作成する方法を試してみました。
下準備
DynamoDBからCSVエクスポート機能があるため、取り込むためのファイルを自ら生成し、それを別の新規テーブル用に読み込ませることで、機能を試してみようと思います。
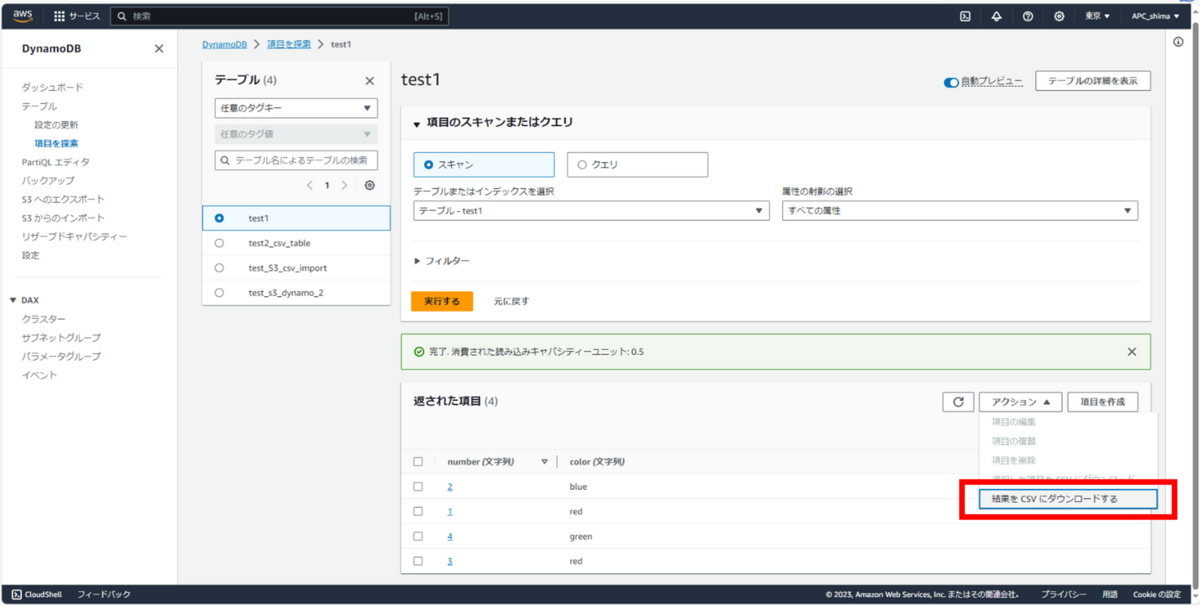
ダウンロードしたCSVをS3へアップロード。
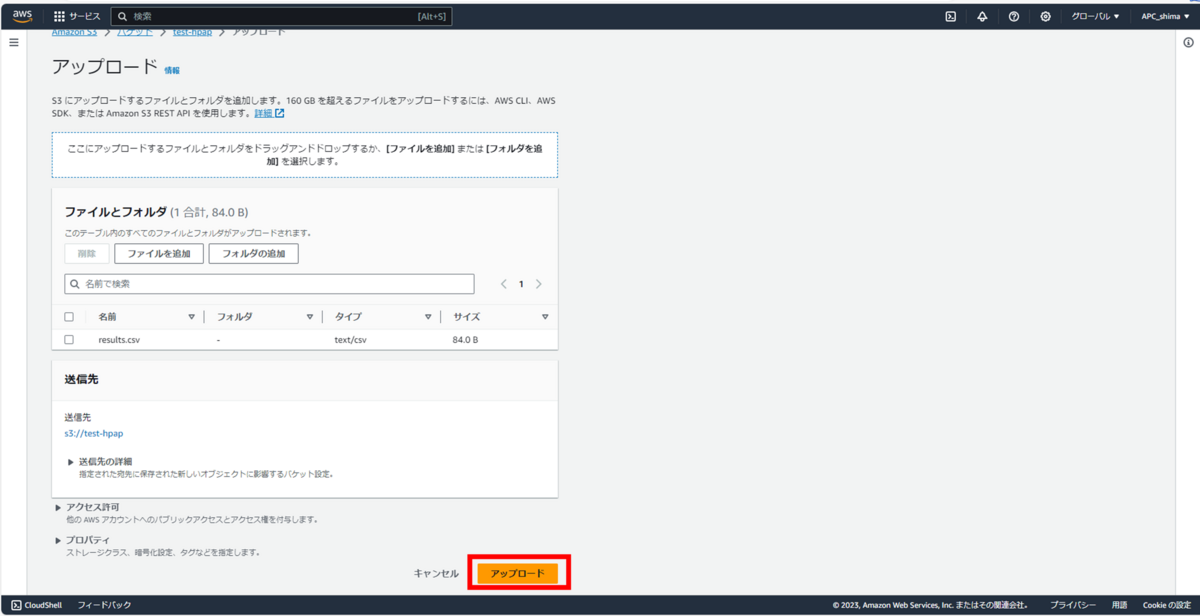
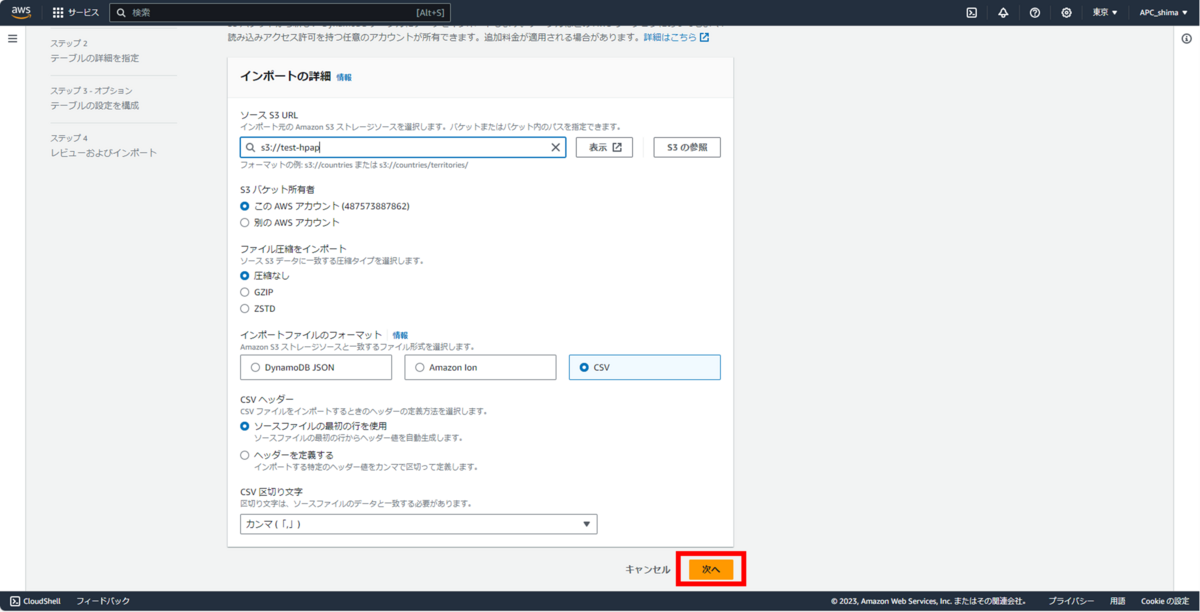
DynamoDBへインポートするS3バケットを指定。
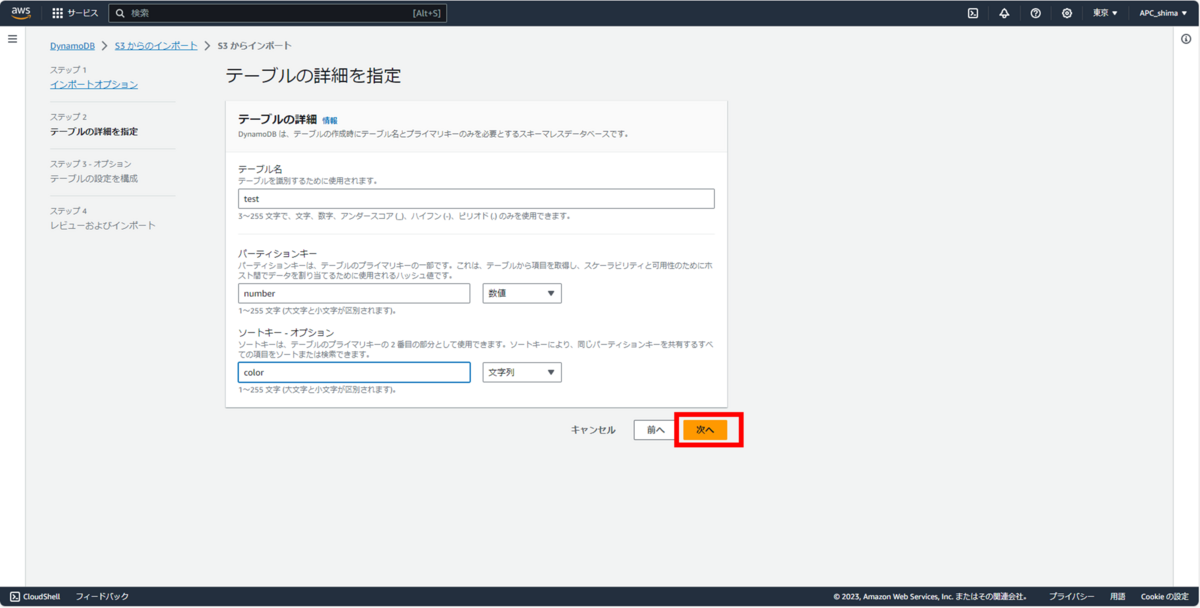
新規テーブル作成。
インポート
いざ!
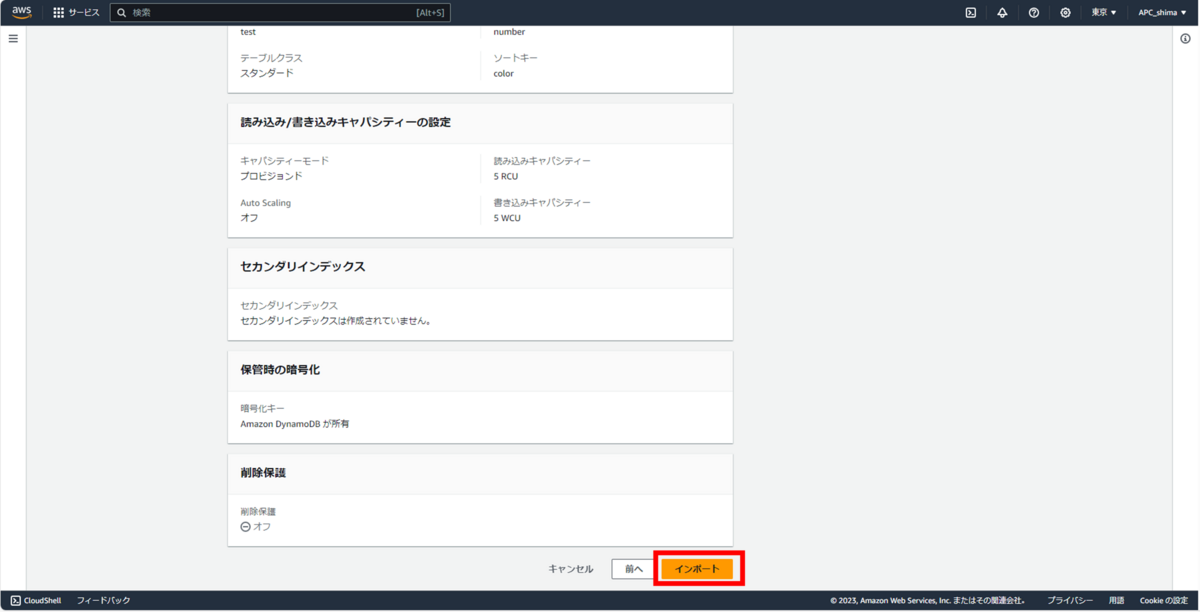
見事にエラー。(すこし変えて2回やったがだめ)

しかし、テーブルはできていた。(謎)

エラーのままのテーブルは使いたくないので、調査開始。
ひとまずCloudWatchLogsからエラーメッセージを確認する。
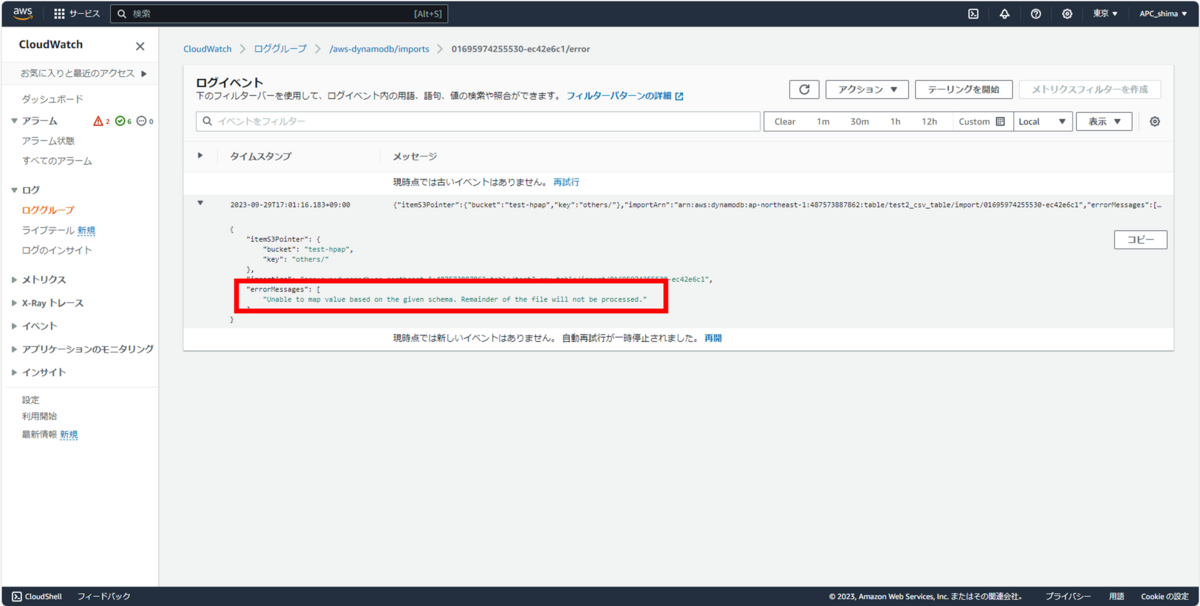
エラーメッセージでググったところ、早速同じ悩みの記事を発見。要約すると、
・S3はフォルダをネイティブにサポートしていないが、それを補うために、S3にフォルダを作成すると、0byteのオブジェクトとして作成される。
・S3へインポートする際、0byteのオブジェクトを読み込むことによって、エラーが出る。
と、ざっくりいうとそういうことらしい。

そういうことであれば、新規バケット作成し、読み込ませたいCSVのみを配置すればいけるのでは?!と思い、早速試してみる。まずは新規バケット作成。
新規バケットにファイルを単品で配置。

新規バケットを指定して、改めてアップロード。
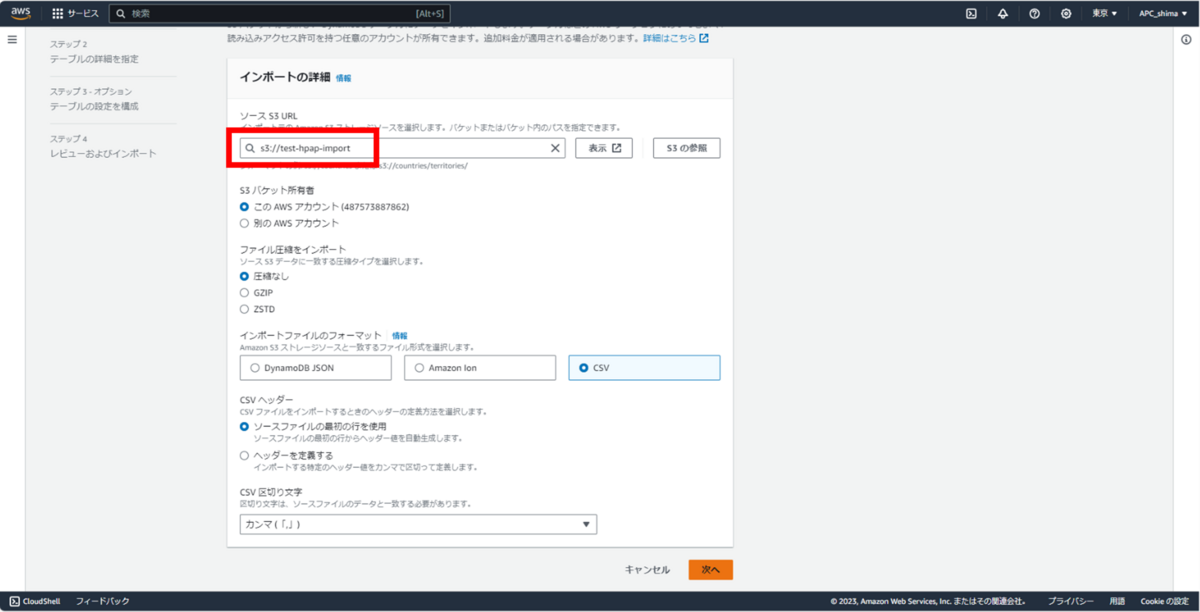
成功!!
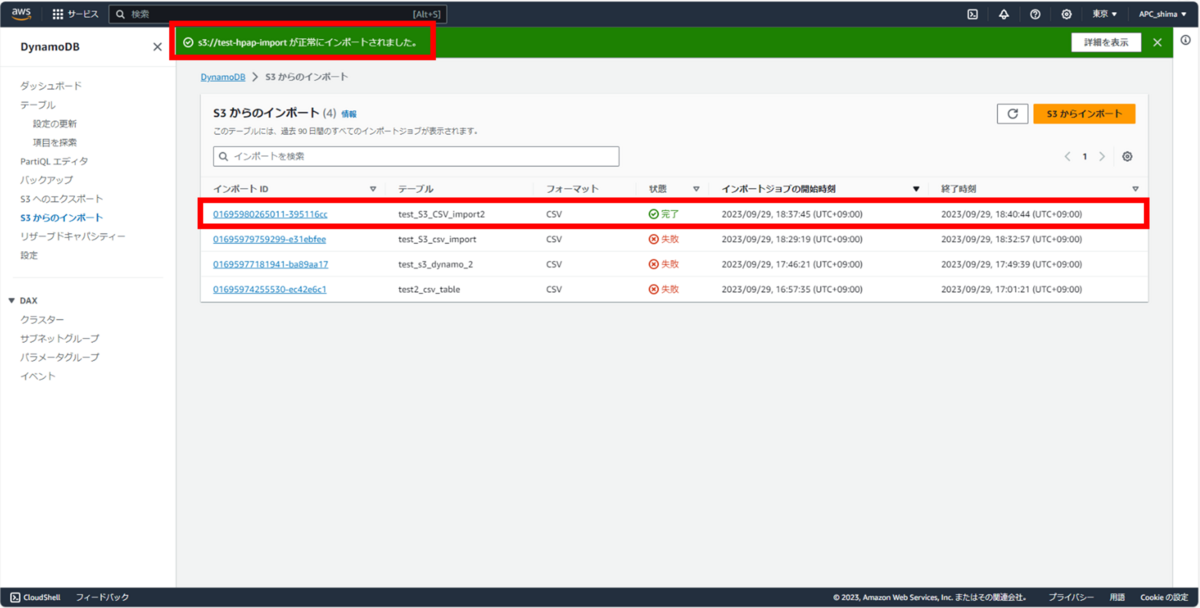
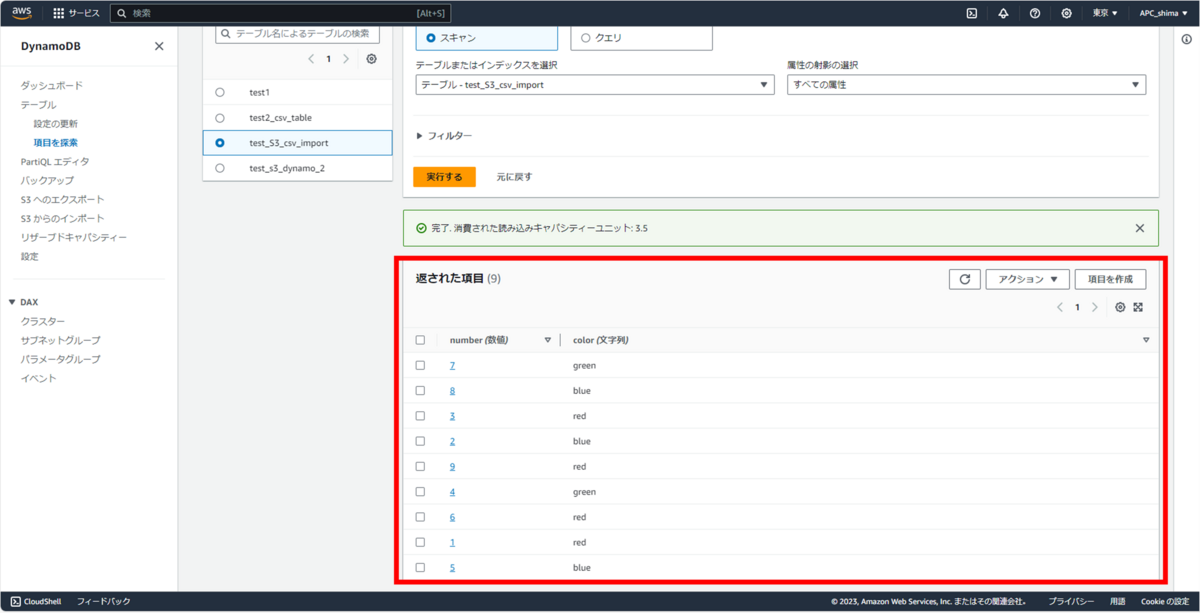
テーブルも問題なく作成されている。
まとめ
思わぬところでエラーを踏みましたが、S3の仕様など、学ぶところが多かったです。
ググっているうちに知ったことも含め、
・S3のフォルダの存在が、読み込みエラーの要因になることがある。
・S3からCSVをインポートする際、パーティションキーやソートキーは、指定したデータ型で取り込まれるが、それ以外は全て文字列型で取り込まれる。(ググって知りました)
を、今回学べました。

★参考★
DynamoDB の S3 インポート機能は CSV の場合だとすべて文字列型で取り込まれてしまう | DevelopersIO (classmethod.jp)
最後に
S3経由のCSVはお手軽にインポートできる分、S3におけるフォルダ関連エラーの可能性や、キー以外の型について指定したい場合はひと手間かかるということで、やはり用途に応じて、JSONの直接取り込みとの使い分けになっていくのかなと思います。
読んでいただき、誠にありがとうございました。