
はじめに
GLB事業部Lakehouse部の阿部です。
本記事では、Partner Connectを使用してDatabricks Lakehouse Platformからdbt Cloudに接続し、Databricksにあるデータをdbt cloud上で変換する流れについて解説します。
ちなみにAPCでは、dbt Labs, Inc. と販売パートナー契約を締結しており、dbtの販売と導入支援の提供が可能です。
目次
- はじめに
- 目次
- dbt cloudとは
- Partner Connectの開始
- dbt cloudでのプロジェクトセットアップ
- ソースデータを準備する
- プロジェクト構造のセットアップ (Project Structure Setup)
- ソースの宣言
- staging modelを作成
- 参考記事
- おわりに
dbt cloudとは
dbt cloudは、dbt Labsが提供しているSQLをメインに使用してクラウド上でデータを変換できる開発環境です。
データ処理フローのELT(Extract Load Transform)のうちTransformを担当するため、データの抽出や読み込みはできず、データベースから読み込んだデータの変換に焦点を当てています。
dbt cloudでは、DatabricksのPartner Connectを使用することでDatabricks上のデータをdbt cloud上で変換し、そのデータをDatabricks上に置くことができます。
※Partner Connectを使うには、Premiumのサブスクリプションプランを使う必要があります。
(https://www.getdbt.com/partners/databricks/のThe Analytics Engineering Workflowの一部を引用)
Partner Connectの開始
Databricksにログイン後、SQLのワークスペースに移動してサイドバーのPartner Connectをクリックします。
接続するパートナーを選択する画面が表示されますので、検索フィールドのプルダウンから選択するか、下にスクロールしてdbtを選択します。

dbt cloudで使用するSQL warehouseを選択します。(起動には数分かかります)
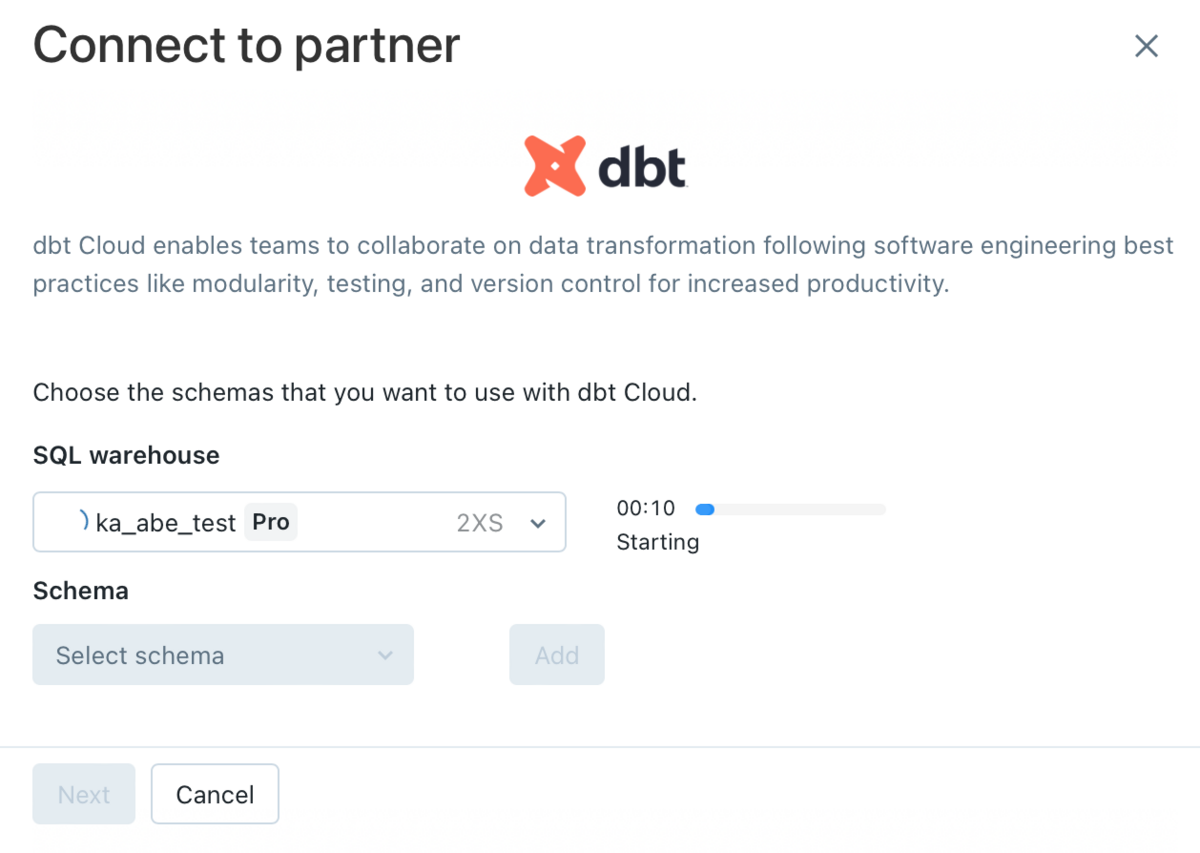
次に、Schemaのドロップダウンリストからスキーマ(データベース)を選択します。
複数のスキーマを選択することも可能であり、Addをクリックしてスキーマを追加できます。
※はじめてdbtのPartner Connectを使用する場合は、defaultのみが表示されます。
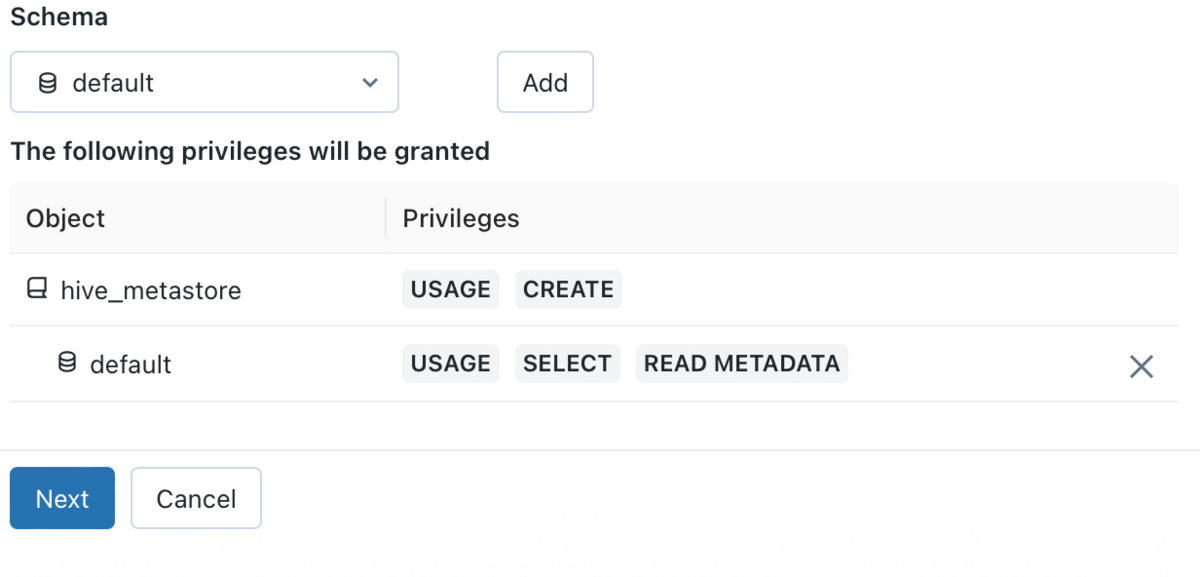
選択したスキーマにはUSAGE, SELECT, READ METADATA権限が付与されます。
Nextボタンをクリックすると、dbt cloud専用のユーザー名と選択したスキーマの権限が表示され、個人アクセストークンが作成されます。
Nextボタンをクリックします。

dbt Cloudのサインアップ時に使用するメールアドレスが表示されますが、ワークスペースに関連付けられたメールアドレスが事前に入力されています。
Connect to dbt Cloudボタンをクリックすると接続が開始されます。

接続が完了すると、dbt cloudの新規タブが開かれます。
以上でPartner Connectの作業は完了です。
dbt cloudでのプロジェクトセットアップ
dbt cloudのページに移り、プロジェクトのセットアップをします。
事前にプロジェクトの作成が済んでいることを想定していますが、済んでいない方はプロジェクト作成の段階でプロジェクト名を入力することから始めてください。
まずは、接続先にDatabricksを選択し、Nextボタンをクリックします。

環境設定に移ります。
- Nameフィールドに接続時の名前を入力します。
- Select AdapterにはDatabricksと接続するためのアダプターを選択します。
2つのアダプターが提供されていますが、Databricks (dbt-databricks)はDatabricksとdbt Labsが提携して保守している検証済みのアダプターです。
こちらのアダプターは、DatabricksのUnity Catalogをサポートするなど最新の機能を備えているため、こちらが推奨されています。

各種設定項目に入ります。
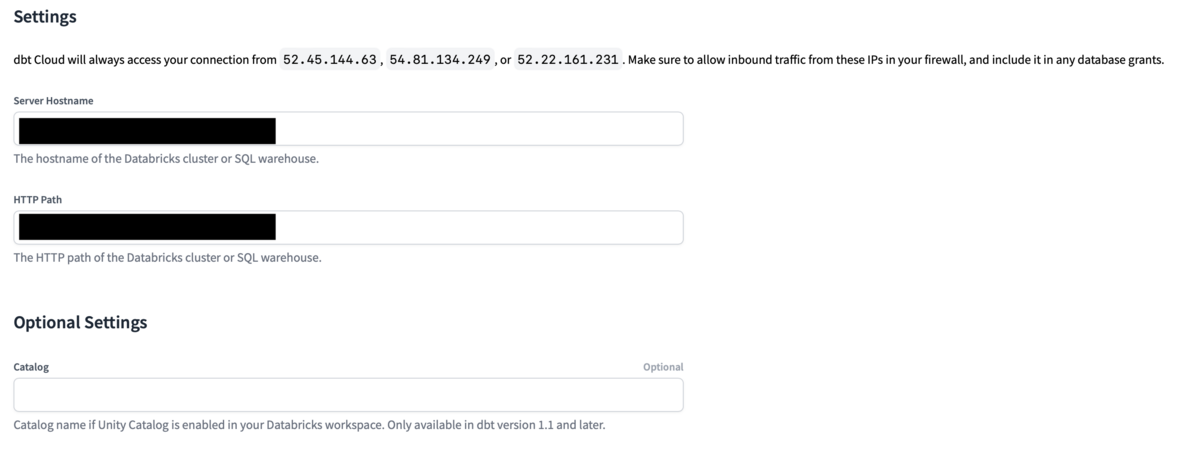
まずは、Databricks SQL WarehouseのServer HostnameとHTTP Pathを入力します。
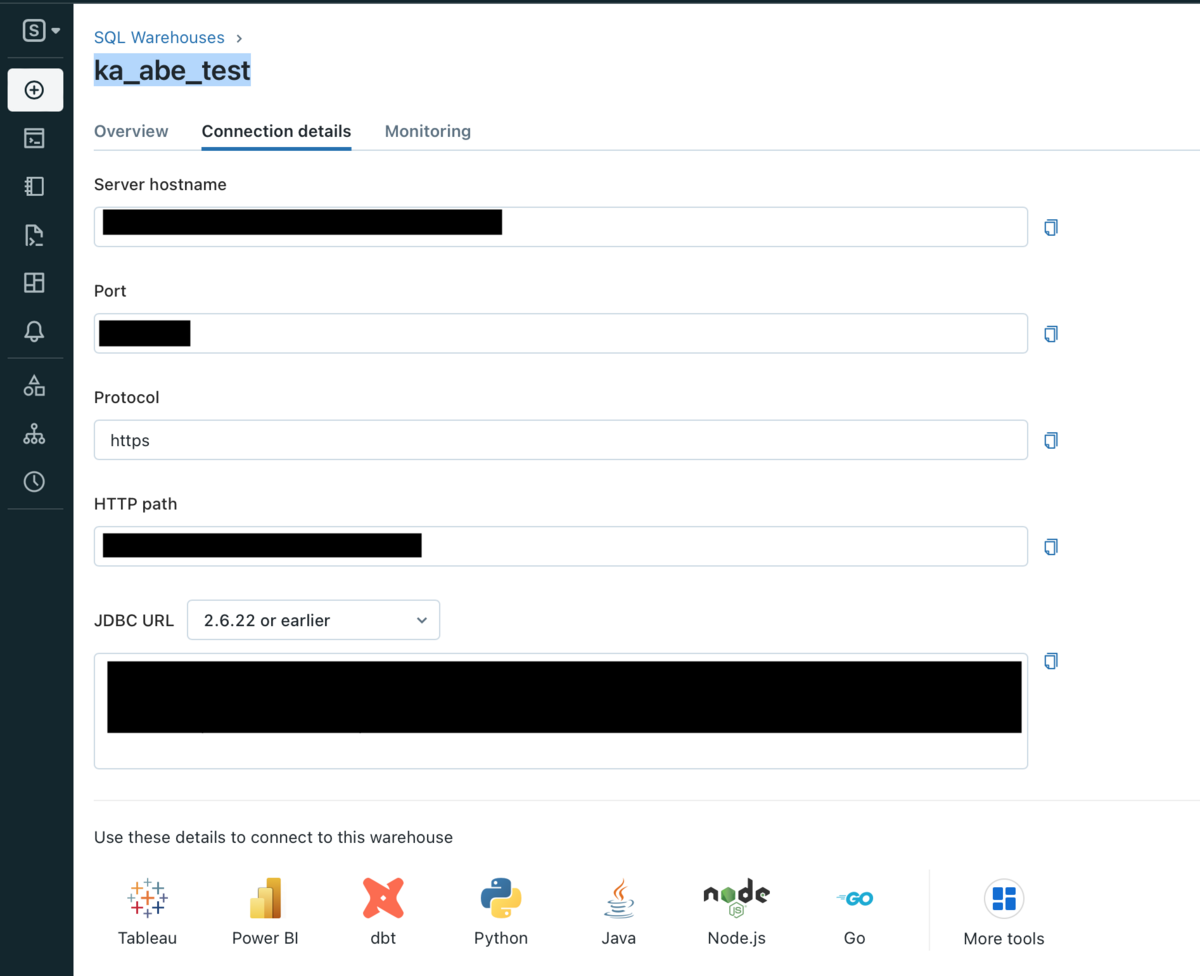
Server HostnameとHTTP Pathを確認するには、サイドバーからSQL Warehouseをクリックし、接続するSQL Warehouseを選択後、Connection detailsのタブからSQL Warehouseの情報が確認できます。
Catalogには、Databricks WorkspaceでUnity Catalogが有効な場合にカタログ名を入力します。
任意ですので、記入しなくても問題ありません。
認証設定に移ります。
TokenのフィールドにDatabricksアカウントの個人用アクセストークンを入力します。

Schemaフィールドには、dbt Cloudでテーブルとビューを作成するスキーマの名前を入力します。
こちらのスキーマはDatabricks上にも作成され、これからモデルとして作成するテーブルもスキーマに作成されており、作業が同期しているようです。
Target Nameはよくわかっていません。
任意であるため記入しなくても問題ありませんが、defaultと記入しました。
ちなみに、トークンはDatabricksのユーザー設定から可能です。
Databricksのユーザー設定に移動し、Generate new tokenボタンをクリックしてトークンを作成します。

トークン作成時にコメント可能ですが、空欄でも構いません。

Generateボタンをクリックするとトークンが表示されるため、コピーしてdbt cloudのページからTokenフィールドに貼り付けます。
その後、右下のTest Connectionボタンをクリックします。
 接続テストが完了後、Nextボタンをクリックしてレポジトリーの設定に移ります。
接続テストが完了後、Nextボタンをクリックしてレポジトリーの設定に移ります。

GitHub等のリポジトリ一覧が表示されるため、自分が使うリポジトリを選択します。
dbt cloudで使用するdbtプロジェクトは、通常GitHubリポジトリに保存され、GitHubのアカウントと連携することで可能となります。
リポジトリを設定後、Nextボタンをクリックしてプロジェクトの設定は完了です。
dbt cloudの画面上にDevelopタブがあるため、クリックするとIDEが読み込まれます。
読み込みが完了したら、画面左上の緑色のinitialize your projectボタンをクリックし、開発に必要なコアフォルダーやファイルをすべて含んだdbtスタータープロジェクトを作成します。

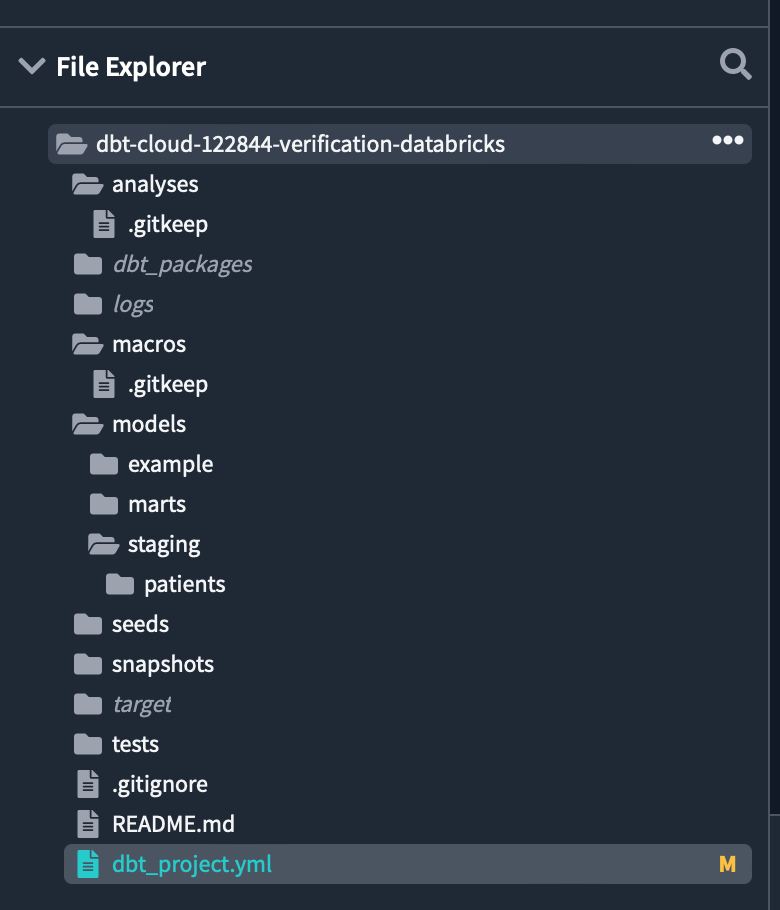
initializeが完了すると、dbtプロジェクトでの開発に必要なフォルダーやファイルが表示されます。
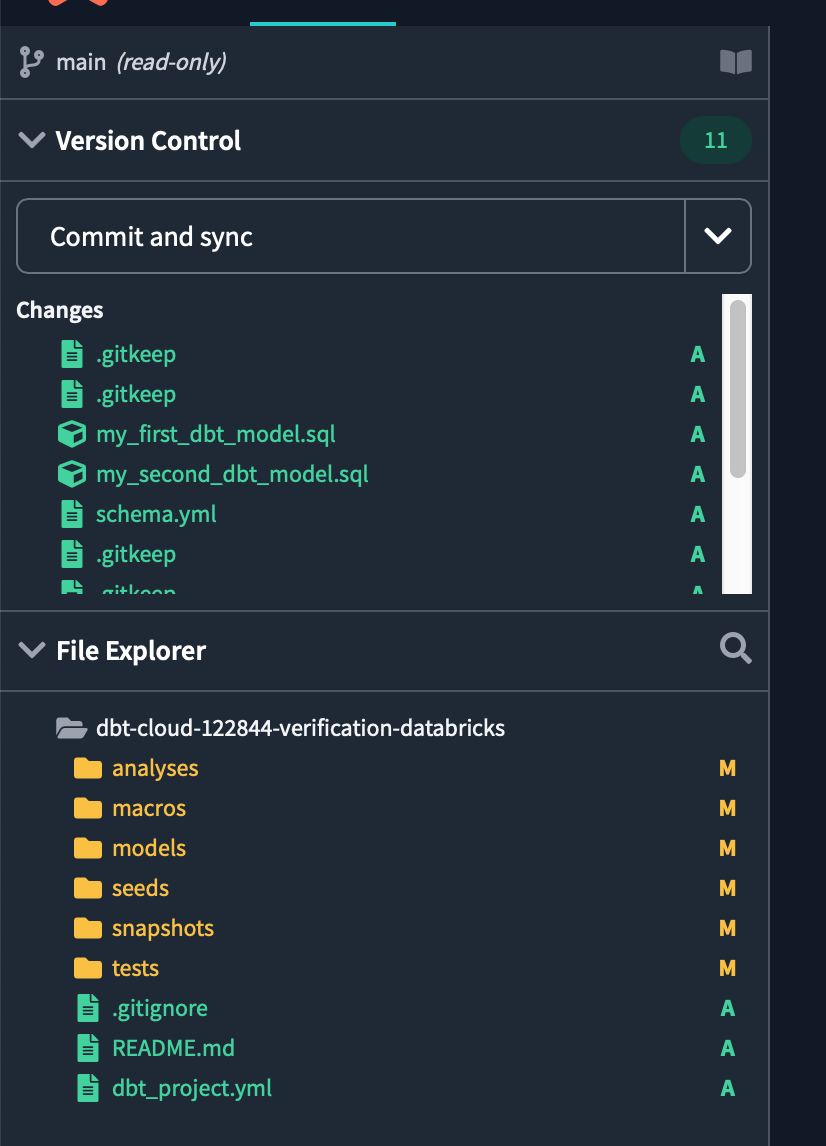
次に左上のCommit and syncをクリックし、初期化で作成した新しいファイルやフォルダーを含むプロジェクトに対して最初のコミットをします。
コミットメッセージは何でも良いですが、initialise projectと入力してコミットします。
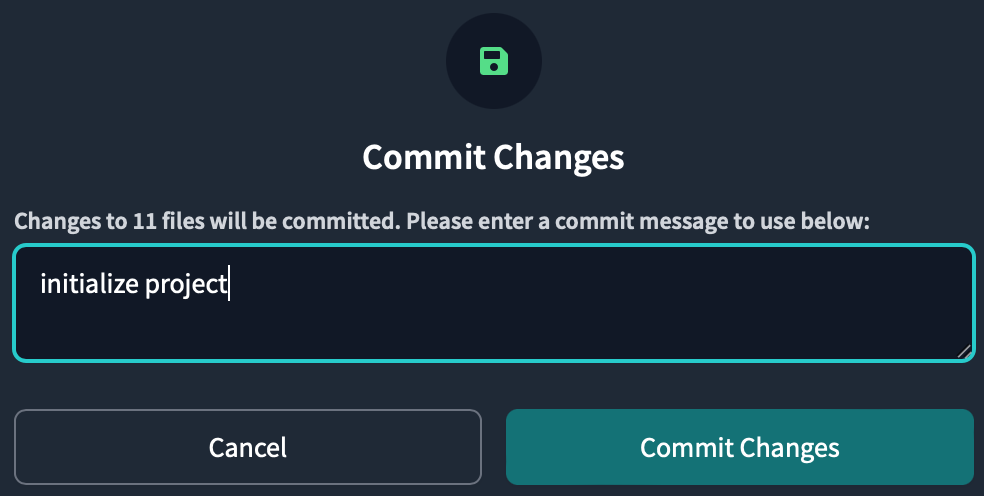
コミットすると、Partner Connectのサインアップ時に作成したリポジトリに作業が保存されます。
ブランチを切っていないため、最初のコミットはメインブランチにされています。
本番用コードと開発用コードを分離するために、後ほど開発用のブランチを切ってすべての作業を開発用ブランチで行います。
ソースデータを準備する
dbtプロジェクトで使用するソースデータを準備します。
今回はdatabricksのデータを使用するため、databricks側でデータを準備します。
Databricksにログイン後、サイドバーからSQL EditorをクリックしてSQL EditorのUIに移動します。
New queryタブを開いてPartner Connectによって自動プロビジョニングされた実行中のSQLウェアハウスを使用し、新しいSQLクエリーを作成します。
DBFS(Databricks File System)のサンプルデータを使用します。
サンプルデータを格納するスキーマを作成後、サンプルデータを読み込んでDelta Tableを作成します。
-- サンプルデータを格納するスキーマの作成 CREATE SCHEMA IF NOT EXISTS patient; -- patientスキーマに対する操作権限を付与 GRANT ALL PRIVILEGES ON SCHEMA patient TO users; -- 以下、dbfsのデータセットを読み込んでDeltaテーブルを作成する CREATE TABLE patient.allergies USING csv OPTIONS (path "/databricks-datasets/rwe/ehr/csv/allergies.csv", header "true"); CREATE TABLE patient.careplans USING csv OPTIONS (path "/databricks-datasets/rwe/ehr/csv/careplans.csv", header "true");
作成したテーブルを参照します。
SELECT * FROM patient.allergies;

SELECT * FROM patient.careplans;

今回使用する2つのサンプルデータは、仮想的に作成した患者データに対してアレルギー情報と治療計画の情報が記されたカラムをそれぞれ持っています。
プロジェクト構造のセットアップ (Project Structure Setup)
それではdbtプロジェクト構造の設定に入ります。
まずは作業用の新しいgitブランチを作成する必要があるため、Create branchボタンをクリックします。
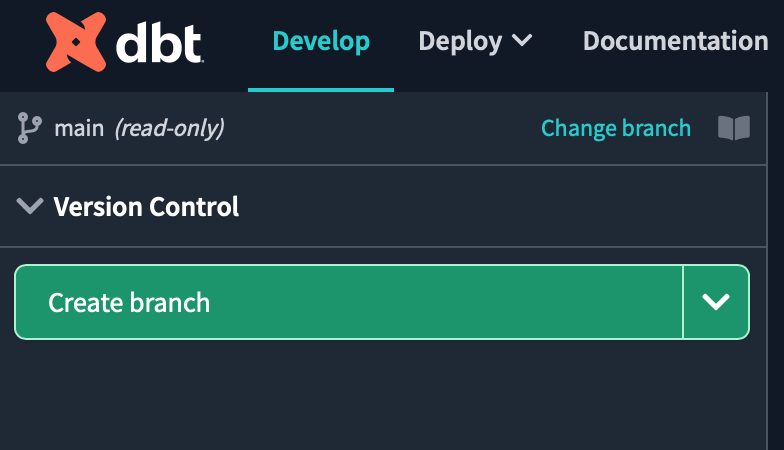
ブランチの名前はdatabricks_dbt_verificationとしてsubmitをクリックします。
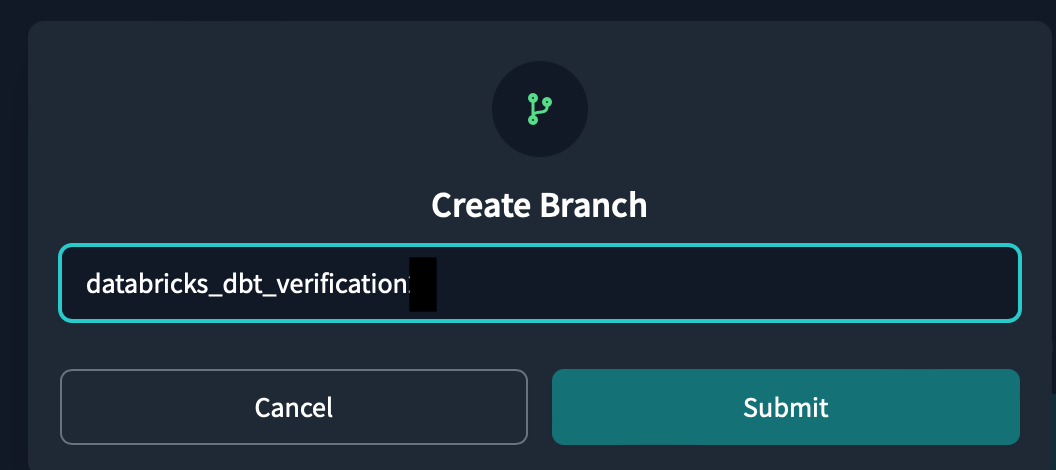
次に、このプロジェクト用のdbt_project.ymlのファイルにプロジェクト構造の定義内容を書く必要があります。
このファイルは、「作業中のファイルはdbt_project.ymlファイルに定義したプロジェクト内のファイルです」と認識させるものです。

dbt_project.ymlを開くと雛形がすでに用意されています。
各タグの説明が英語で書かれており、日本語訳したものを以下に示します。
# Name your project! Project names should contain only lowercase characters and underscores.
# A good package name should reflect your organization's name or the intended use of these models
# プロジェクトの名前を付ける!プロジェクト名には、小文字とアンダースコアのみを使用すること。
# 良いパッケージ名は、あなたの組織名やこれらのモデルの使用目的を反映したものであるべきです。
name: 'databricks_dbt_verification'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
# この設定は、dbtがこのプロジェクトでどの「プロファイル」を使用するかを設定します。
profile: 'default'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
# これらの設定は、dbtが様々な種類のファイルを探す場所を指定します。
# 例えば、`source-paths`設定は、このプロジェクトのモデルは以下のようなものであることを示します。
# "models/"ディレクトリにあります。おそらく、これらを変更する必要はないでしょう!
model-paths: ["models"] # モデルとソースを配備するパスを指定
analysis-paths: ["analyses"] # 分析用の SQL を配置するパスを指定
test-paths: ["tests"] # テストコードを配備するバスを指定
seed-paths: ["seeds"] # テスト用のデータであるシードファイルを配備するパスを指定
macro-paths: ["macros"] # マクロを配備するパス
snapshot-paths: ["snapshots"] # スナップショットを配備するパス
target-path: "target" # dbt コマンドの出力先パス。モデルなどをSQLファイルにコンパイルするためその出力先。
clean-targets: # dbt clean コマンドを実行したときに削除対象のディレクトリを指定
- "target"
- "dbt_packages"
dispatch:
- macro_namespace: dbt_utils # ディスパッチするマクロの名前空間(パッケージ)。
search_order: ['spark_utils', 'dbt_utils'] # dbtが探すPackageの順番
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/ directory
# as tables. These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
# この設定例では、example/ディレクトリにあるすべてのモデルをテーブルとして構築するようにdbtに指示しています。
# これらの設定は、個々のモデルファイルで上書きすることができます。config(...) }}`マクロを使用します。
models: # モデルの設定
databricks_dbt_verification:
# 各フォルダーごとのmaterializeの設定。materializeは、dbtが生成する物理データモデルであり、Data Warehouse上で何を用いて構築するか決めること
example:
materialized: view # デフォルトはビューとなります。データの移動が発生しないため高速にモデルを構築できます。
staging:
materialized: view
marts:
materialized: table # dbt run のたびにデータを入れ直す
dispatchタグについて
dbt_utilsが参照されるたびに、dbtはspark_utilsパッケージで対応する関数を最初に探し、そこで見つからなければdbt_utilsを探すように指示します。
これは、この特定のパッケージにまたがるSpark SQLとの互換性を維持するために重要です。modelsタグの
materializedについて
これから作成するモデルをviewもしくはtableとして扱うか定義しています。
viewやtable以外にもmaterializationsの種類はあるため、気になる方はdbtの公式ドキュメントを参照してみてください。
dbt_project.ymlファイルを変更後、画面右上のSaveボタンをクリックして変更後を保存します。
次に、開発の準備としてmodelsディレクトリの中にstagingモデル用のディレクトリを作ります。
Staging modelとは、データパイプラインの初期段階で外部のデータソースからデータを取り込むために使用するモデルです。
生のデータを取り込み加工し、クリーンな状態にすることを目的としています。
また、このモデルを使用することで、データパイプラインのバグを検出しやすくなり、より柔軟で拡張性の高いデータパイプラインを構築できます。
modelsフォルダーにある3つの点をクリックし、Create Folderをクリックします。
ポップアップに表示されるディレクトリ名にはstagingと入力し、Createをクリックします。
modelsディレクトリの中にstagingフォルダーがあることを確認できます。
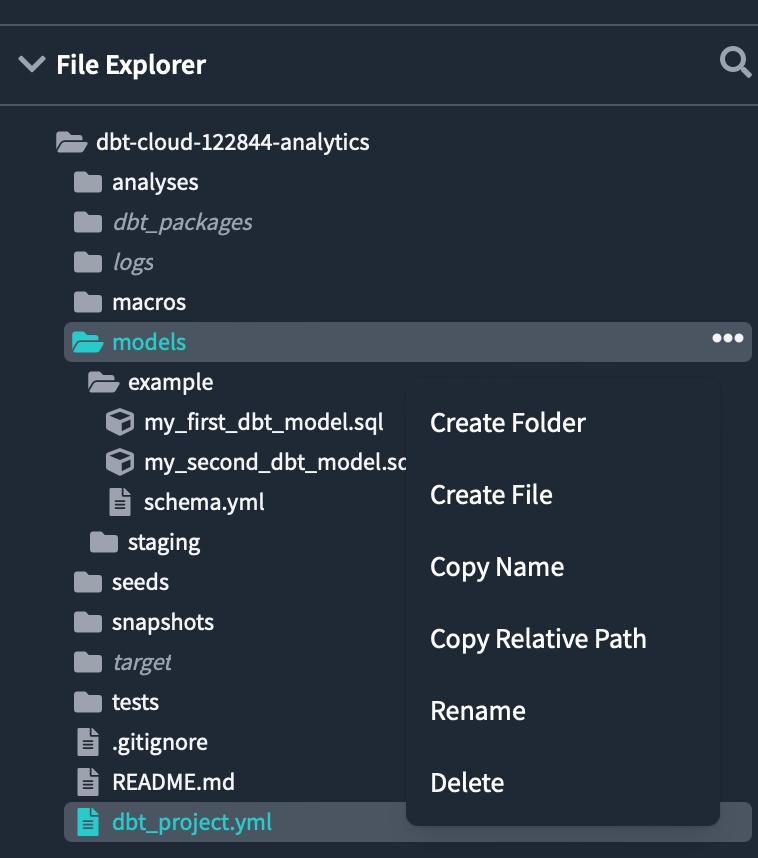
同様に、stagingフォルダー内にpatientsというフォルダーを作成します。
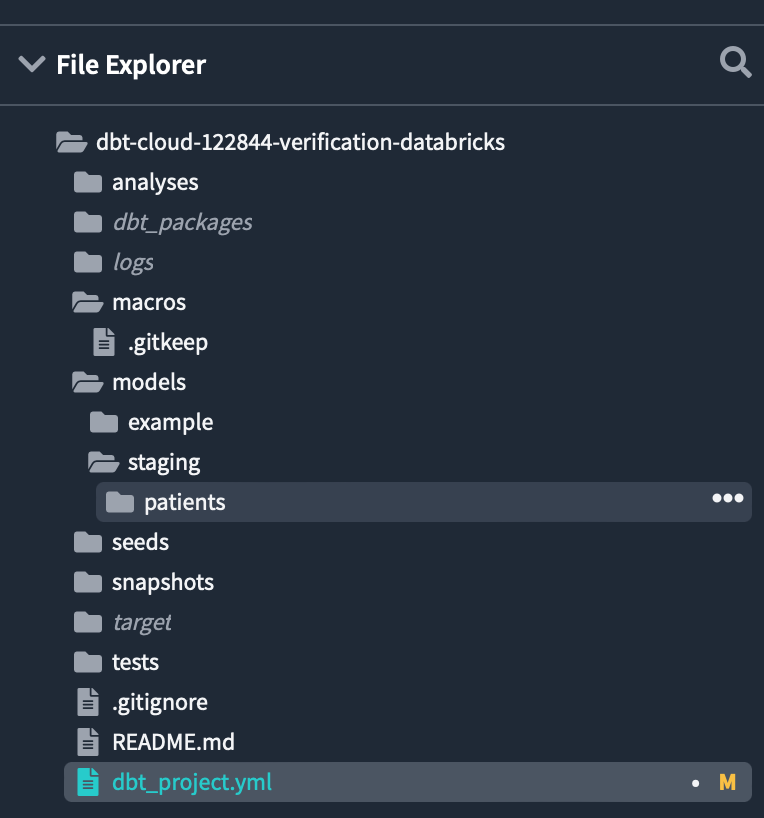
modelsディレクトリの配下に各フォルダーが作成されました。
さらに、modelsディレクトリの配下にmarts/coreと入力して2つのフォルダーを同時に作成します。
Marts modelとは、ビジネスの分析やレポーティングに使用し、DatabricksのGold Tableに相当します。
モデル構築の流れをまとめると、以下のようになります。
外部データソース -> staging モデル -> marts モデル -> BI ツール
続いて、プロジェクトにパッケージを追加します。
packages.ymlを作成し、インストールしたいPackageを記載します。
作成場所の決まりとして、dbt_project.ymlと同じ階層に作る必要があります。
dbtにはさまざまなPackageが用意されており、以下のページから確認できます。
以下のコードを入力してSaveします。
packages:
- package: dbt-labs/dbt_utils
version: 1.0.0
- package: dbt-labs/spark_utils
version: 0.3.0
dbt_utilsにはデータモデルを開発する上で、役に立つマクロやテスト等のライブラリが入っています。
spark_utilsにはSparkのAPIを抽象化して簡単に使用できるようにすることで、ビッグデータ処理の開発を簡素化するライブラリが入っています。
dbt_utilsのインストール方法:
dbt_utils
spark_utilsのインストール方法:
spark_utils
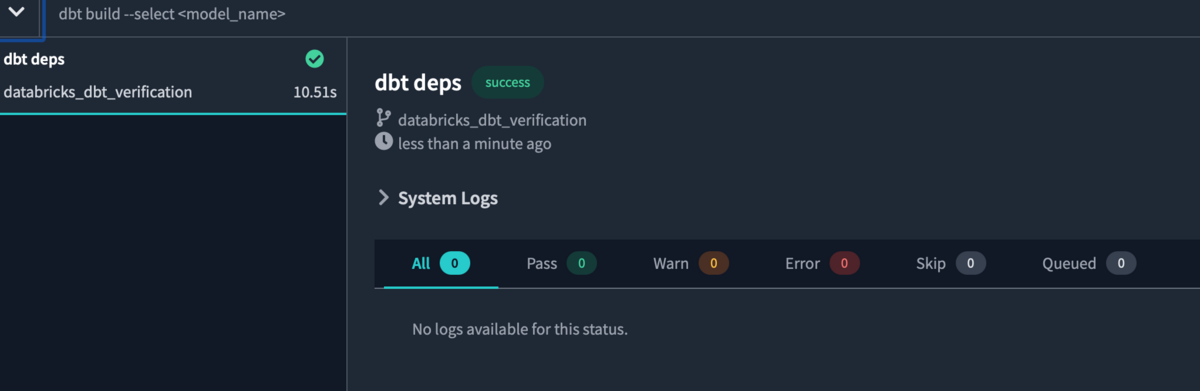
パッケージをインストールするにはdbt depsコマンドを画面下のコンソールに入力し、Enter/Returnを押します。
パッケージのインストールが完了しました。
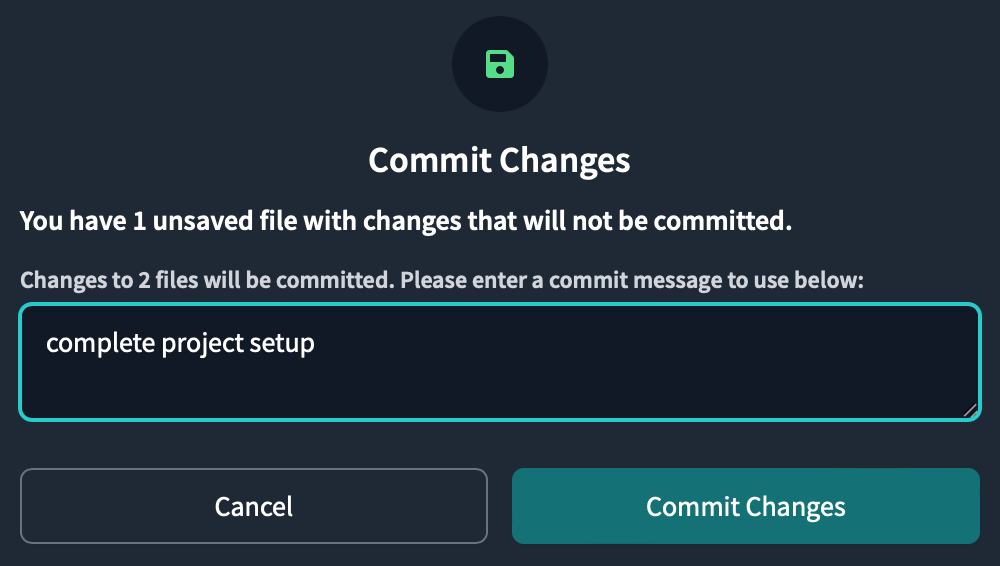
プロジェクト構造のセットアップが完了したため、作業をコミットしておきます。
画面左上のCommit and syncをクリックし、Commit Changesボタンをクリックしてコミットします。
ソースの宣言
これからソースデータを宣言するソースファイルを作成します。
dbtにおけるソースとは、DWH内のデータに名前を付けてソースを宣言することで、モデルから参照可能にしたリソースのテストや更新確認が可能となります。
models/staging/patientsフォルダー内にpatient_sources.ymlという新しいファイルを作成し、以下のコードを書いて保存します。
version: 2
sources:
- name: patient
schema: patient
tables:
- name: allergies # テーブルの名前
description: >
sample data of allergies
freshness:
warn_after: # 一定時間(12時間)更新されないと警告が出る
count: 12
period: hour
error_after: # 一定時間(24時間)更新されないとエラーが出る
count: 24
period: hour
columns:
- name: PATIENT # カラム名を指定し、制約を満たすかどうかテストできる
tests:
- not_null # カラムに対する制約
- name: careplans
description: >
sample data of patients's careplans
freshness:
warn_after:
count: 12
period: hour
error_after:
count: 24
period: hour
columns:
- name: PATIENT
tests:
- not_null
ソースを宣言すると、Lineageが出現します。

ドキュメントを参照すると、リネージュグラフを確認できます。
そのためにはコンソールでdbt docs generateコマンドを実行し、ドキュメントを作成する必要があります。
ドキュメントの参照は、プロジェクト名の横にある本のアイコンをクリックします。
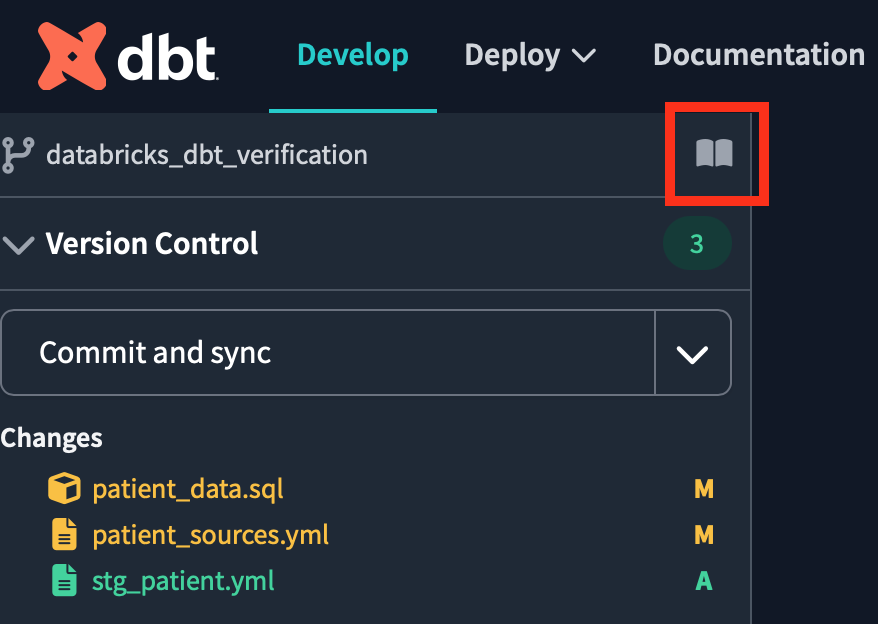
dbt Docsを開き、ソースファイルからテーブルをクリックするとテーブル情報が記載されています。
画面右下の赤枠で囲ったリネージュアイコンをクリックすると、先ほどと同じリネージュグラフを確認できます。

staging modelを作成
次に、取り込む生のソースデータをクリーンアップするためにstaging modelをセットアップします。
dbtにおけるモデルとは、一言で言うとselect文で作成した.sqlファイルのことです。
そのため、モデルについて以下のことが言えます。
- ソースデータと1対1の関係を持つ
- 1つのモデルは1つの
select文で構成されます。 - ファイル名がモデル名になります。
最初のstaging modelは、allergiesテーブルから作成します。
models/staging/patientフォルダーにstg_patient_allergies.sqlというファイルを新規作成し、以下のselect文を作成してファイルを保存します。
with source_data as ( select * from {{ source('patient', 'allergies')}} ) , renamed_data as ( select cast(START as date) as start_date , cast(STOP as date) as stop_date , case when PATIENT like '%-%' then left(PATIENT, 8) else PATIENT end as patient , case when ENCOUNTER like '%-%' then left(ENCOUNTER, 8) else ENCOUNTER end as encounter , CODE as code , DESCRIPTION as description_allergiess from source_data ) select * from renamed_data
こちらのクエリーでは、source関数によってpatientスキーマにあるallergiesテーブルを読み込んでいます。
source関数によってスキーマとテーブルを指定し、ソースデータを読み込むことが可能となります。
コンソールにあるPreview Selectionボタンをクリックすると、IDE上でクエリの結果が表示されます。
また、Compile Selectionボタンをクリックすると、クエリがDWHで実行されるコンパイル済みのコードを表示できます。
2つ目のstaging modelの構築を開始するには、models/staging/patientフォルダーにstg_patient_careplans.sqlというファイルを新規作成し、以下のselect文を作成してファイルを保存します。
with source_data as ( select * from {{ source('patient', 'careplans') }} ) , renamed_data as ( select case when Id like '%-%' then left(Id, 8) else Id end as id , cast(START as date) as start_date , cast(STOP as date) as stop_date , case when PATIENT like '%-%' then left(PATIENT, 8) else PATIENT end as patient , case when ENCOUNTER like '%-%' then left(ENCOUNTER, 8) else ENCOUNTER end as encounter , CODE as code , DESCRIPTION as description_careplans from source_data ) select * from renamed_data
最後に、患者のアレルギーと治療計画の情報をまとめたstaging modelを作成します。
models/staging/patientフォルダーにstg_patient_allergies_careplans.sqlというファイルを新規作成し、以下のコードを書いて保存します。
with patient_allergies as ( select * from {{ ref('stg_patient_allergies') }} ) , patient_careplans as ( select distinct id , start_date , patient , code , description_careplans from {{ ref('stg_patient_careplans') }} ) , patient_allergies_careplans as ( select patient_careplans.id , patient_allergies.start_date , patient_allergies.patient , patient_allergies.code as allergies_code , patient_careplans.code as careplans_code , patient_allergies.description_allergiess , patient_careplans.description_careplans from patient_allergies inner join patient_careplans on patient_allergies.patient = patient_careplans.patient ) select * from patient_allergies_careplans
ref('モデル名')関数を使用することで、作成済みのモデルを読み込むことができます。
ここでは、先ほど作成した2つのstaging modelを読み込み、left joinで結合しています。
Previewボタンをクリックしてクエリー結果を表示します。

staging modelの作成が完了したため、marts modelを作成します。
models/marts/coreディレクトリの配下にpatient_data.sqlファイルを作成し、以下のコードを書いて保存します。
{{
config(
materialized = "table",
tags=["patient"]
)
}}
with patient_data as (
select *
from {{ ref('stg_patient_allergies_careplans') }}
)
, risk_pred_data as (
select id
, patient
, count(distinct allergies_code) as number_of_allergiess
, count(distinct careplans_code) as number_of_careplans
from patient_data
group by 1, 2
order by number_of_allergiess desc, number_of_careplans desc
)
select * from risk_pred_data
configタグ内のmaterializedでは、モデルをtableとして扱うとしています。
tagsはモデルにタグをつけることで、テスト実行時に指定したtagのモデルのみを実行可能です。
Previewします。
 idと患者ごとにアレルギーと治療計画の数がカウントされていることが確認できます。
idと患者ごとにアレルギーと治療計画の数がカウントされていることが確認できます。
Lineageタブをクリックしてリネージュを確認します。

ソースデータからstaging model、marts model、とモデルを作成してデータを整形できたことがわかります。
これからテストやジョブのデプロイ等、まだすべきことがあるのですが、ボリューミーになったため次回以降の記事で解説したいと思います。
参考記事
- Reference
- [dbt] データモデルの開発が便利になる「Package」を使ってみた(dbt_utils)
- ソースソース(source)機能を使おう
- dbtコマンドのチートシート
- Reference - tags
おわりに
本記事では、DatabricksのPartner Connectを使用してDatabricks上のデータをdbt上でデータ整形しました。
次回の記事では、今回作成したモデルを用いたテストとジョブのデプロイについて解説したいと思います。
今後もDatabricksに関連した検証内容を投稿していきたいと思いますので、またご覧になっていただければと思います。
私たちはDatabricksを用いたデータ分析基盤の導入から内製化支援まで幅広く支援をしております。
もしご興味がある方は、お問い合わせ頂ければ幸いです。
また、一緒に働いていただける仲間も募集中です!
APCにご興味がある方の連絡をお待ちしております。