
データレイクハウスの世界で今、最も注目されているトピックの一つが「オープンテーブルフォーマットの統一」です。この動きの中心にいるのが、Databricks社の技術スタッフであるBrian Blue氏とDan Weeks氏。彼らは先日開催されたカンファレンスセッション「The Future of Open Table Formats: Delta Lake, Iceberg, and More」にて、現在データレイク市場を二分する二大巨頭、Delta LakeとApache Icebergの統合に向けた壮大な計画を明らかにしました。本記事では、このセッションの内容を基に、なぜフォーマットの統一が必要なのか、そして具体的にどのような戦略で進められているのかを、技術的な詳細に踏み込みながら解説します。この記事を読めば、データ基盤の未来を左右する重要なトレンドの最前線を理解できるはずです。
レイクハウスアーキテクチャと、避けられない「分断」という課題

現代のデータ分析基盤の中核をなすレイクハウスアーキテクチャ。その心臓部とも言えるのが、データレイク上のファイル群にデータベースのような信頼性とパフォーマンスをもたらす「オープンテーブルフォーマット」です。中でも、Databricksが開発を主導するDelta Lakeと、Netflixで生まれオープンソース化されたApache Icebergは、事実上の標準として広く利用されています。
- Delta Lakeは、Apache Sparkとの緊密な連携と、トランザクションログによる強力なACIDトランザクション保証が特徴です。信頼性の高いデータパイプラインを構築する上で絶大な支持を得ています。
- Apache Icebergは、特定のエンジンに依存しない設計思想を持ち、Spark、Trino、Flinkなど多様な分析エンジンから利用できる高い相互運用性が強みです。メタデータのツリー構造により、大規模なテーブルでも高速なプランニングを実現します。
両者とも、スキーマ進化やタイムトラベルといった高度な機能を備え、データエンジニアリングの世界に革命をもたらしました。しかし、その成功の裏で新たな課題が生まれています。それは「フォーマットの分断」です。
Delta LakeとIcebergは、提供する機能は似ていても、内部のメタデータ構造が異なるため、直接的な互換性がありません。これにより、企業は「Delta Lakeを採用すれば、このツールは使えるが、あのツールは使いにくい」「Icebergにすれば逆のことが起きる」といった選択を迫られます。講演でDan Weeks氏が指摘したように、これは「業界全体の問題」となっており、ユーザーは本来集中すべきデータ活用ではなく、フォーマットの互換性というインフラの問題に頭を悩ませることになるのです。

フォーマット統一がもたらす具体的なメリット

もし、この分断が解消され、フォーマットが統一されたら、私たちのデータ活用はどのように変わるのでしょうか。その恩恵は計り知れません。
最大のメリットは、真にオープンなエコシステムの実現です。ユーザーは基盤となるテーブルフォーマットを意識することなく、用途に応じて最適な分析エンジンやライブラリを自由に組み合わせられるようになります。例えば、ETL処理はSparkとDelta Lakeの連携で効率的に行い、同じデータをBIツールからはTrinoとIcebergのインターフェースで高速にクエリする、といったことがシームレスに実現します。
また、データガバナンスの劇的な向上も期待できます。フォーマットが統一されれば、DatabricksのUnity Catalogのような中央集権的なカタログサービスを通じて、組織内のすべてのデータ資産を一元的に管理・保護できます。誰がどのデータにアクセスしたかの追跡(リネージ)や、アクセス権限のきめ細やかな制御が、フォーマットの違いを乗り越えて適用可能になるのです。これにより、運用コストの削減とセキュリティ強化を両立できます。
3つの階層で進む、壮大な統一戦略の全体像

では、Databricksとオープンソースコミュニティは、この壮大な目標をどのように達成しようとしているのでしょうか。講演で示されたのは、問題を3つの階層に分解し、段階的に統一を進めるという非常に現実的かつ戦略的なアプローチです。
この戦略の核心は、両フォーマットの優れた点を学び合い、取り入れ、最終的には一つの共通表現に収束させることにあります。講演者が「最小の変更で最大の価値を生む」と語ったように、各コミュニティの資産を尊重しながら、現実的な統合を目指しています。
以下に、その3つの階層を具体的に見ていきましょう。
データ層(Iceberg V3): 物理ファイルの互換性を確保する
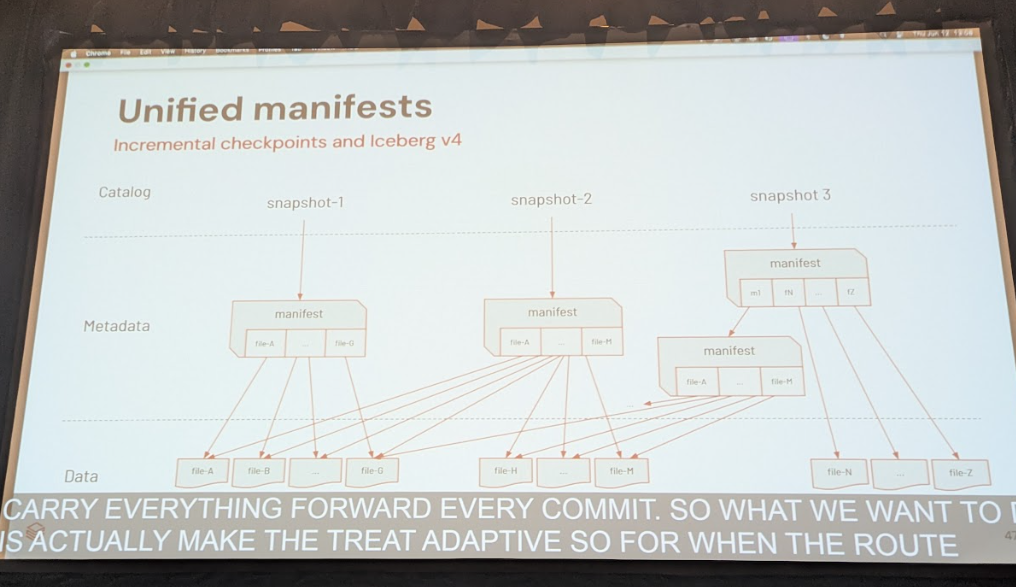
これは、ストレージに永続的に保存されるParquetファイルとその周辺機能のレベルでの統一です。最も書き換えコストが高い層であるため、ここでの互換性確保が最優先されます。Iceberg V3では、Delta Lakeと同様の行レベル削除(row-level delete)機能が強化され、より厳密なトランザクション追跡手法が導入されます。加えて、半構造化データを効率的に扱うバリアント型や、地図情報を扱う地理空間型といった新しいデータ型のサポートも進められており、両コミュニティでParquetフォーマットの標準拡張として検討が進行中です。メタデータ層(Iceberg V4): テーブル状態管理の「いいとこ取り」
テーブルにどのファイルが含まれているか、といった状態を管理するメタデータ層の統一です。ここでは、Icebergの「ツリー構造」とDeltaの「ログ方式」のそれぞれの長所を融合させる計画が示されました。具体的には、Iceberg V4として、Deltaの強みである軽量な単一ファイルコミットを実現しつつ、Icebergの強みである効率的なメタデータ再利用を可能にする適応的ツリー構造(Adaptive Tree)を導入する構想です。これにより、書き込みは高速かつ低コストに、読み取りは効率的なプランニングが可能になるという、まさに「両者のいいとこ取り」を目指します。カタログ層(Unity Catalog): ユーザーからフォーマットを隠蔽する
最終的に、ユーザーはフォーマットの違いを意識する必要がなくなります。DatabricksのUnity Catalogは、この統一戦略の最上位に位置し、IcebergのRESTカタログAPIとDelta LakeのAPIの両方をサポートします。これにより、外部ツールがどちらのフォーマットでアクセスしてきても、Unity Catalogがその差異を吸収し、統一されたガバナンスとデータアクセスを提供します。講演では「Unity APIから入ればすべてがDeltaに見え、Iceberg APIから入ればすべてがIcebergに見える」と説明されており、まさにフォーマット透過的な世界の実現に向けた重要な一歩と言えるでしょう。
Parquetを基盤とした相互互換性とロードマップ
この統一戦略が現実的である大きな理由の一つは、Delta LakeとIcebergが共に、オープンソースのカラムナストレージフォーマットであるApache Parquetをデータ格納の基盤として利用している点です。両者とも、実データはParquetファイルに格納し、その上に独自のメタデータを付与することで高度な機能を実現しています。この共通基盤があるからこそ、データ層での機能統一やメタデータ層の統合が可能になるのです。
講演によれば、この計画はすでに動き出しており、Iceberg V3で実装されるデータ層の互換性向上は、その最初の大きな成果となります。講演では、今後数か月以内に試験的にDeltaテーブルをIcebergインターフェースで扱う機能のリリースを予定しているとされましたが、正式なリリース時期や仕様についてはまだ最終決定されていません。
メタデータ層の統一(Iceberg V4)は、より長期的な計画となりますが、両コミュニティの協力体制が不可欠です。講演者も「これはDatabricksだけで決められることではない」と繰り返し強調しており、オープンソースコミュニティでの活発な議論を通じて、最良の形を模索していく姿勢が示されました。
まとめ:データ基盤の未来はよりオープンに
今回の講演で明らかになったDelta LakeとApache Icebergの統一戦略は、単なる技術的なアップデートにとどまらず、レイクハウスアーキテクチャの未来そのものを示す重要なマイルストーンです。
- 課題: Delta LakeとIcebergの「分断」は、ツールの選択を制限し、運用を複雑化させていた。
- 解決策: 「データ層」「メタデータ層」「カタログ層」の3階層で段階的に統一を進め、両フォーマットの長所を融合させる。
- 未来: ユーザーはフォーマットを意識することなく、真にオープンなエコシステムで自由にデータを活用できるようになる。
この壮大な計画が実現したとき、私たちはインフラの複雑さから解放され、データから価値を生み出すという本来の目的に、より一層集中できるようになるでしょう。この動きはまだ始まったばかりです。今後のDelta LakeおよびApache Icebergコミュニティの動向に、ぜひ注目してみてください。そして、この変革に興味を持った方は、ぜひメーリングリストへの参加やGitHubでの議論を通じて、未来のデータ基盤作りに貢献してみてはいかがでしょうか。