はじめに
GLB事業部Lakehouse部の長尾です。
本ブログ(と前編)では、Databricks社の Training machine learning models on tabular data: an end-to-end example (Unity Catalog) を参照して(2025年1月16日時点)、MLflow & Hyperoptを活用したDatabricks上で機械学習を効率化させるための実装方法について紹介します。
ひとつのパターンとして本ブログでの一連の実行の流れを覚えておけると他のケースでも応用できるのではないかと考えています。
※本ブログは上記参照先の内容の翻訳ではありませんが内容はほぼ同じです。
参照先には記載がない内容も補足説明として多少追加しています。
Databricks上での機械学習を効率化させるための実装方法について、主に以下の2つの観点から説明します。
- DatabricksのUnity Catalogを活用して、どのように機械学習モデルを訓練して登録(Unity Catalogの中でMLflowを活用した再現性の強化)
- Hyperoptを活用してハイパーパラメータを効率的にチューニング ※文字数の都合上、MLflowについては主に前編で説明しています。
以下のステップで実装します。 (以下の①については前編で説明しています。)
- ① seabornやmatplotlibを使ったデータの可視化
- ② 並列でハイパーパラメータの最適な組み合わせを探索・試行し複数のモデルをトレーニング
- ③ MLflowを使用してハイパーパラメータの探索・試行の結果を調査
- ④ 登録済みのモデルをSpark UDFを使用して別のデータセットに適用(新規のデータセットに対してMLflowに登録済みの機械学習のモデルをすぐに利用して予測結果を生成するため)
今回の例では、ポルトガルのワイン「Vinho Verde」の品質を物理化学的特性に基づいて予測するモデルを構築します。
【以降の内容を実施するための必須条件】
- Databricks上で以降の内容を実行するためには、Databricks Runtime 15.4 LTS ML以上が動作しているクラスターが必要です。
- Unity Catalogが有効になっているワークスペースが必要です(Unity Catalogが有効になってない場合の実行方法はこちら)
それでは、以降で実際に実行してみましょう。 (前編からの続きです)
モデルをUnity Catalogに登録 作成したモデルをUnity Catalogに登録することで、Databricks内のどこからでも簡単にモデルを参照できるようになります。
以下のセクションではプログラミングによるモデルの登録方法について説明しますが、UIを使用してモデルを登録することも可能です。
run_id = mlflow.search_runs(filter_string='tags.mlflow.runName = "untuned_random_forest"').iloc[0].run_id
# モデルをUnity Catalogに登録する。 model_name = f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_quality" model_version = mlflow.register_model(f"runs:/{run_id}/random_forest_model", model_name) # モデルの登録には数秒かかるため、少し間をとる。 time.sleep(15)
Unity Catalogでモデルを確認するには、左のナビゲーションバーから「Catalog」をクリックし、Catalog Explorerツリーを使用して、このノートブックの冒頭で指定したカタログとスキーマに移動してください。新しいモデルはスキーマ内の「Models」に表示されます。
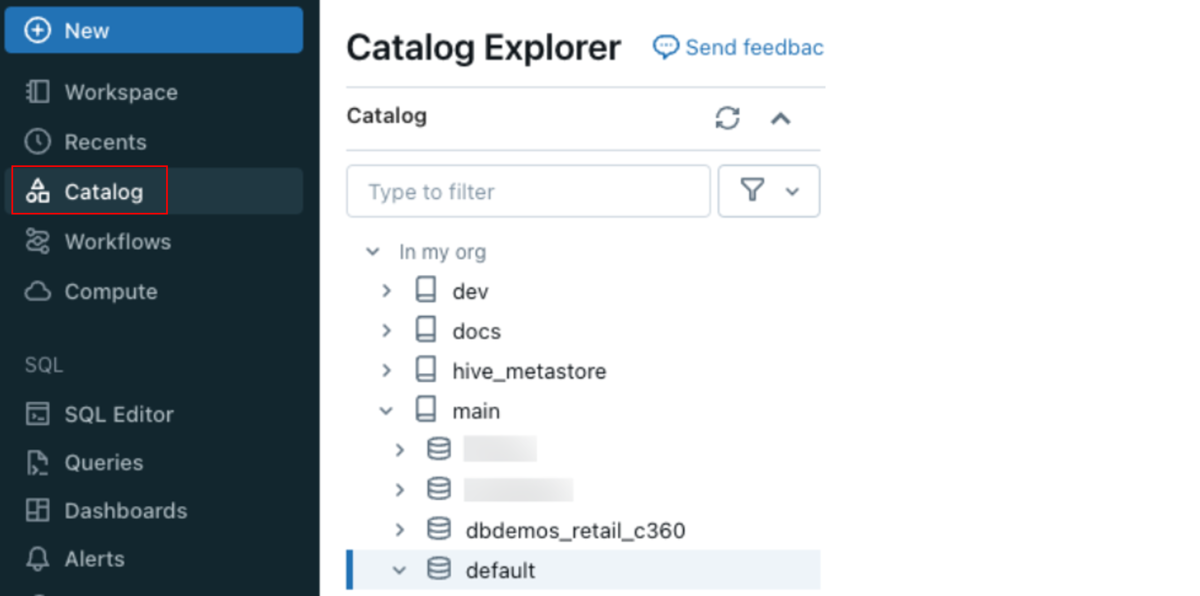 参照元: https://docs.databricks.com/ja/mlflow/end-to-end-example.html
参照元: https://docs.databricks.com/ja/mlflow/end-to-end-example.html
次に、このモデルに「Champion」タグを割り当て、Unity Catalogからこのノートブックにロードします。
from mlflow.tracking import MlflowClient client = MlflowClient() client.set_registered_model_alias(model_name, "Champion", model_version.version)
Unity Catalogでは、モデルのバージョンに「Champion」というタグが付けられています。 モデルを「models:/{model_name}@Champion」というパスを使用して参照できるようになりました。
model = mlflow.pyfunc.load_model(f"models:/{model_name}@Champion") # Sanity-check: This should match the AUC logged by MLflow print(f'AUC: {roc_auc_score(y_test, model.predict(X_test))}')
新しいモデルを試す ランダムフォレストモデルはハイパーパラメータを調整せずとも良い性能を発揮しました。 xgboostライブラリを使用して、より高精度なモデルを訓練します。 HyperoptとSparkTrialsを用いて複数のモデルを並列に訓練するためのハイパーパラメータ探索を実行します。 前回と同様に、MLflowを使用することで異なるパラメータ設定でのモデルの性能を追跡します。
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK from hyperopt.pyll import scope from math import exp import mlflow.xgboost import numpy as np import xgboost as xgb search_space = { "max_depth": scope.int(hp.quniform("max_depth", 4, 100, 1)), "learning_rate": hp.loguniform("learning_rate", -3, 0), "reg_alpha": hp.loguniform("reg_alpha", -5, 1), "reg_lambda": hp.loguniform("reg_lambda", -6, -1), "min_child_weight": hp.loguniform("min_child_weight", -1, 3), "objective": "binary:logistic", "seed": 123 # Set a seed for deterministic training } def train_model(params): # MLflowのオートロギングを使用することで、ハイパーパラメータと訓練済みモデルが自動的にMLflowにログとして記録されます。 mlflow.xgboost.autolog() with mlflow.start_run(nested=True): train = xgb.DMatrix(data=X_train, label=y_train) validation = xgb.DMatrix(data=X_val, label=y_val) # 検証セットを渡して、xgbが評価指標を追跡できるようにします。評価指標が改善されなくなるとXGBoostは訓練を終了します。 booster = xgb.train(params=params, dtrain=train, num_boost_round=1000, evals=[(validation, "validation")], early_stopping_rounds=50) validation_predictions = booster.predict(validation) auc_score = roc_auc_score(y_val, validation_predictions) mlflow.log_metric("auc", auc_score) signature = infer_signature(X_train, booster.predict(train)) mlflow.xgboost.log_model(booster, "model", signature=signature) # 損失関数を-1*auc_scoreに設定して、fminがauc_scoreを最大化するようにします。 return {"status": STATUS_OK, "loss": -1*auc_score, "booster": booster.attributes()} # 並列処理を高めるとスピードアップが期待できますが、最適でないハイパーパラメータ探索につながる可能性があります。 # 'parallelism'の適切な値はmax_evalsの平方根です。 spark_trials = SparkTrials(parallelism=10) # fminをMLflowのランコンテキスト内で実行し、各ハイパーパラメータの設定が親ラン「xgboost_models」の子ランとしてログに記録されるようにします。 with mlflow.start_run(run_name="xgboost_models"): best_params = fmin( fn=train_model, space=search_space, algo=tpe.suggest, max_evals=96, trials=spark_trials )
SparkTrials(並列処理)を使用すると処理時間が4分となり、Trialsを使用した場合と比べると処理時間を約1/5に削減できました。
(SparkTrialsではなくTrialsを使用すると処理時間が18分かかりました。)
MLflowを使って結果を確認
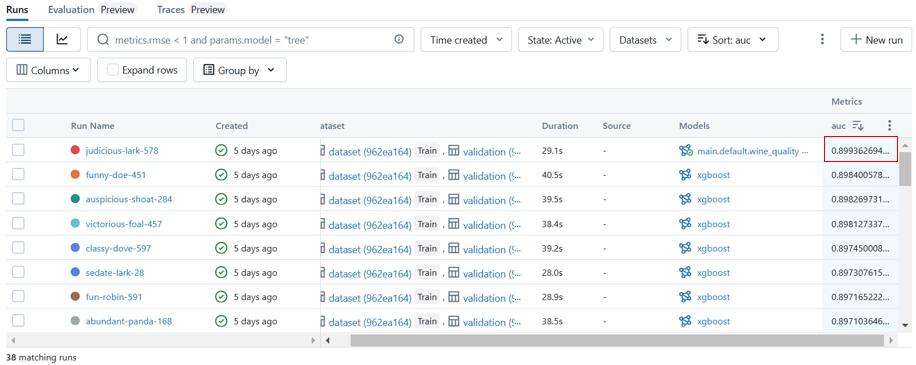
MLflow experimentsランサイドバーを開いて、MLflowのランを確認します。 矢印の隣にある「date」をクリックしてメニューを表示し、「auc」を選択して、auc指標でソートされたランを表示します。 最も高いauc値は0.899です。
MLflowは、各ランのパラメータとパフォーマンス指標を追跡します。
MLflow experimentsランサイドバーの上部にある外部リンクアイコンをクリックして、MLflowのランテーブルに移動します。
Productionバージョンのwine_qualityモデルをアップデート 既述のように、ベースラインモデルを「wine_quality」という名前でUnity Catalogに保存しました。 ハイパーパラメータの探索から得られたより正確なモデルに「wine_quality」を更新してみましょう。
MLflowを使用してそれぞれのハイパーパラメータ設定から生成されたモデルをログとして記録したため、MLflowを使って最も性能の良いランを特定し、そのランから生成されたモデルをUnity Catalogに保存することができます。
best_run = mlflow.search_runs(order_by=['metrics.auc DESC']).iloc[0] print(f'AUC of Best Run* {best_run["metrics.auc"]}')
new_model_version = mlflow.register_model(f'runs:/{best_run.run_id}/model', model_name) # モデルの登録には数秒かかるため、少し間をとる。 time.sleep(15)
左のサイドバーで「Models」をクリックして、wine_qualityモデルが現在2つのバージョンを持っていることを確認します。 新しいバージョンに「Champion」という別名を付けます。
client.set_registered_model_alias(model_name, "Champion", new_model_version.version)
「Champion」という別名を使ってload_modelを呼び出すユーザーは新しいモデルを取得できます。
model = mlflow.pyfunc.load_model(f'models:/{model_name}@Champion') print(f'AUC: {roc_auc_score(y_test, model.predict(X_test))}')
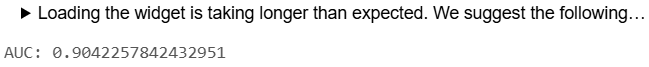 新しいバージョンは、テストデータで先程よりも少しだけaucが高くなっています(auc=0.904)。
新しいバージョンは、テストデータで先程よりも少しだけaucが高くなっています(auc=0.904)。
バッチ(Batch)推論
新しいデータセットに対してモデルを評価したいシナリオは多くあります。
例えば、新しいデータセットが手に入った場合や、同じデータセットで2つの異なるモデルのパフォーマンスを比較する必要がある場合などです。
Deltaテーブルに保存されたデータを使ってモデルを評価し、Sparkを使用して計算を並列処理します。
# 新しいデータセットをシミュレーションするために(バッチ処理のテスト)、既存の X_train データを Delta テーブルに保存します。 spark_df = spark.createDataFrame(X_train) table_name = f'{CATALOG_NAME}.{SCHEMA_NAME}.win_data' (spark_df .write .format("delta") .mode("overwrite") .option("overwriteSchema", True) .saveAsTable(table_name) )
モデルをSparkのUDF(ユーザー定義関数)として読み込み、Deltaテーブルに適用できるようにします。
apply_model_udf = mlflow.pyfunc.spark_udf(spark, f"models:/{model_name}@Champion")
# Unity Catalogテーブルから「新しいデータ」を読み込みます。 new_data = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_data")
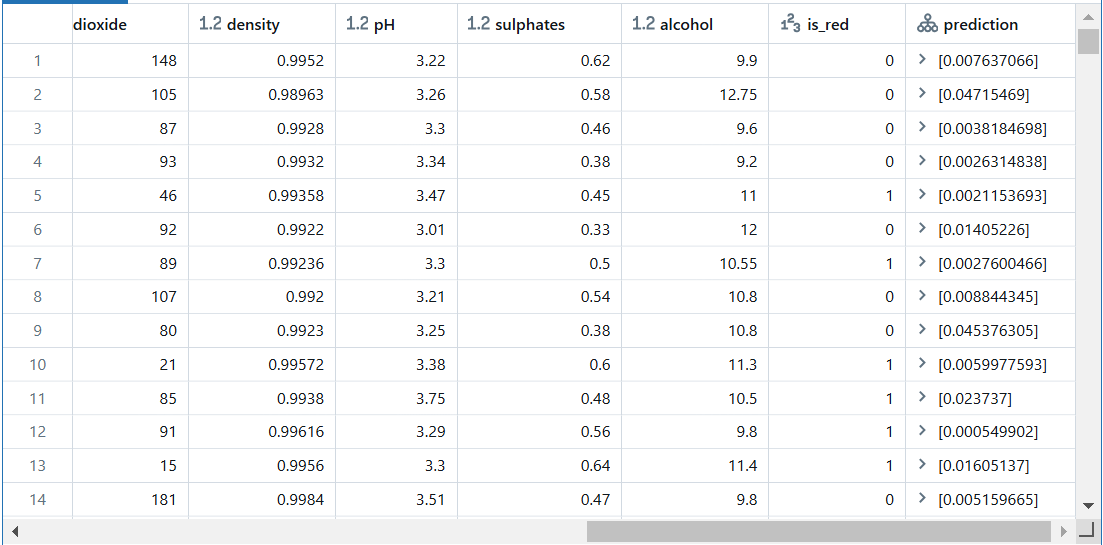
from pyspark.sql.functions import struct # 新しいデータにモデルを適用します。 udf_inputs = struct(*(X_train.columns.tolist())) new_data = new_data.withColumn( "prediction", apply_model_udf(udf_inputs) )
# 各行に予測結果が格納されています。ただし、XGBoostはデフォルトで確率を出力しないため、予測結果は[0, 1]の範囲に限定されません。
display(new_data)
<参考>
- Scaling Hyperopt to Tune Machine Learning Models in Python
- Hyperparameter Tuning with MLflow, Apache Spark MLlib and Hyperopt
最後に
本ブログ(と前編)では、Databricks上でMLflowとHyperoptを活用した効率的な機械学習の実装方法について紹介しました。
長文にもかかわらず最後まで読んでいただき、ありがとうございました!
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。