Databricks Unity Catalogで実現する、次世代のApache Iceberg活用術
先日開催されたDatabricksのセッション「Databricks + Apache Iceberg™: Managed and Foreign Tables in Unity Catalog」では、現代のレイクハウスアーキテクチャにおける重要な課題、すなわち「どのApache Icebergカタログを選択すべきか」という問いに対する一つの明確な答えが示されました。本記事では、このセッションの内容を基に、Icebergカタログ選定の要点と、Databricks Unity Catalogが提供する最新機能について解説します。

データレイクハウスの導入が進む中で、多くの企業がオープンなテーブルフォーマットとしてApache Icebergに注目しています。しかし、そのポテンシャルを最大限に引き出すには、エンジン、データ、そしてメタデータを繋ぐ「カタログ」の選択が極めて重要になります。セッションでは、架空の企業「ThunderMill」のエンジニア、Angelaが直面する課題を通して、この選択の難しさが描かれました。多様なエンジンとユースケースが混在する環境で、将来を見据えたアーキテクチャをどう構築すべきか。これは多くの開発者が共感する悩みではないでしょうか。
Apache Icebergとカタログの役割
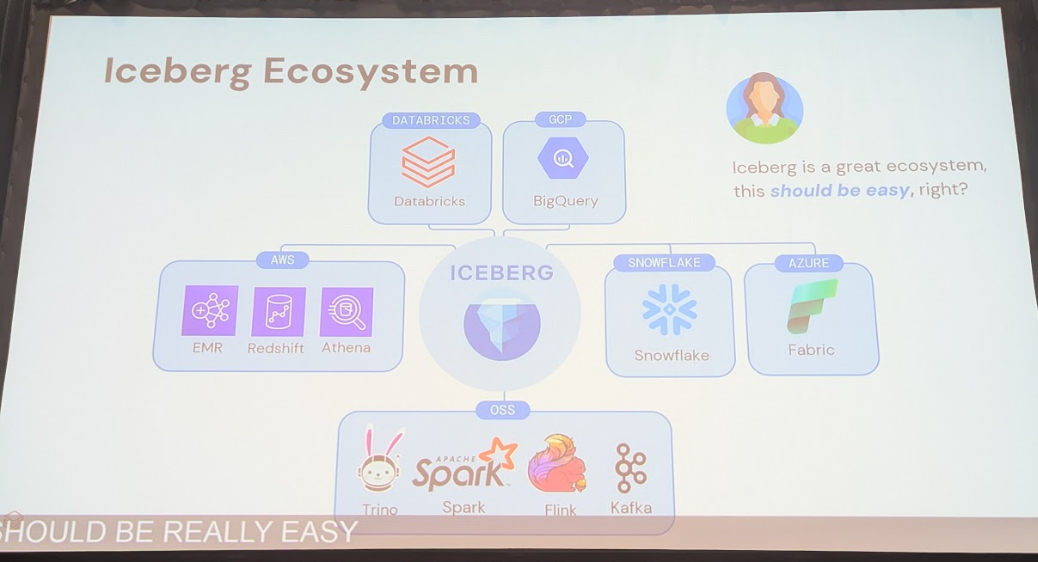
本題に入る前に、Apache Icebergの基本について簡単におさらいしておきましょう。Icebergは、大規模データレイク向けのオープンなテーブルフォーマットです。その最大の特徴は、データファイルとは別にメタデータを管理する点にあります。
このアーキテクチャの中心に位置するのが「Icebergカタログ」です。カタログは、テーブルの作成や削除、名前の変更といった管理操作を担うメタデータレイヤーです。すべての読み書き操作はカタログを経由して行われるため、カタログの選択はシステム全体のパフォーマンス、互換性、そして将来の拡張性に影響します。
特に、エンジン間の互換性を確保する上で注目されるのが「Iceberg REST Catalog API」というオープンなAPI仕様です。この仕様に準拠することで、さまざまなエンジンから統一的なインターフェースでカタログ操作を行うことを目指しています。
Icebergカタログ選定の3つの基準
セッションでは、乱立するカタログの中から最適なものを選ぶための3つの重要な判断基準が提示されました。これらは、単一のプラットフォームに縛られず、オープンで高性能なレイクハウスを構築する上で欠かせない視点です。

1. 外部エンジンからの完全な読み書きアクセス
真にオープンなカタログは、あらゆるエンジンからの読み書きをサポートし、ベンダーロックインを回避します。2. 高度なテーブル自動最適化
優れたカタログは、アクセスパターンを分析し、ファイルのコンパクションやデータレイアウトの最適化を自動的に行う機能を備えています。3. カタログ間の相互運用性
異なるカタログをフェデレーションで連携させることで、単一の窓口からすべてのデータにアクセスし、一元的なガバナンスを実現できます。
Databricks Unity Catalogのアプローチ

Databricksは、これらの3つの基準を満たすソリューションとして、Unity CatalogにおけるIcebergサポートの強化を発表しました。その中核をなすのが「Managed Iceberg Tables」と「Foreign Iceberg Tables」という2つの新しい機能です。
Managed Iceberg Tables: オープン性と統一管理

Managed Iceberg Tablesは、Unity Catalog内で作成・管理されるIcebergテーブルです。Databricksは、この機能がIceberg REST Catalog APIに準拠している点を強調しており、プラットフォーム上で統一的なデータ管理を実現します。
Foreign Iceberg Tables: 既存資産とのシームレスな連携

Foreign Iceberg Tablesは、AWS GlueやHive Metastoreといった外部のカタログで管理されているIcebergテーブルを、Unity Catalogから読み取り専用で参照する機能です。これはLakehouse Federationによって実現され、既存のワークロードを中断せずに高度なガバナンス機能(詳細なアクセス制御、データリネージなど)を適用できます。
Predictive OptimizationとLiquid Clusteringによる自動最適化
Unity Catalogは、テーブルの自動最適化機能も提供します。

Predictive Optimization
テーブルへのアクセスパターンを分析し、最適化の推奨や自動実行をサポートします。Liquid Clustering
従来の静的なパーティショニングに代わり、データの分布に応じてクラスタリングキーを動的に調整する機能を提供します。最適化されたデータレイアウトはIcebergの標準的なメタデータに反映されるため、Databricks以外のエンジンからも読み取り可能です。
他カタログとの比較
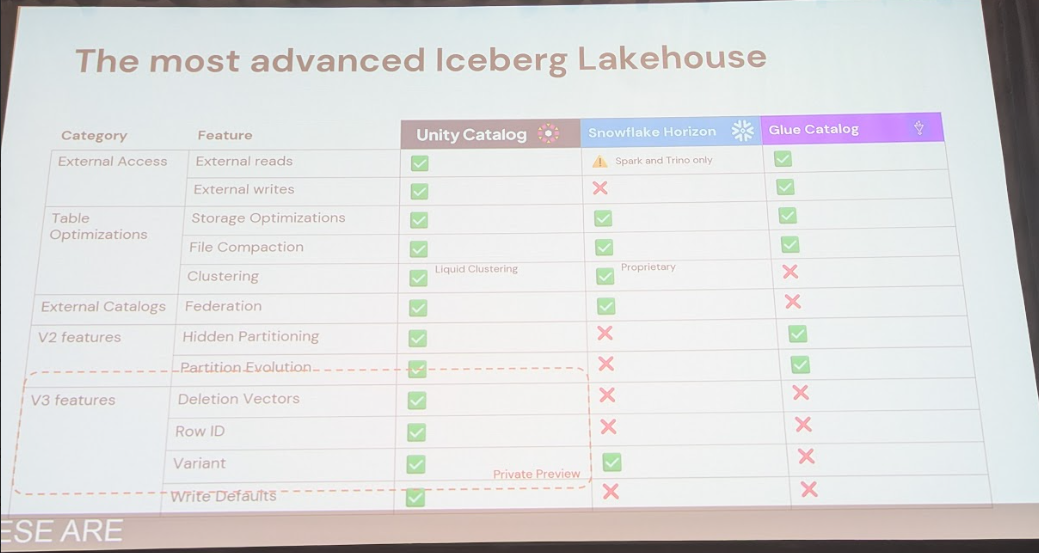
セッションでは、Snowflake HorizonやオープンソースのGlueといった他のカタログとの比較も行われました。例えば、Snowflake Horizonは外部エンジンからの書き込みに制約があると指摘されました。Unity Catalogは、REST Catalog準拠とLakehouse Federationにより、オープン性、最適化、相互運用性の3つの基準を高いレベルでバランスさせています。
デモ:Iceberg V3のVariant型で半構造化データを扱う

デモでは、Managed Iceberg Tableの作成がCREATE TABLE ... USING icebergとするだけでシンプルに行える点が示されました。特に、今後サポートされるIceberg V3の新機能「Variant型」は、JSONのような半構造化データをネイティブに扱うためのデータ型です。ユーザープロファイルのJSONデータをVariant型として格納し、特定のキー(user_id)を高速に抽出する様子が実演されました。
将来展望とまとめ

Databricksは、Iceberg V3で導入されるDeletion VectorsやRow IDsといった機能にも追随していくと表明しており、Icebergコミュニティの進化に合わせてプラットフォームを強化する姿勢がうかがえます。
今回のセッションを通じて明らかになったのは、Icebergカタログの選択が、単なる技術選定ではなく、データアーキテクチャ全体の柔軟性、パフォーマンス、そして将来性を決定づける戦略的な意思決定であるということです。
講演で示された3つの基準—「完全なオープン性」「高度な自動最適化」「カタログ間の相互運用性」—は、これからIcebergの導入を検討するすべての人にとって重要な指針となるはずです。Databricks Unity Catalogは、これらの基準に対して包括的なソリューションを提供しており、Managed/Foreign Iceberg Tablesはオープンなレイクハウス構築の有力な選択肢と言えるでしょう。
より詳細な情報に興味がある方は、公式ドキュメントを参照したり、実際にプラットフォームを試してみることをお勧めします。あなたのデータ戦略に、新たな可能性が開けるかもしれません。