
- はじめに
- 特徴量管理の課題
- Feature Storeとは
- Feature Storeの利点
- Databricks Feature Store
- Feature Table作成までの手順
- データの前準備
- Delta Tableを作成する
- Feature Tableを作成する
- Feature Tableを上書きする
- タグ付きのFeature Tableを作成する
- Feature Tableにタグを追加する
- Feature Tableのタグの削除
- 既存のDeltaテーブルをFeature Tableとして登録する
- Feature Tableを削除する
- 参考記事
- おわりに
はじめに
GLB事業部Lakehouse部の阿部です。
本記事では、Feature Storeの歴史とDatabricks Feature Storeの機能をノートブックを通じて解説したいと思います。
データ分析には、既存の特徴量から新たな特徴量を作成する「特徴量エンジニアリング」の工程がありますが、特徴量の管理は煩雑になりがちです。
かく言う私も過去に作成した特徴量は、どのようなロジックで作成したか忘れることや、誤ってテーブルデータから特徴量を削除してしまったときに、特徴量の復元に労力をかけたことがあります。
そのような課題を解決してくれるFeature Storeについて解説します。
特徴量管理の課題
Feature Storeについて解説する前に、機械学習システム構築やデータ分析における特徴量管理の課題について説明します。
MLモデルの学習に使う特徴量の管理は、時間の経過やメンバーが増えると管理が煩雑になり、大きく分けて下記のような課題が生まれます。
特徴量作成のコストがかかる
組織内で過去に作成された特徴量があれば再利用できますが、特徴量が一元管理されていないと新たに作成する必要があります。過去に作成した特徴量がいつ、どのように作成されたか不明
特徴量がいつ、誰が、どのようなロジックで作成したか管理できず、特徴量作成が属人化します。
そのため、過去に作成された特徴量を再現するのは困難になり、コストがかかります。学習時と推論時の特徴量に整合性がない
多くの場合、学習と推論(モデルサービング)のタイミングが異なり時間的に切り離されるケースが多々あります。
そのため、学習と推論のそれぞれの時点でモデルに入力される特徴量が異なり、学習で高いパフォーマンスを出したモデルが推論時に精度低下の可能性があります。
これでは、予測の信頼性が低下してしまいます。
Feature Storeとは
以上のような課題を解決したのがFeature Storeです。
最初のパブリックフィーチャーストアであるMichelangelo Paletteは、2017年にUberによって発表されました。
それ以来、ビッグテック企業等が参入しFeature Storeと同等のものを提供している企業や、Feature Storeを内製化している企業もあります。
Feature Storeは以下に示すように、特徴量エンジニアリングからモデルの学習と評価、推論、モニタリングの全フェーズにおいて特徴量を参照または登録し、特徴量を一元管理できるプラットフォームとして機能します。
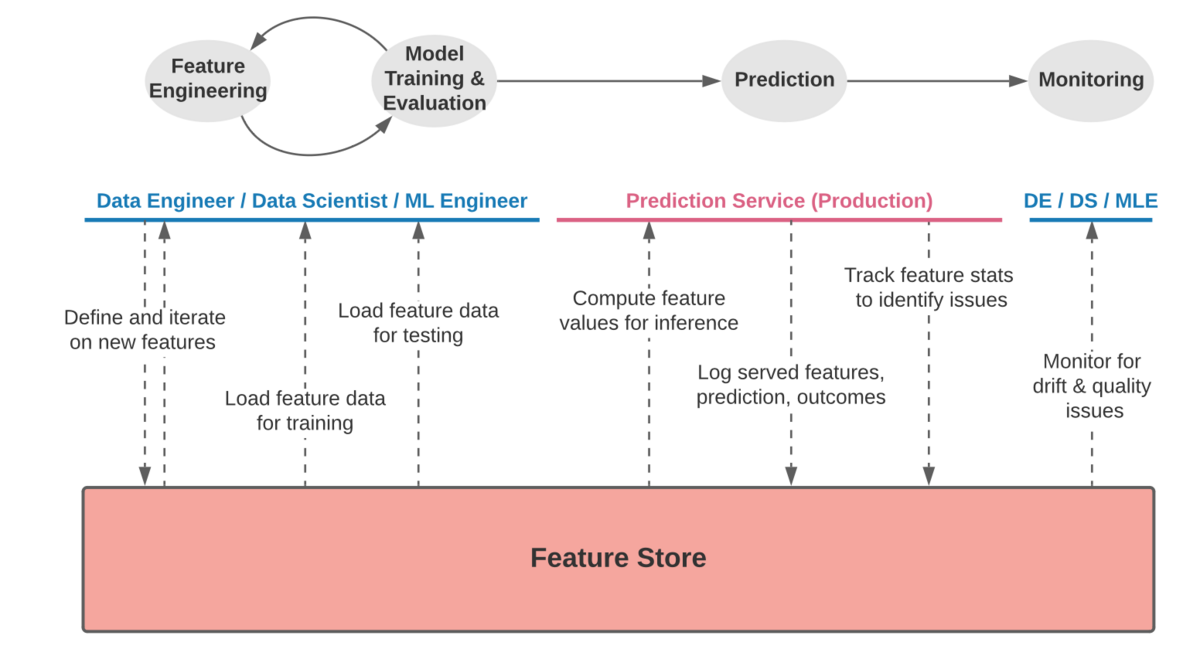
(https://feast.dev/blog/what-is-a-feature-store/のEnter the feature storeから一部引用)
このように特徴量を一元管理することで、特徴量エンジニアリングと推論時の課題を解決し、モデルドリフトやモデル品質のモニタリングにおいても特徴量のチェックができます。
Feature Storeの利点
Feature Storeを利用することで、先ほど挙げた特徴量管理における課題を解決できます。
次にFeature Storeを利用する利点について述べます。
特徴量の再利用
作成した特徴量をFeature Storeに登録することで、チーム間で特徴量の再利用が可能となります。
そのため、作成済みの特徴量あればデータサイエンティストは特徴量作成のタスクに追われることなく、MLモデルをすぐに作成できます。チーム間での共同利用
前の利点と似ていますが、特徴量を一元管理できるFeature Storeというプラットフォームによって、チーム間での特徴量を共有した開発や保存、そして変更や再利用が容易にできます。特徴量の一貫性を担保する
Feature Storeに登録された特徴量から、特徴量作成のロジックを理解できます。学習時と推論時の特徴量を揃える
学習時と推論時それぞれにおいて、Feature Storeに登録されている特徴量を使用することで学習時に出した高いモデルパフォーマンスの維持に貢献します。データガバナンスの強化
Feature StoreによってMLモデルごとに、どの特徴量を用いて学習したか特定できます。
また、ユーザー毎にFeature Storeのアクセス制御が可能となることで、データガバナンスの強化になります。
Databricks Feature Store
Databricks Feature Storeのワークフローを以下に示します。
- ソースデータから生データをSpark DataFrameとして読み込む
- Spark DataFrameをFeature storeに出力する
- Feature Storeに登録されている特徴量を使用してモデルの学習を行う
- モデルレジストリにモデルを登録する
バッチ処理の場合は、Feature Storeの特徴量を自動で取得します。
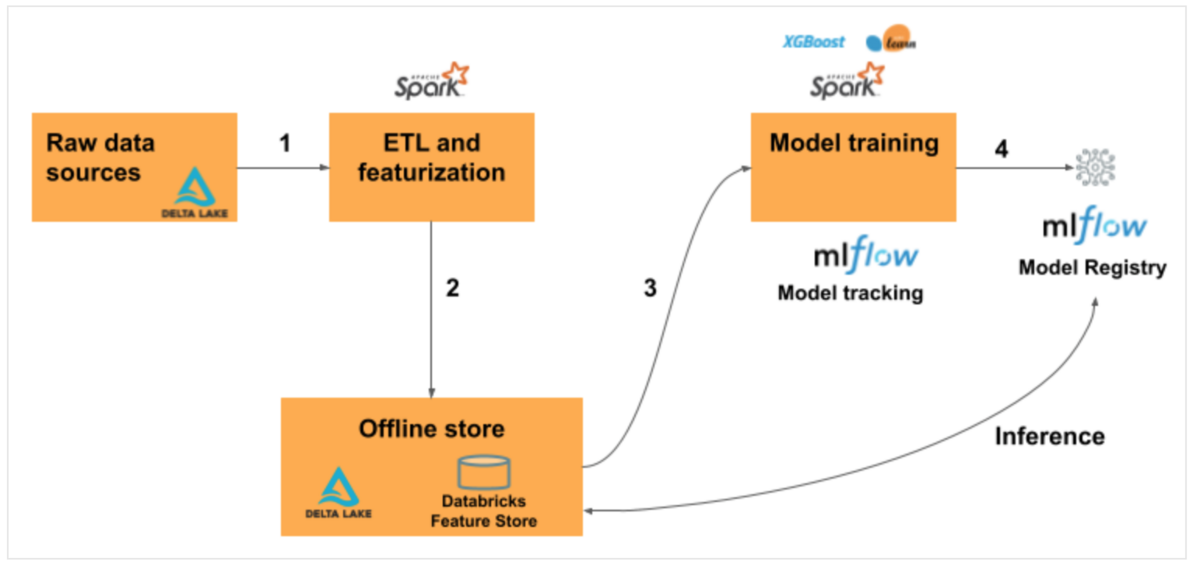
リアルタイム推論のユースケースではオンラインストア使用しますが、本記事では扱いません。
気になる方は、Azureの公式ドキュメントをご参照ください。
本記事では、Feature Storeへの出力までを解説します。
Feature Table作成までの手順
おさらいですが、Feature Table作成までの手順を以下に示します。
- 手順1. Spark DataFrameの前準備
- 手順2. 作成したSpark DataFrameを用いてDelta Tableを作成
- 手順3. Delta TableからSpark DataFrameを読み込む
- 手順4. 読み込んだSpark DataFrameをFeature Storeに出力
手順2〜3を踏まずSpark DataFrameをそのままFeature Storeに出力できますが、Feature Tableに蓄積したデータからFeature Storeに出力する運用の方法に準じ、Delta Tableの作成も挟むことにします。
データの前準備
まずはデータを準備します。
今回は、scikit-learnのデータセットからカリフォルニアの住宅価格のデータセットを使用します。
こちらは1990年の米国国勢調査で得られた、1990年のカリフォルニアにおける住宅価格のデータです。
from sklearn.datasets import fetch_california_housing import pandas as pd df = fetch_california_housing(as_frame=True) # カリフォルニアのデータセットを読み込む train_X = df.data # 説明変数(特徴量)のデータ train_y = df.target # 目的変数のデータ data = pd.concat([train_X, train_y], axis = 1) data.head(3)

Feature Storeに出力するData Frameは、primary keyを持つApache Spark DataFrameの必要があるため、 primary keyを作成しSpark Dataframeに変換します。
# 1から連番のidカラムを作成する data['id'] = range(1, len(data.index) + 1) # idカラムを先頭に持ってくる first_column = data.pop('id') data.insert(0, 'id', first_column) house_df = spark.createDataFrame(data) display(house_df)
作成したSpark DataFrameを表示します。

Delta Tableを作成する
作成したSpark DataFrameを用いてDelta Tableを作成します。
table_name = "california_house" (house_df.write .format("delta") .saveAsTable(table_name))
Delta Tableを作成しました。
データエクスプローラーからも確認できます。
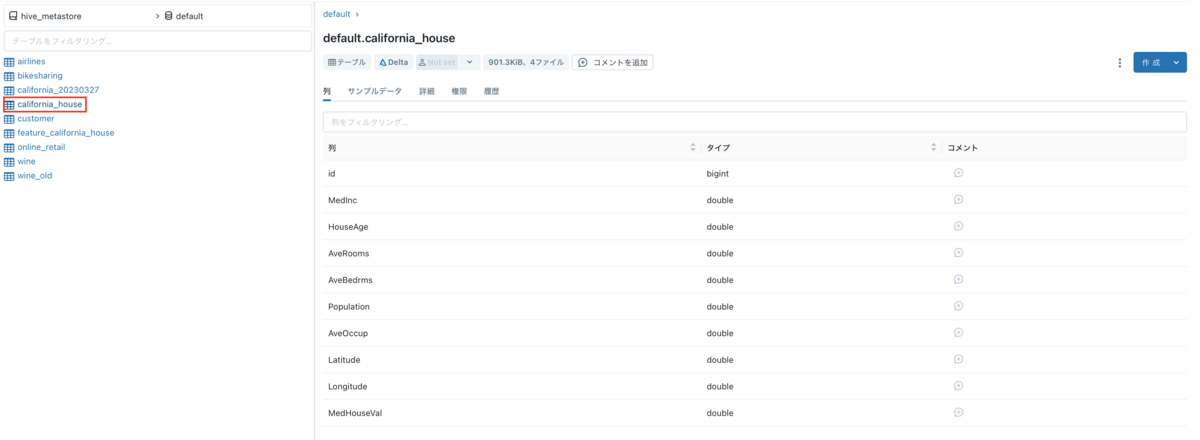
Feature Tableを作成する
Delta TableからSpark DataFrameを読み込みます。
delta_df = (spark.read.table('default.california_house')
読み込んだSpark DataFrameでFeature Tableを作成します。
先ほど作成した"id"をprimaryキーに設定し、パーテションキーを"Latitude"にします。
from databricks import feature_store fs = feature_store.FeatureStoreClient() feature_table_name = "feature_california_house" fs.create_table( name = feature_table_name, primary_keys = ["id"], df = delta_df, partition_columns = ["Latitude"], description = "california houses data" )
create_featureの各オプションは、以下の通りです。
- name: Feature Storeに作成するFeature Tableの名前
- primary_keys: プライマリキー
- df: Spark DataFrame
- partition_columns: パーティションキー
- timestamp_keys: 時間情報を持つカラム(日付、時間など)
- description: Feature tableの説明
このデータセットは時系列データではないためtimestamp_keysは指定しませんが、時系列データの場合は時間情報を持つカラムを指定します。
Feature Storeのメタデータを取得します。
メタデータの取得は、fs.get_table(Feature Storeのテーブル名).descriptionで実行します。
print(f"Feature table description : {fs.get_table(feature_table_name).description}") print(f"Feature table data source : {fs.get_table(feature_table_name).path_data_sources}")
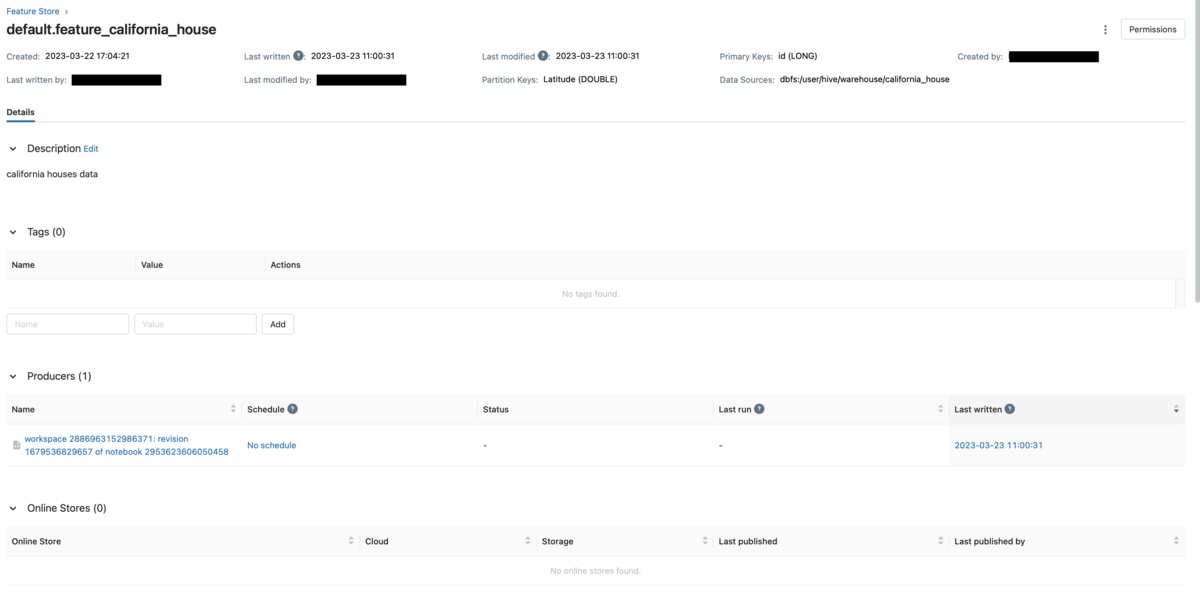
作成したFeature TableをFeature StoreのUIから確認します。
Machine Learningのワークスペースに移動しサイドバーのFeature Storeをクリックすると、Feature Table一覧が表示されます。
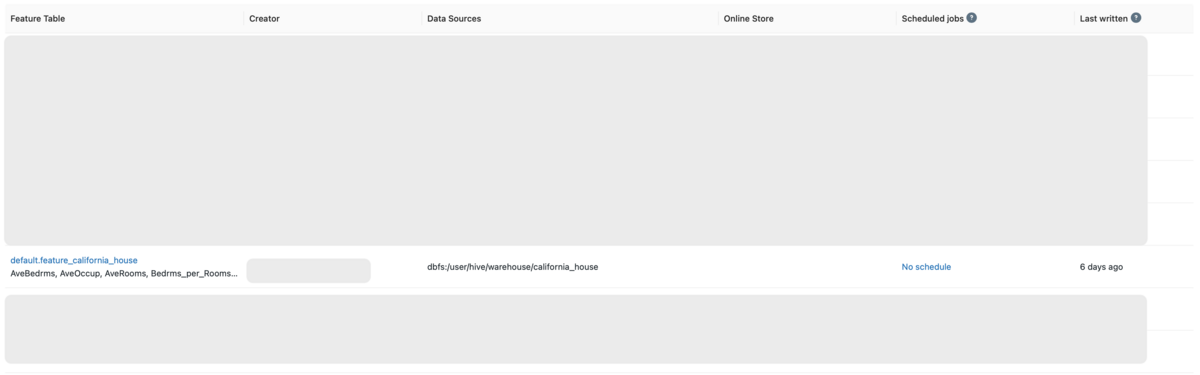
Feature Table名をクリックすると、Feature Tableの詳細情報が表示されます。
いつ作成し、最後に誰がいつ更新したか、どのDelta Tableから作成したかわかるため、データガバナンスの強化に繋がります。
スクロールすると、特徴量が表示されます。
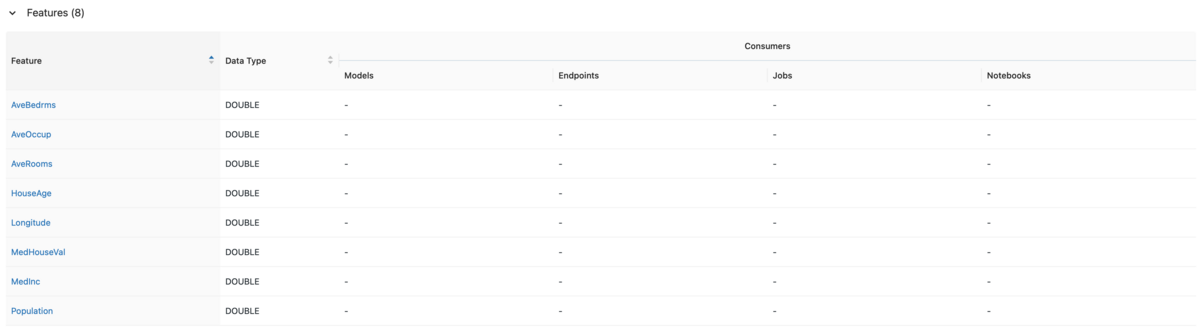
※目的変数も一緒に出力していますが、学習時にはFeature Tableからデータを読み込んで説明変数と目的変数を分離する流れとなります。
Feature Tableを上書きする
Spark DataFrameに新しいカラムを追加します。
ここでは、部屋毎のベッド数を計算したBedrms_per_Roomsというカラムを作成します。
drop_columns = ['AveBedrms', 'AveRooms'] delta_df_new = (delta_df.withColumn('Bedrms_per_Rooms', delta_df['AveBedrms'] / delta_df['AveRooms']) .drop(*drop_columns) )
Feature Storeへの出力はwrite_tableで実行します。
modeオプションにoverwriteを指定することで、Feature Storeの上書きをします。
fs = feature_store.FeatureStoreClient() feature_database = "default" feature_table_name = f"{feature_database}.california_house" fs.write_table(name = feature_table_name, df = delta_df_new, mode = "overwrite")
Feature StoreのUIに移動します。
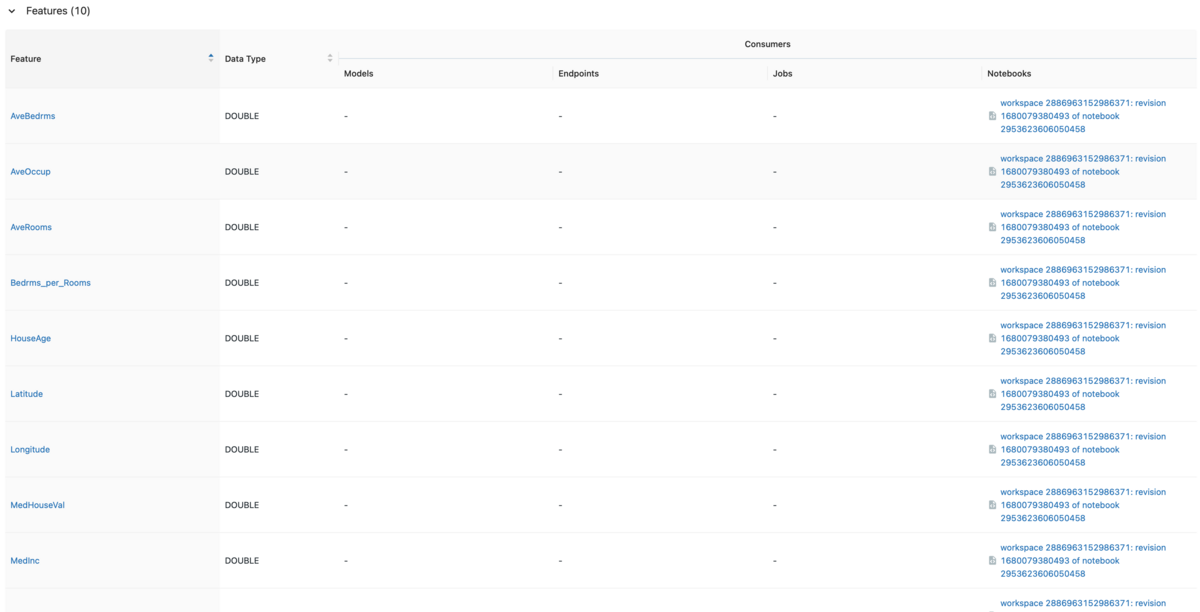
削除したカラム(AveBedrms, AveRooms)はテーブルのスキーマには残っていますが、fs.read_tableでFeature Tableを読み込むと、値がnullに置き換えられていることがわかります。
feature_df = fs.read_table(
name = feature_table_name)
display(feature_df)

ちなみに、カラム削除前のFeature Tableを読み込むためにas_of_delta_timestampに昨日の時間を指定します。
as_of_delta_timestampに時間を指定することで、その時間時点でのFeature Tableを読み込むことができ、Delta Lakeのタイムトラベルが可能です。
import datetime yesterday = datetime.date.today() - datetime.timedelta(days = 1) fs = feature_store.FeatureStoreClient() feature_database = "default" feature_table_name = f"{feature_database}.california_house" feature_df = fs.read_table( name = feature_table_name, as_of_delta_timestamp = yesterday )
タグ付きのFeature Tableを作成する
Feature Storeにタグを付与することで、Feature Store内での検索に便利です。
タグ付きのFeature Tableを作成するには、create_table実行時にtagsを指定します。
先ほどはDefaultのデータベースにDelta Tableを作成してましたが、本来はFeature Table用のデータベースの作成がベストプラクティスであるため、california_dbというデータベースを作成します。
CREATE DATABASE IF NOT EXISTS california_db
タグつきのFeature Tableを作成します。
feature_database = "california_db" feature_table_name = f"{feature_database}.california_tag" fs.create_table( name = "california_tag", primary_keys = ["id"], df = delta_df, partition_columns = ["Latitude"], tags = {"california_house_dataset_1": "house_price", "california_house_dataset_2": "Bedrms_per_Rooms"}, description = "california houses data" )
tagオプションには、キーと値がペアのタグを辞書式で入力します。
Feature StoreのUIに移動後、california_tagというテーブルを確認できます。
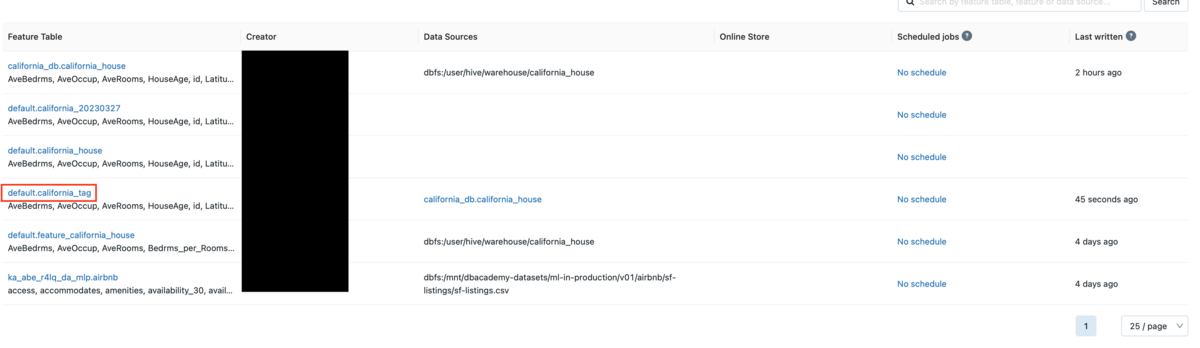
テーブル名をクリック後、タグの一覧を確認します。
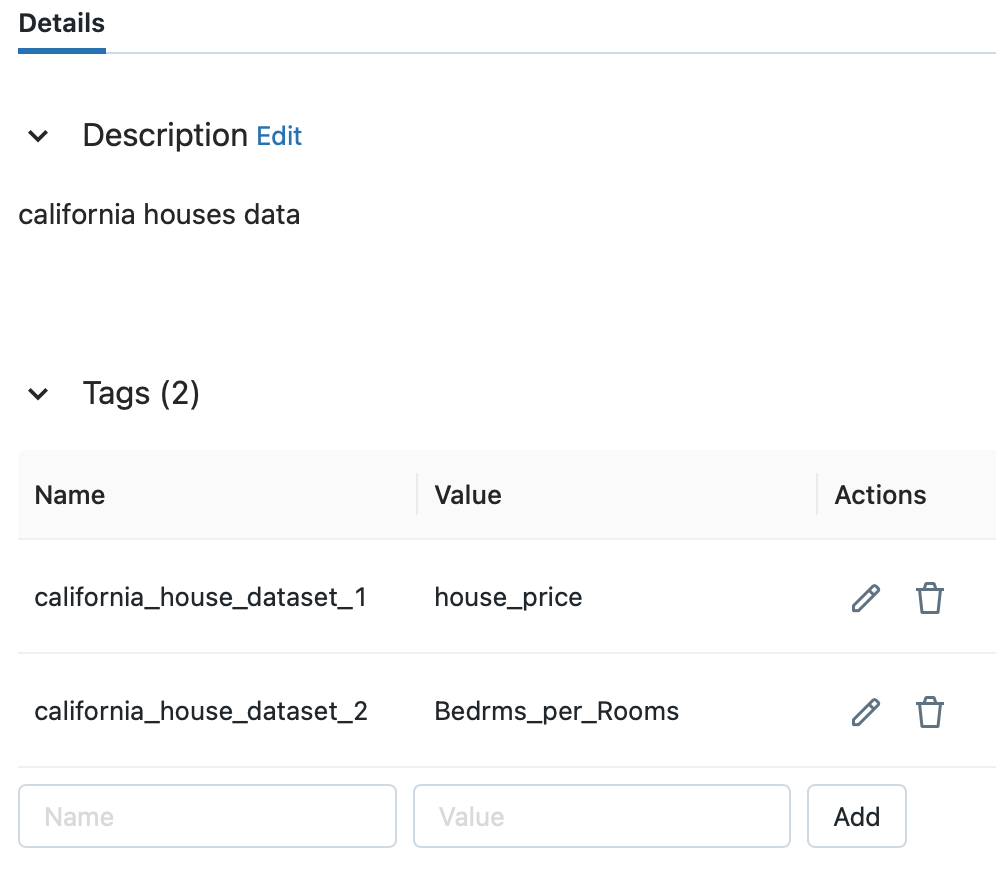
先ほど入力したタグが付与されていることを確認できました。
Feature Tableにタグを追加する
Feature Store Python APIを使用してFeature Tableにタグを追加できます。
table_nameにはタグを追加するFeature Tableを指定し、タグはkeyとvalueのセットで設定します。
FeatureStoreClient()のset_feature_table_tagメソッドを使用してタグを追加します。
fs = feature_store.FeatureStoreClient() fs.set_feature_table_tag(table_name = 'california_tag', key = 'california_house_dataset_3', value = 'Population')
Feature Storeからタグを追加したFeature Tableを選択します。
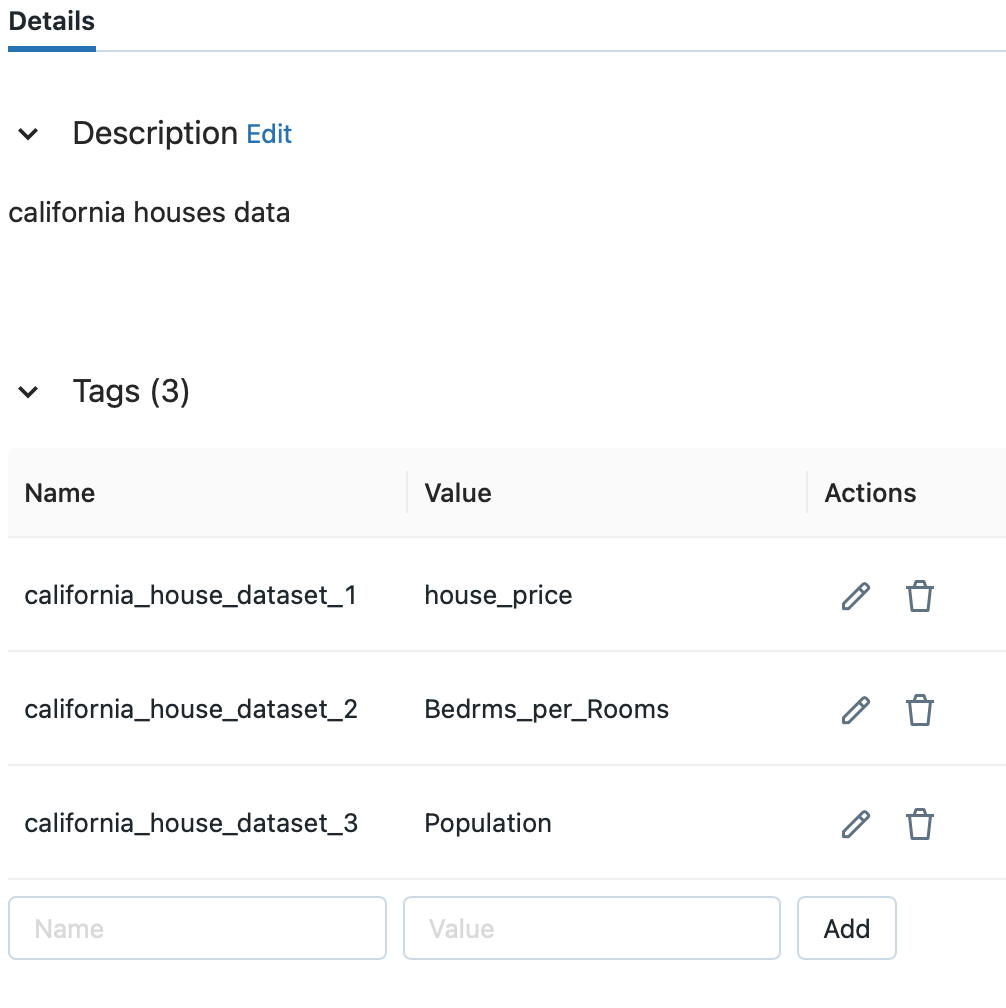
タグが追加されていることが確認できます。
例として、Feature Table一覧からタグを追加したcalifornia_db.california_houseを表示したいとします。
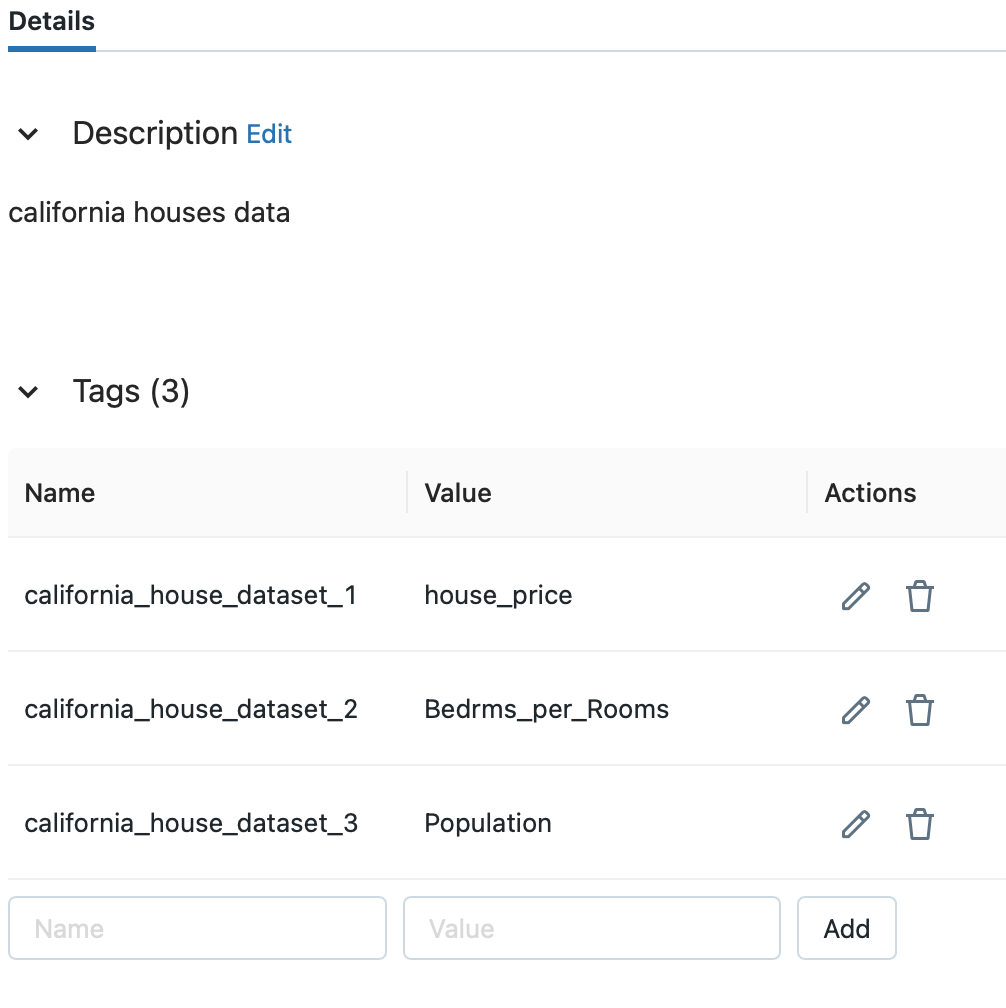 Feature Table一覧には、スキーマは異なりますが同じテーブル名が表示されていることがわかります。
Feature Table一覧には、スキーマは異なりますが同じテーブル名が表示されていることがわかります。
とくに似たようなテーブル名が多くある場合は、タグによる検索は力を発揮します。
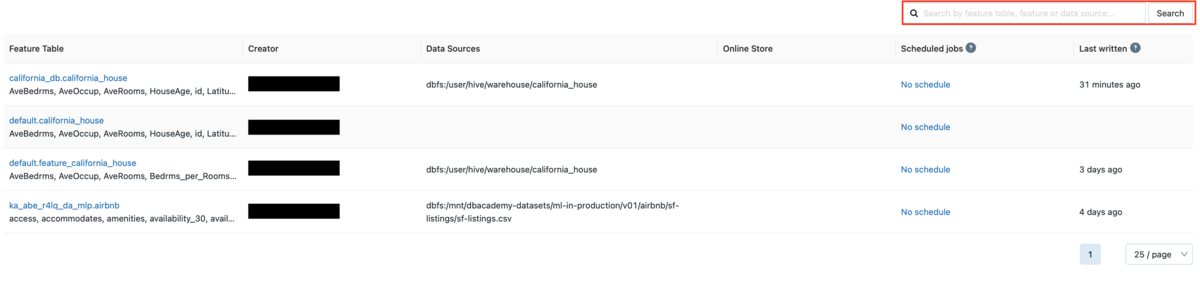
検索フィールドに追加したタグでのキーまたは値を入力します。
ここでは、タグのキーであるcalifornia_house_dataset_3を入力します。

タグを追加したFeature Tableのみ表示されていることが確認できます。
タグの追加は、Feature StoreのUIでも可能です。
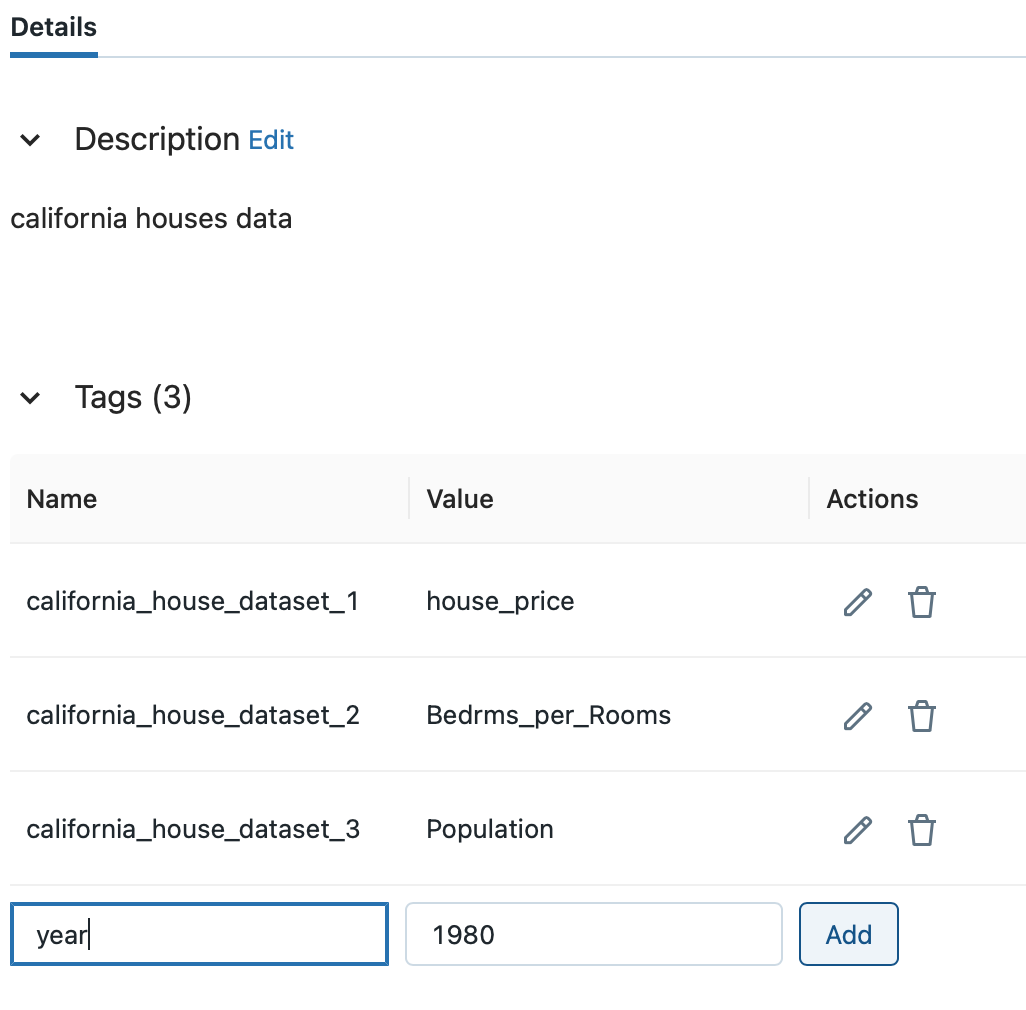
タグ一覧からName、Valueフィールドにそれぞれキーと値を入力後、Addボタンをクリックします。
Feature Tableのタグの削除
タグの削除はFeatureStoreClient()のdelete_feature_table_tagメソッドを使用します。
fs = feature_store.FeatureStoreClient()
fs.delete_feature_table_tag(table_name = feature_table_name, key = 'california_house_dataset_3')
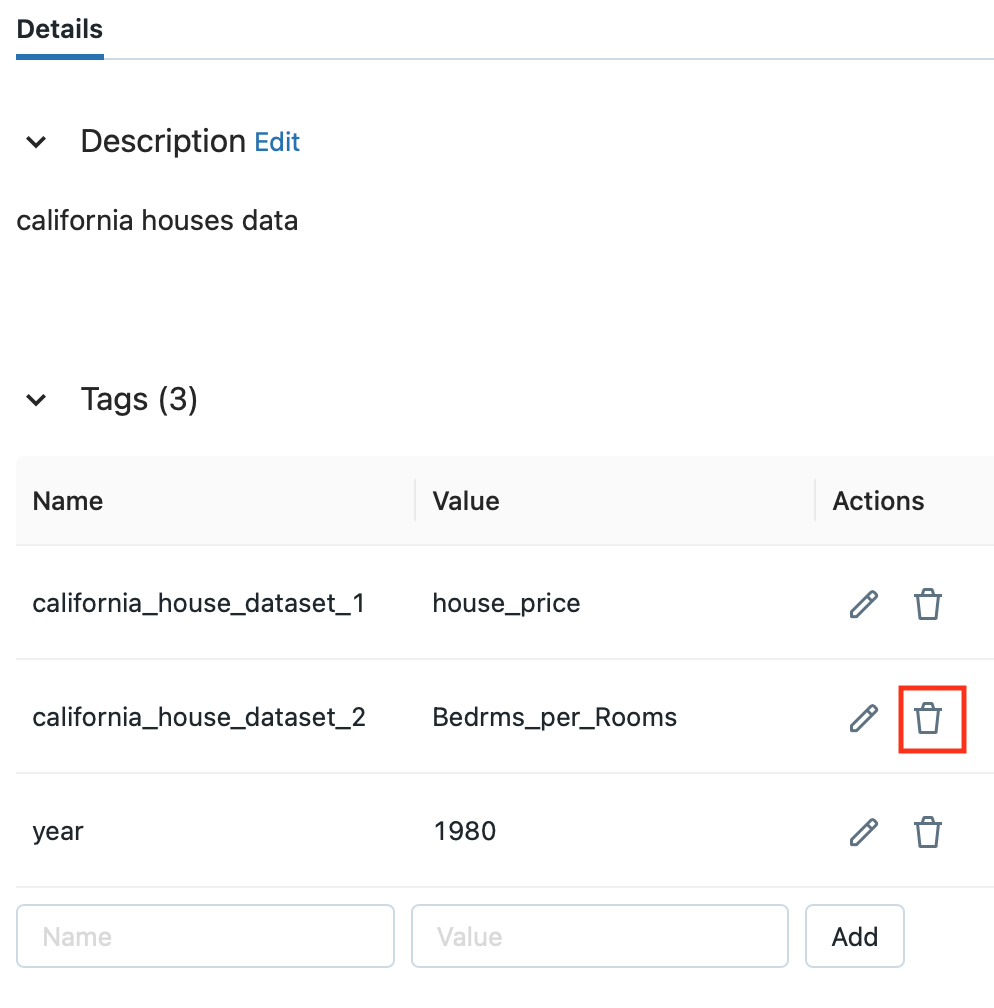
Feature StoreのUIでもタグの削除が可能です。
Actions列のゴミ箱アイコンをクリックするとタグが削除されます。
既存のDeltaテーブルをFeature Tableとして登録する
DataFrameを読み込み、Delta Tableとして出力し、Feature Storeに出力するという流れで説明しました。
これまでの処理を振り返ると、以下の流れになっています。
- 手順1. Spark DataFrameの前準備
- 手順2. 作成したSpark DataFrameを用いてDelta Tableを作成
- 手順3. Delta TableからSpark DataFrameを読み込む
- 手順4. 読み込んだSpark DataFrameをFeature Storeに出力
ここからは、手順3を踏まずに既存のDelta tableをFeature Storeに登録する方法を紹介します。
本来ならば、作成済みのDelta TableからFeature Storeに出力する処理をすぐに実行したいですが、カリフォルニアの住宅のデータセットと区別するために、別のデータを用意して手順1から行います。
データはDBFS(Databricks File System)のサンプルデータを使用します。
/databricks-datasetsのパスに存在します。
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/online_retail/data-001/data.csv") display(df)

こちらのデータは、イギリスを拠点としたオンラインストアのトランザクションデータです。
primary keyを作るため、連番のIDカラムを追加します。
from pyspark.sql.functions import monotonically_increasing_id #IDを連番で振る df_id = df.withColumn('ID', monotonically_increasing_id() + 1)
次に、読み込んだSpark DataFrameを時系列データとして扱うためtimestamp_keyを指定します。
timestamp_keyには、timestamp型もしくはDate型のカラムオブジェクトを指定する必要があるため、InvoiceDateカラムのデータ型をstring型からtimestamp型に変換します。
from pyspark.sql.functions import * df = df.withColumn("InvoiceDate", to_timestamp(col("InvoiceDate"), 'M/d/y H:m'))
Delta Tableを作成するスキーマを指定します。
%sql
USE SCHEMA default
Delta Tableを作成します。
table_name = "online_retail" (df_id.write .format("delta") .saveAsTable(table_name))
前準備が長くなりましたが、作成したDelta TableからFeature Storeに出力します。
feature_database = "default" feature_table_name = f"{feature_database}.online_retail" fs.register_table( delta_table = feature_table_name, primary_keys = 'CustomerID', timestamp_keys = 'InvoiceDate', description = 'online_retail of England' )
サイドバーのFeature StoreからFearure Table一覧を確認します。
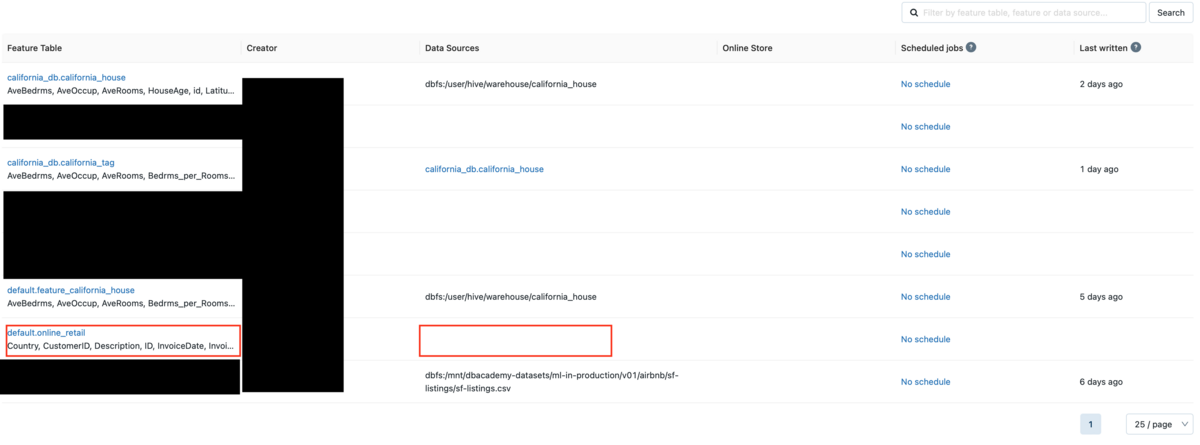
作成したdefault.online_retailというFeature Tableが確認できました。
Data Sourcesの欄をみると空欄になっていますが、既存のDelta TableからFeature Tableを作成するregister_tableを実行すると、ソースのDelta Tableが表示されません。
register_tableによって作成したFeature Tableのメタデータを確認します。
print(f"Feature table description : {fs.get_table(feature_table_name).description}") print(f"Feature table data source : {fs.get_table(feature_table_name).path_data_sources}")

データソースが表示されていないことがわかります。
Feature Tableを削除する
最後に、Feature Tableを削除して本記事を終わりたいと思います。
DROP TABLE IF EXIST テーブル名を実行します。
DROP TABLE IF EXISTS online_retail;
参考記事
- WHAT IS A FEATURE STORE IN MACHINE LEARNING?
- WHAT IS A FEATURE STORE by HOPSWORKS
- What is a Feature Store
- 特徴テーブルの操作
- Feature Storeについてふんわり理解する
おわりに
本記事では、特徴量管理の課題とその課題を解決するFeature Storeについて解説し、Databricks Feature Storeを使用した特徴量の管理方法について解説しました。
今後もDatabricksを用いた検証内容を投稿していきたいと思いますので、またご覧になっていただければと思います。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。