背景
GLE所属、林と申します。
Databricks Vector Search: 何、なぜ、どのように
Databricks Vector Search What, Why and How( Databricks Vector Search: 何、なぜ、どのように) - APC 技術ブログ
インスパイアされ ベクトルインデックスとベクトルサーチについての勉強を始めました。このブログに学んだことを記録していきたいと思います。
目標
ここでの主な目標は、次のスクリプトを開発することです:
- クエリテキスト(文字列)を受け取る
- クエリテキストをテキストデータベースと比較する
- 最も類似した上位k件のテキストを返す
また、いくつかの最適化手法も検討します。
手順
上記の目標を達成するために、スクリプトは以下の手順を実行します:
- テキストデータセットを収集する
- テキストをsentence-bertを使って対応する埋め込み(ベクトル)に変換する
- 文とそれに対応する埋め込みをDatabricksテーブルに保存する
- 埋め込みをFAISS(Facebook AI Similarity Search)でインデックス化する
- ステップ3で作成したベクトルインデックスを使用して、クエリテキストから類似テキストを検索する関数を定義する
- 異なる最適化手法を試す
ちなみに、このブログの内容はDatabricksを使用して実行しました。
実行
データセットを準備
最初のステップは、テキストデータセットを見つけることです。
少し調査した後、このデータセットを見つけました。larryvrh/WikiMatrix-v1-Ja_Zh-filtered これはHugging faceからのデータセットで、約69万件の日本語と中国語の文が含まれています。
文の数は適しており、日本語に集中したいので中国語の列を削除するだけで良いです。
from datasets import load_dataset
dataset = load_dataset("larryvrh/WikiMatrix-v1-Ja_Zh-filtered")
train_dataset = dataset['train'] # this dataset only has a train split so this includes the whole dataset already
ja_dataset = train_dataset['ja']
ja_sentences = list(ja_dataset)
最初の10行を表示して、どのようなデータを取得しているか確認しましょう:
['神世(かみよ)現世と常世のすべて。',
'なんだ、あれがきっと僕たちのさがしていた青い鳥なんだ。',
"端役としてではないフリーマンの最初の出演作品は1971年公開の『WhoSaysICan'tRideaRainbow?",
'アッラーフは寛容にして慈悲深くあられる。',
'我々はみな同じ空気を呼吸している。',
"ボンメル・エンド・トンプス(TheDragonThatWasn't(OrWasHe?",
'偽使(ぎし)とは他人の名前を騙った偽の使節のこと。',
'アッラーが下されるものによって裁判しない者は,不義を行う者である。',
'ローマ三越開店。',
'4歳から8歳までの間に、4冊の本を執筆した。']
これはまさに求めていたものです。
文埋め込み (Sentence embedding)
次に、これらの文を埋め込み、つまりベクトルに変換します。
これはテキストの数値表現を見つけることを意味します。テキストをコンピューターが「理解できる」形で表現することです。
%pip install sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('bert-base-nli-mean-tokens')
sentence_embeddings = model.encode(ja_sentences)
これはすべての文をエンコードしますが、Databricksクラスターの分散コンピューティングを活用していないため、かなり時間がかかります。
UDFによるスピードアップ
より効率的な方法は、UDF関数(ユーザー定義関数)を利用することです:
%pip install sentence-transformers
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import ArrayType, FloatType
from sentence_transformers import SentenceTransformer
@pandas_udf(ArrayType(FloatType()))
def encode_sentences(sentences: pd.Series) -> pd.Series:
# Initialize model within the UDF to ensure it is available on all workers
model = SentenceTransformer('bert-base-nli-mean-tokens')
embeddings = []
for sentence in tqdm(sentences, desc="Encoding sentences"):
batch_embeddings = model.encode([sentence], show_progress_bar=False)
embeddings.extend(batch_embeddings.tolist())
return pd.Series(embeddings)
encoded_df = spark_df.withColumn("embedding", encode_sentences("sentence"))
result_df = encoded_df.toPandas()
paraphrase_minilm_l3_v2_embeddings = np.array(result_df["embedding"].tolist())
エンコード後、sentence_embeddings.shapeを使用してsentence_embeddingsの形状を表示できます。すると、(690095, 768)と表示されます。
これは、690095個のベクトルがあり、それぞれが690095の文に対応しており、各ベクトルの次元数は768であることを意味します。
文と埋め込みをDatabricksテーブルに保存する
その後、文と埋め込みをテーブルとして保存できます:
df = pd.DataFrame({
'sentence': ja_sentences,
'paraphrase_minilm_l3_v2_embeddings': [embedding.tolist() for embedding in paraphrase_minilm_l3_v2_embeddings],
'bert_base_japanese_embeddings': [embedding.tolist() for embedding in bert_base_japanese_embeddings]
})
spark_df.write.format("delta").mode("overwrite").saveAsTable("vector_search_sentences_and_embeddings")
p.s. 前述のsentence-bertとは別に、比較のためにMiniLMという別のモデルも使用しました。その埋め込みの次元数は384で、sentence-bertの半分です。
データセット全体を一気にテーブルに書き込もうとしたところ、だめでした。最終的には、forループを使ってバッチごとにテーブルに追加しました。
テーブルから文と埋め込みを読み込む
テーブルからノートブックに読み戻すには:
df = spark.table("vector_search_sentences_and_embeddings")
pandas_df = df.toPandas()
sentences = pandas_df['sentence'].tolist()
paraphrase_minilm_l3_v2_embeddings = np.array(pandas_df['paraphrase_minilm_l3_v2_embeddings'].tolist())
bert_base_japanese_embeddings = np.array(pandas_df['bert_base_japanese_embeddings'].tolist())
Databricksドライバーサイズを増やす
以下のエラーが発生した場合、
Py4JJavaError: An error occurred while calling o417.getResult.
: org.apache.spark.SparkException: Exception thrown in awaitResult: Job aborted due to stage failure: Total size of serialized results of 88 tasks (7.8 GiB) is bigger than local result size limit 7.7 GiB, to address it, set spark.driver.maxResultSize bigger than your dataset result size.
クラスタが起動した後にノートブック内で「spark.driver.maxResultSize」を変更しようとしても効果はないので、代わりに
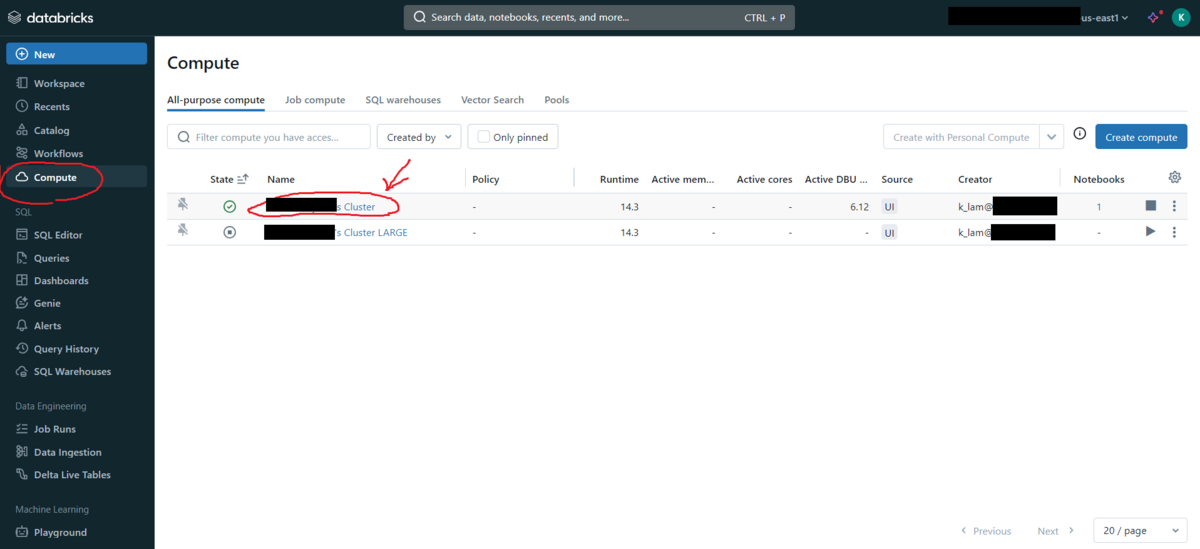
Computeタブに移動し、使用しているクラスターをクリックします。
クラスターが終了していない場合は、終了させます。
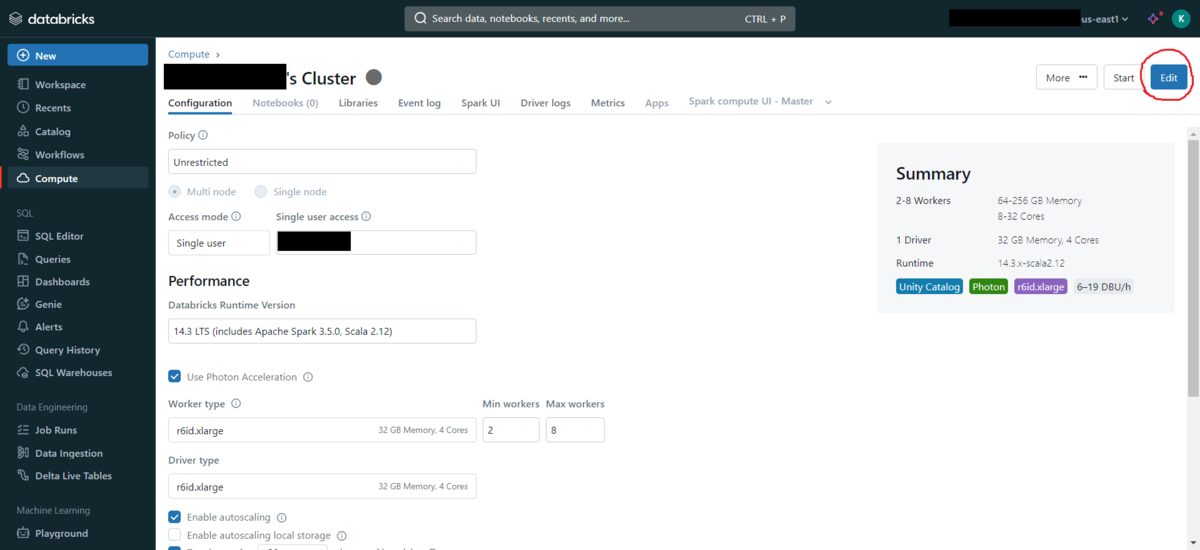
Editをクリックします。
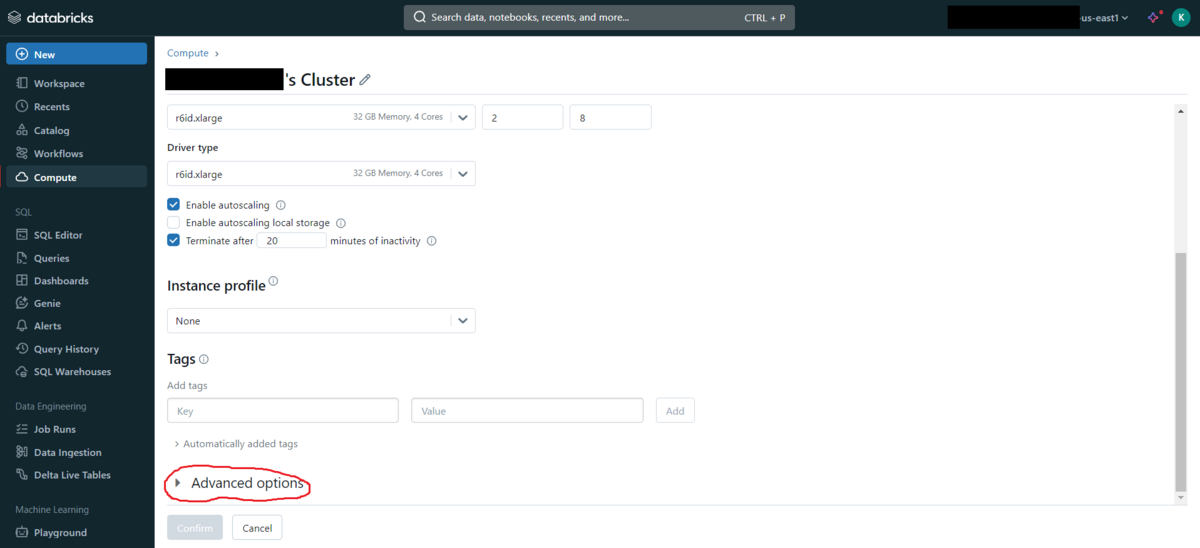
Advanced optionsまでスクロールします。
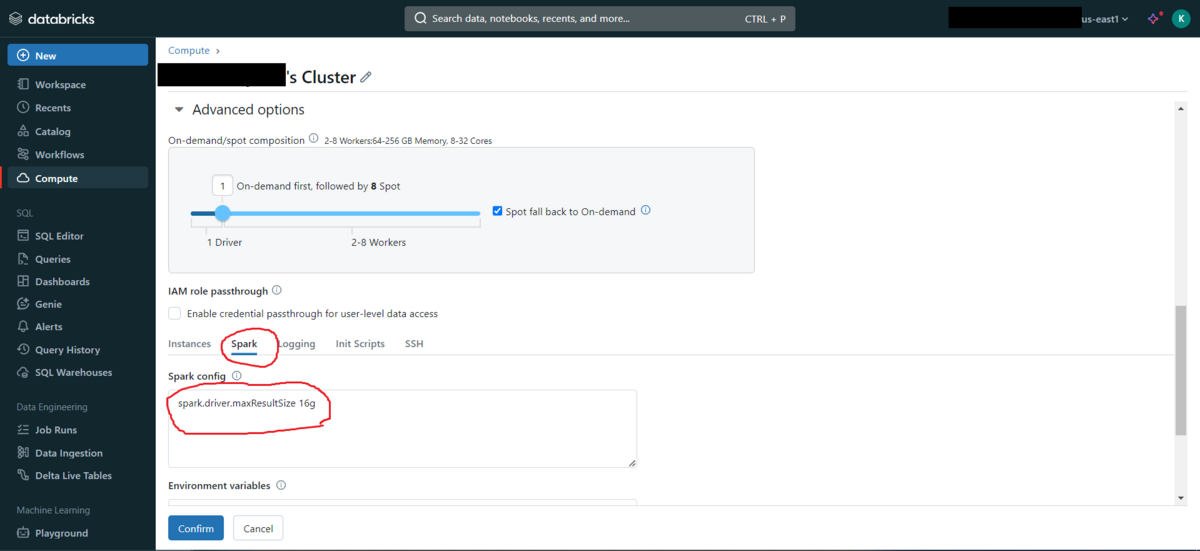
Sparkタブに切り替えます。
Sparking configに「spark.driver.maxResultSize 16g」と入力します(16gは必要に応じて変更できます)。
ベクトルインデックスの構築
埋め込みを取得した後、ベクトルインデックスの構築を行えます。
そのため、FAISSを使用しましょう。
Facebook AI Similarity Search (FAISS)は、効率的な類似検索の最も人気のあるパケージの一つです。
非常に簡単にできます:
%pip install faiss-cpu
import faiss
d = bert_base_japanese_embeddings.shape[1] #768
index = faiss.IndexFlatL2(d)
index.add(bert_base_japanese_embeddings)
上記の5行のコードで、ベクトルインデックスを構築しました。
ベクトルサーチを実行
類似する文を検索するために、まずクエリ文をベクトルに変換し、構築したベクトルインデックスに対して類似ベクトルサーチを実行します。
FAISSでは、kという変数を指定することで、最も類似した上位k個のベクトルが返されます。
#model = SentenceTransformer('bert-base-nli-mean-tokens')
k = 5
xq = model.encode(["{Replace with the sentence you want to perform similarity search}"])
D, I = index.search(xq, k)
そして、最も類似したベクトルのインデックスを取得し、対応する文を表示するには:
for i in I[0]:
print(ja_sentences[int(i)])
これで全ての目標を達成しましたが、これからは最適化について実験しましょう。
最適化手法
ベンチマーク
まず、「%%time」マジックコマンドを使用して、現在のパフォーマンスのベンチマークを行いましょう。
%%time
D, I = index.search(xq, k)
>CPU times: user 165 ms, sys: 2.74 ms, total: 168 ms
>Wall time: 173 ms
トップ5の最も類似したベクトルを検索するのに、sentence-bertの埋め込みを使用すると約173ミリ秒かかります。
同じことをMiniLMで行ったところ、約78ミリ秒かかりました。
実行時間と埋め込みの次元数には線形関係があるようです。
次元削減
主成分分析 (Principal component analysis a.k.a. PCA)
ベクトルの次元数とベクトルサーチにかかる時間の関係をさらに検討し、ベクトルサーチの実行時間を短縮するために、埋め込み(ベクトル)に対して主成分分析(PCA)を実行してみます。
次元削減とは、データ(ベクトル)の持つ特徴(次元)の数を減らす手法のことです。 次元削減には多くの方法がありますが、その中でも最も有名で簡単な方法の一つがPCAです。
PCAを行うためのコードは以下の通りです:
from sklearn.decomposition import PCA
pca = PCA(n_components=384) # number of dimension of the resulting embedding
reduced_bert_base_japanese_embeddings = pca.fit_transform(bert_base_japanese_embeddings)
これを直接実行すると、Pythonカーネルがクラッシュしてしまいます。690000 × 768の行列に対するPCAは重すぎるようです
インクリメンタルPCA
インクリメンタルPCAを使用することでメモリ不足を避けれます:
from sklearn.decomposition import IncrementalPCA
batch_size = 46555
ipca = IncrementalPCA(n_components=384)
n = bert_base_japanese_embeddings.shape[0]
for i in tqdm(range(0, n, batch_size)): # note that for each partial_fit operation, the batch should have more samples than the number of target dimension, so the batch_size need to be chosen carefully so that even the last batch still has enough samples
ipca.partial_fit(bert_base_japanese_embeddings[i:i + batch_size])
reduced_bert_base_japanese_embeddings = ipca.transform(bert_base_japanese_embeddings)
寄与率 (Explained Variance Ratio)
寄与率を確認することで、結果として得られたベクトルに元のベクトルの情報がどれだけ保持されているかを知ることができます:
explained_variance_ratio = ipca.explained_variance_ratio_
sum_explained_variance = np.sum(explained_variance_ratio)
print("Sum Explained Variance:", sum_explained_variance)
>Sum Explained Variance: 0.9372820026683756
これは、得られたベクトルが元のベクトルの約93.7%を表していることを意味します。
さらに多くのn_componentsの値を試してみましたが、結果は次の通りです。n_componentsと寄与率の関係はログスケールのように見えます。
 最終的に、n_components = 300を選択しました。これは約90%の寄与率を持ち、各ベクトルサーチには約67.2ミリ秒かかります。これは173ミリ秒と比較して60%速くなっています。
最終的に、n_components = 300を選択しました。これは約90%の寄与率を持ち、各ベクトルサーチには約67.2ミリ秒かかります。これは173ミリ秒と比較して60%速くなっています。
言い換えれば、10%の精度を犠牲にして60%の性能向上を得たことになります。また、埋め込み次元数を768から300に減らすことで、必要なストレージ/メモリ空間も60%削減できます。 MiniLMの場合、n_components = 84で約90%の寄与率が得られ、各ベクトルサーチには約26.5ミリ秒かかります。速度の向上とストレージ/メモリ空間の削減はそれぞれ66%と78%です。
このトレードオフは、実行するタスクのニーズと要件に応じて妥当であると言えます。
直積量子化 (Product Quantization)
PCAが計算的に高コストである場合(純粋な数学的手法であるため)、FAISSには直積量子化という別の次元削減手法があります。
これは情報をより積極的に捨てる代わりに、高次元ベクトルに対してより良くスケールします。
直積量子化は以下のように機能します:
各ベクトルを等しい次元数の複数のサブベクトルに分割します。
同じ位置にある各サブベクトルにクラスタリングを実行し、各サブベクトルグループのセントロイドを取得します。
サブベクトルを対応するセントロイドインデックスに置き換えます。
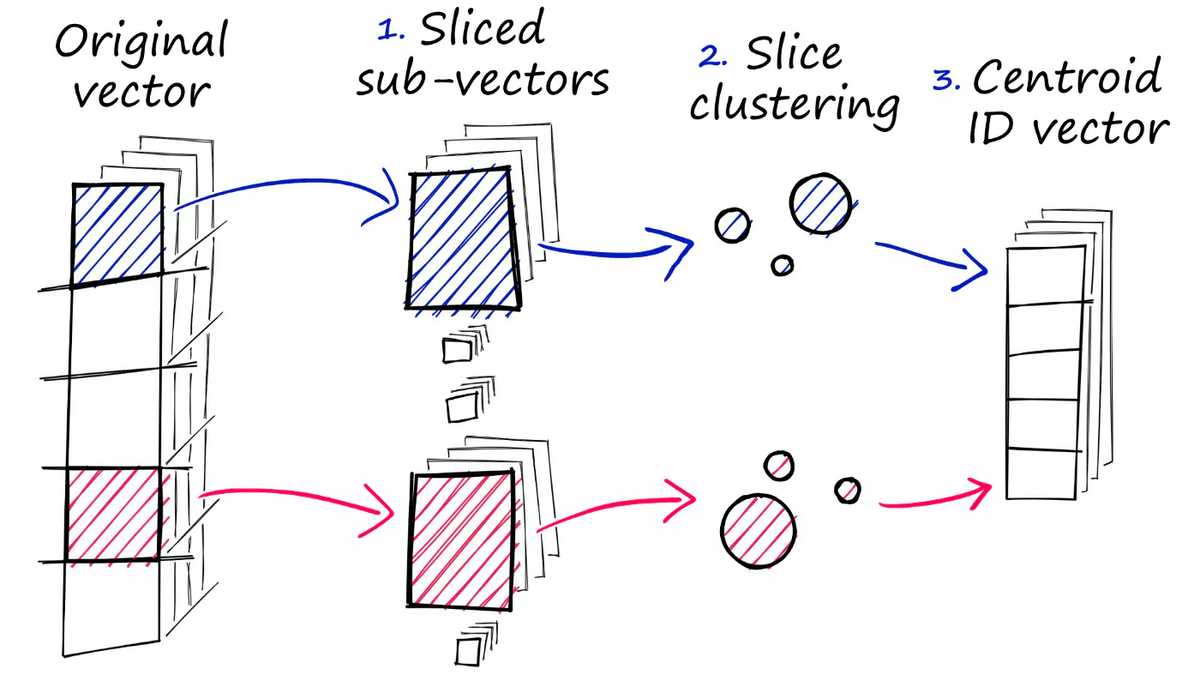 source: https://www.pinecone.io/learn/series/faiss/faiss-tutorial/
source: https://www.pinecone.io/learn/series/faiss/faiss-tutorial/
実行は:
nlist = 35 # number of clusters when clustering each sub-vector groups
m = 32 # number of centroid IDs in final compressed vectors, this has to be a factor of original deminsion to split vector into sub-vectors of equal length
bits = 8 # number of bits in each centroid
d = bert_base_japanese_embeddings.shape[1]
quantizer = faiss.IndexFlatL2(d) # we keep the same L2 distance flat index
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)
index.train(bert_base_japanese_embeddings)
これでベクトルサーチが約1.81ミリ秒しかかかりません。これは予想外に速く、32個のセントロイドIDに各セントロイドに8ビットを使用することで、256の埋め込み次元数に相当するはずですが、実際にはこれはquantizationの際にFAISSがパーティショニング (partitioning) という別の手法も使用しているためです。
パーティショニング (Partitioning)
パーティショニングとは、ベクトル空間全体を複数のパーティション (ボロノイセル) に分割することを意味します。そして、ベクトルサーチを実行するときに、クエリベクトルを各ボロノイセルのセントロイドベクトルと比較して最も近いセルを見つけ、その最も近いボロノイセル内のベクトルのみと比較します。
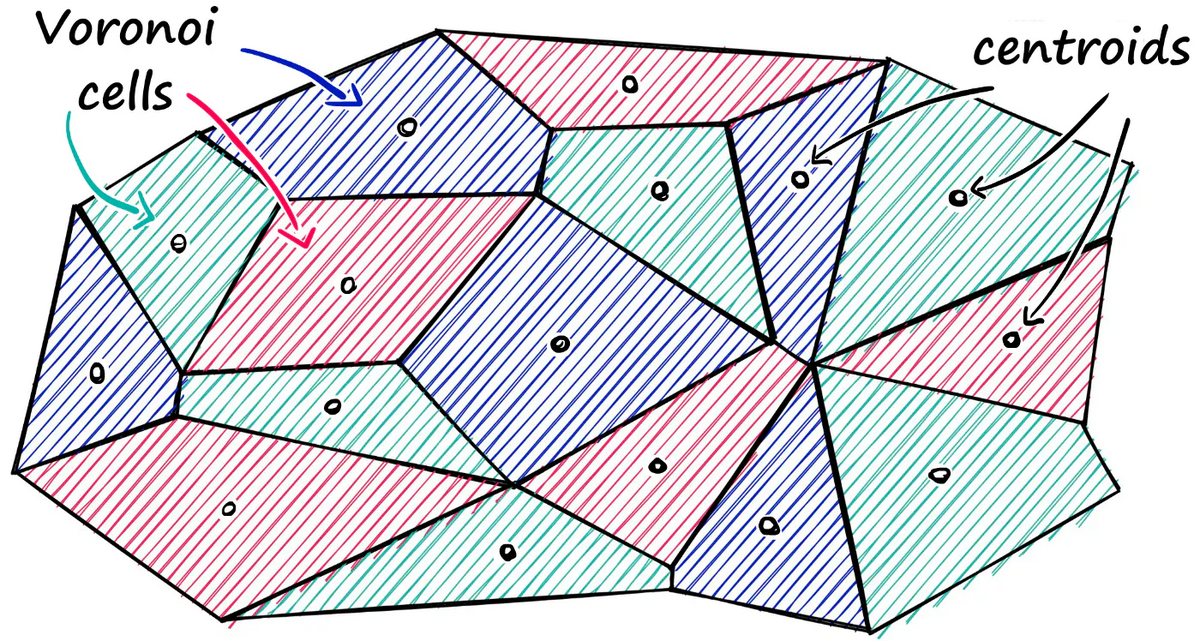 source: https://www.pinecone.io/learn/series/faiss/faiss-tutorial/
source: https://www.pinecone.io/learn/series/faiss/faiss-tutorial/
例えば、69万のベクトルが10のセルに分割され、それぞれが6万9千のベクトルを含むとします。この場合、ベクトルサーチは69万の比較ではなく、10セル間での比較 + 選ばれたセル内で6万9千回の比較だけで済むため、検索速度が大幅に向上します。
ただし、このアプローチには精度のトレードオフがあります。特にクエリベクトルが2つ以上のボロノイセルの境界付近にある場合、最も近いベクトルがクエリベクトルと同じ最も近いボロノイセル内に常に存在するとは限らないからです。
実行するには:
nlist = 10 # how many cells
d = bert_base_japanese_embeddings.shape[1]
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist)
index.train(bert_base_japanese_embeddings)
index.add(bert_base_japanese_embeddings)
k = 5
xq = bert_model.encode(["{Replace with the sentence you want to perform similarity search}"])
すると、ベクトルサーチはわずか28.8ミリ秒しかかからず、大幅な改善となります。
%%time
D, I = index.search(xq, k)
>CPU times: user 46 ms, sys: 187 µs, total: 46.2 ms
>Wall time: 45.6 ms
パーティショニングの欠点を軽減するために、アルゴリズムに最も近いセルだけでなく、最も近いn個のセルも検索するように指示することができます。 これは、nprobe属性を指定することで実現できます:
index.nprobe = 3
これにより、クエリベクトルは最も近い3つのボロノイセル内のすべてのベクトルと比較されます。当然、これにはより多くの時間がかかり、すなわち98.1ミリ秒です。
結論
このブログ記事では、sentence-BERTおよびMiniLMモデルによって埋め込まれたテキストデータセット上でベクトルインデックスを構築する実験を行いました。また、次元削減技術やパーティショニングによって検索速度の最適化を試み、それが効果的であることが証明されました。この過程で、Databricksに関する設定の問題にも直面しましたが、調査と努力の結果、すべて解決しました。今後この作業を継続する場合、より良い可視化のために画像データセット上でベクトルサーチエンジンを構築するか、この機能をDatabricks上で提供するためのAPIエンドポイントを構築してみたいと考えています。